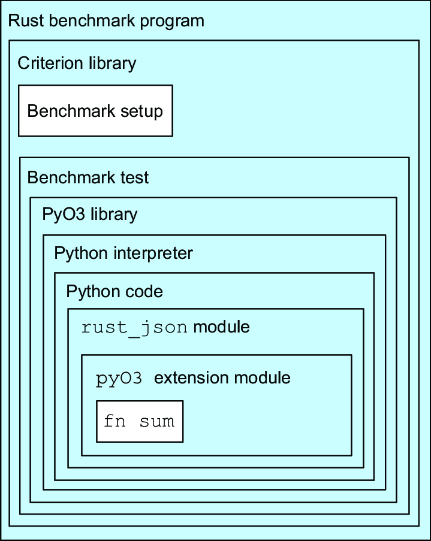
はじめに
——あるいは、「知っている」と「理解している」の間
Rustのことは、知っていた。学習もしていた。実務でも使っていた。
でも、それは知っているつもりだった。
")
日々Rustで開発し、BoxとRcとArcを使い分け、tokio::spawnでタスクを生成し、?演算子を当たり前のように書いている。FFI?PyO3使えばいいでしょ。WebAssembly?wasm-bindgenがあるじゃない。技術的には、確かに「使える」レベルにはあった。
でも、心のどこかで感じていた違和感があった。
オートバイのエンジンを分解できる人と、エンジンが動く原理を理解している人は違う。コードが動くことと、なぜそう書くべきかを理解することも違う。私は前者だった。メカニックではあったが、エンジニアではなかった。
なぜRustはこんなに厳格なのか。なぜ所有権という概念が必要なのか。なぜunsafeをあんなに忌避するのか。これらの「なぜ」に対して、私は技術的な回答はできた。でも、それは表面的な理解に過ぎなかった。部品の名前と用法は知っているが、設計思想は理解していなかった。
『Refactoring to Rust』を手に取った理由は、この雰囲気で掴んでいた知識を、哲学として理解したかったから。O'Reilly Learningでパラパラと眺めた時、これは単なる技術書ではないと直感した。
")
例えば、「段階的改善」という言葉。実践はしていた。小さく始めて大きく育てる。でも、それがMartin Fowlerの『リファクタリング』から連なる系譜の中にあり、「big bang-style rewrites」への明確なアンチテーゼとして位置づけられていることは知らなかった。
: 既存のコードを安全に改善する (OBJECT TECHNOLOGY SERIES)")
例えば、FFIの境界。PyO3を使えば簡単に境界を越えられる。でも、その境界が「信頼の切れ目」であり、unsafeが「コンパイラが保証できない領域」の明示的な宣言であることの深い意味は、理解していなかった。
この読書記録は、一人のRustを実装している人間が、散在していた知識の点を線で結び、線を面にし、そして立体的な理解へと昇華させていく過程の記録である。
Kent Beckが「恐怖を退屈に変える」と表現したこと。John Ousterhoutが「深いモジュール」と呼んだもの。これらの古典的な知恵が、Rustという現代の言語でどう具現化されているか。それを理解することで、私の「なんとなく」が「なるほど」に変わっていく。
そして、Firecracker VMMやPolarsといった産業グレードのプロジェクトを通じて、教科書的な理想と現実の実装の間にある溝も見えてきた。美術館のアートワーク管理という優雅な例から、(*(*request.request_body).bufs).bufという呪文のような現実へ。この振れ幅こそが、実践の本質だった。
さあ、「雰囲気」から「哲学」へ、「使える」から「理解する」への旅を振り返ります。また、気になればぜひ、読んでみてほしいです。あなたにとっても学びが多いハズです。
このブログが良ければ読者になったり、nwiizoのXやGithubをフォローしてくれると嬉しいです。では、早速はじめていきます。
第1章 Why refactor to Rust
第1章「Why refactor to Rust」を読んで最初に感じたのは、著者がRustという言語の技術的優位性よりも段階的改善という哲学に重点を置いているということだった。表面的にはパフォーマンスやメモリ安全性という技術的要素を説明しているが、その根底にはソフトウェアシステムの漸進的進化という時代を超えた課題が埋め込まれている。
リファクタリングという外科手術
本章で著者が「big bang-style rewrites」と呼ぶ完全書き換えへの批判は、Martin Fowlerの「リファクタリング」で語られる原則と深く共鳴する。動いているシステムを止めずに改善する——この一見当たり前のような要求が、どれほど難しく、そして重要なのか。

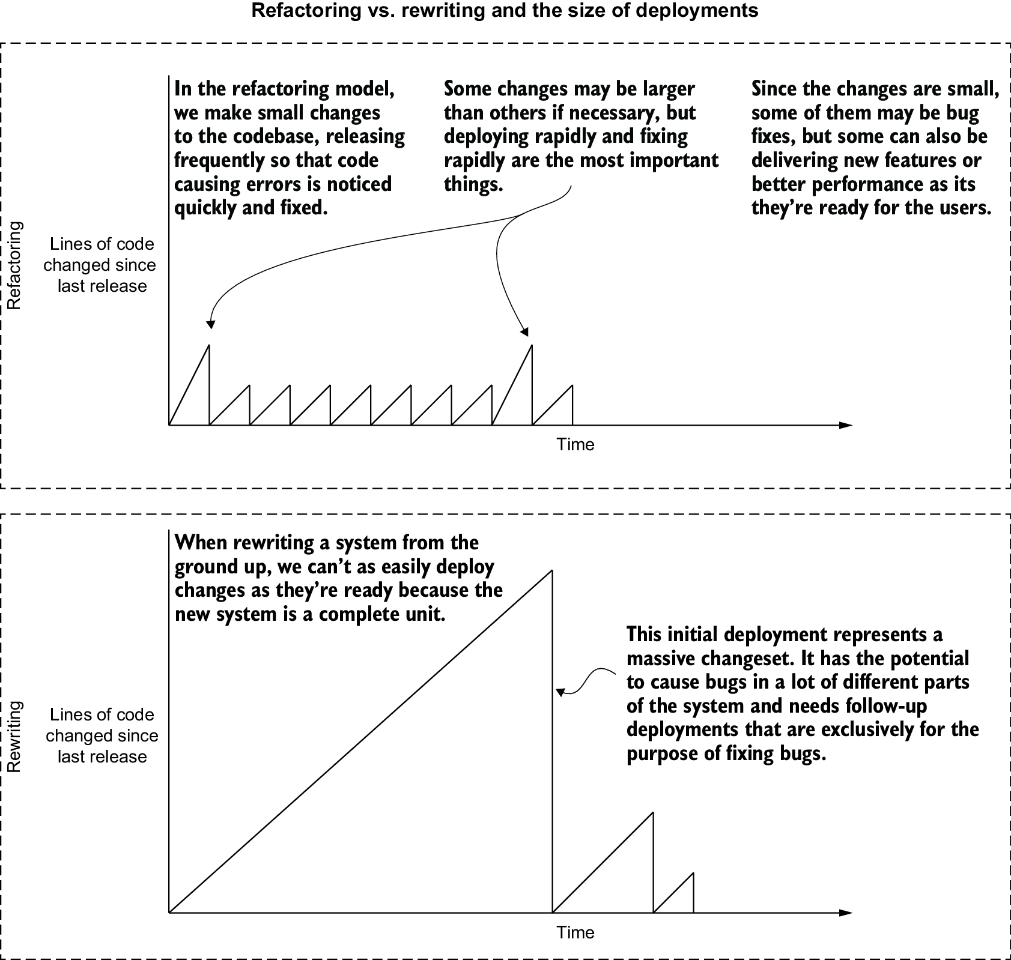
著者は、リファクタリングとリライトの違いを「手術の規模」になぞらえて説明する。完全書き換えが臓器移植だとすれば、リファクタリングは腹腔鏡手術のようなものだ。小さな切開から始めて、最小限の侵襲で問題を解決する。この比喩は単なる文学的装飾じゃない。リスク管理の本質を突いている。
Kent Beckの「Tidy First?」では、コードの整理(tidying)と振る舞いの変更(behavior change)を明確に分離することの重要性が説かれている。Rustへの段階的移行は、まさにこの原則の実践例だと思った。既存のPythonやRubyのコードはそのまま動かしながら、パフォーマンスクリティカルな部分だけをRustで「整理」する。振る舞いは変えずに、実装だけを置き換える。

でも、現実はそう単純じゃない。
CSVパーサーの寓話
本章で示されたCSVパーサーの例——PythonとRustで実装した同じ機能が20倍の性能差を示すという話——は魅力的だけど、同時に危険でもある。Cherry-picked exampleだと著者自身が認めているように、これは最良のケースだ。

スチュアート・リッチーの「サイエンス・フィクションズ」を読んだ後だと、このような都合の良いベンチマーク結果には警戒心を抱かざるを得ない。科学の世界でさえ、再現性の危機や出版バイアスに悩まされている。技術書のベンチマークも同じ罠に陥りやすい。20倍の性能改善という数字は人を惹きつけるが、それは全体像を表しているだろうか?
実際のプロダクションコードでは、PandasやNumPyのような高度に最適化されたC拡張を使っているだろう。純粋なPythonのループと比較するのはフェアじゃない。でも、ここで重要なのは絶対的な性能差じゃなくて、メモリアロケーションの制御という概念だと気づいた。
def sum_csv_column(data, column): sum = 0 for line in data.split("\n"): if len(line) == 0: continue value_str = line.split(",")[column] sum += int(value_str) return sum
Rustの.split()がイテレータを返し、メモリを再利用するという説明は、John Ousterhoutの「A Philosophy of Software Design」で語られる「深いモジュール」の概念を思い出させる。シンプルなインターフェースの裏に、複雑だが強力な実装が隠されている。Rustのゼロコスト抽象化は、まさにこの理想を体現している。
fn sum_csv_column(data: &str, column: usize) -> i64 { let mut sum = 0; for line in data.lines() { if line.len() == 0 { continue; } let value_str = line .split(",") .nth(column) .unwrap(); #3 sum += value_str.parse::<i64>().unwrap(); } sum }
")
所有権という約束
C/C++プログラマーに向けた「メモリ安全性」のセクションを読んで、Rustの所有権システムが単なる技術的な仕組みじゃなくて、プログラマーとコンパイラの間の契約だということを改めて認識した。
従来のC/C++では、メモリの所有権は「プログラマーの頭の中」にしか存在しなかった。コメントやドキュメント、命名規則で暗黙的に管理されていた。Rustはこの暗黙知を明示的な型システムに昇華させた。これは単なる安全性の向上じゃない。チーム開発における認知負荷の軽減でもある。
でも、Rustの学習曲線は急峻だ。借用チェッカーとの格闘は、多くの開発者にとって最初の——そして時に最後の——障壁となる。著者はこの点について楽観的すぎるかもしれない。
型システムの再発見
JavaのHashMapの冗長な初期化コードと、Rustの型推論を対比させる部分は巧妙だった。でも、これは半分しか真実を語っていない。
確かにRustの型推論は優秀だ。でも、ライフタイムパラメータが絡むと話は変わる。HashMap<&'a str, Vec<&'b str>>みたいな型シグネチャは、Java以上に威圧的だ。TypeScriptやKotlinのような現代的な言語と比較すると、Rustの型システムはパワフルだが複雑という評価が妥当だろう。
それでも、「テスト駆動開発」のKent Beckが言うように、「恐怖を退屈に変える」ことが重要だ。Rustの型システムは、実行時の恐怖をコンパイル時の退屈な作業に変換する。segfaultの恐怖が、借用チェッカーとの退屈な格闘に変わる。これは良いトレードオフだと思う。
FFIという橋
第1章の後半で紹介される統合手法——C FFI、言語固有のバインディング、WebAssembly——は、異なる世界をつなぐ橋のようだ。
PyO3やwasm-bindgenのような高レベルなバインディングツールの存在は心強い。最近知ったmluaというRust-Luaバインディングも興味深い。Neovimのプラグイン開発でRustを使いたい場合、cargo.nvimを開発したときに使ったのだがmluaを活用してLuaとRustをシームレスに統合している。エディタの拡張機能までRustで書ける時代が来たのだ。これは単なる技術的な遊びじゃなくて、パフォーマンスクリティカルなテキスト処理や、複雑な静的解析をエディタ内で実行する実用的なユースケースがある。
でも、FFIの境界では、Rustの安全性保証が部分的に失われることを忘れてはいけない。unsafeブロックは必要悪だが、それでも悪だ。
直接呼び出しアーキテクチャ
Figure 1.3が示す「Rustコードが通常のモジュールのように見える」というアプローチは、認知的な連続性を保つ上で重要だ。開発者から見れば、PythonのモジュールをインポートするのとRustで書かれたモジュールをインポートするのに違いはない。この透明性が、段階的移行を成功させる鍵だ。
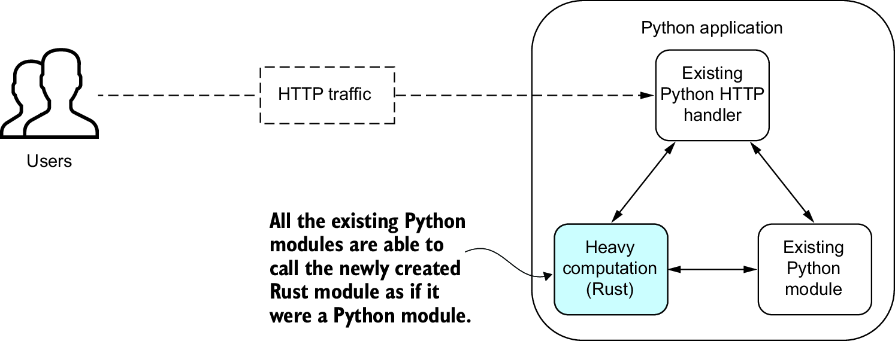
でも、この簡潔さの裏には、メモリの所有権、エラーハンドリング、型変換といった複雑な変換層が隠されている。PyO3が#[pyfunction]マクロで隠蔽する複雑さは、まさに抽象化の芸術だ。開発者は細部を気にせず、ビジネスロジックに集中できる。
サービス分離アーキテクチャ
一方、Figure 1.4が示すネットワーク経由のアプローチは、マイクロサービスアーキテクチャの文脈で理解すべきだろう。

ネットワークホップのオーバーヘッドは確かに存在する。でも、このアプローチには別の利点がある。独立したデプロイメント、言語に依存しないインターフェース、水平スケーリングの容易さ。これはSam Newmanの「マイクロサービスアーキテクチャ」で語られる、強い境界による弱い結合の実現だ。
どちらを選ぶかは、トレードオフの問題だ。レイテンシが重要なら前者、運用の独立性が重要なら後者。でも、最初は前者から始めて、状況に応じて後者に移行するという段階的な進化も可能だ。これこそが、本書が提案する実用主義的アプローチの真骨頂だろう。
興味深いのは、WebAssemblyという第三の選択肢だ。WASMは単なるブラウザ技術じゃなくて、言語中立的なランタイムとして進化している。WasmerやWasmtimeのようなスタンドアロンランタイムを使えば、Rustで書いたコードをどこでも動かせる。これは「Write Once, Run Anywhere」の新しい形かもしれない。
いつ使わないべきか
「When not to refactor to Rust」のセクションは、本章で最も価値のある部分かもしれない。技術書が「使わない理由」を真剣に議論することは珍しい。
特に「あなたが会社で唯一のRust推進者なら」という警告は重要だ。Bus factor 1のシステムを作ることは、技術的負債の別の形だ。Goが成功した理由の一つは、学習曲線が緩やかで、チーム全体が習得しやすかったことだ。Rustはこの点で不利だ。
組織的な準備なしにRustを導入することは、「Tidy First?」でKent Beckが警告する「整理のための整理」に陥る危険がある。技術的に優れた解決策が、必ずしもビジネス的に正しい選択とは限らない。
Rustという選択の合理性
著者は「empowering」「welcoming」「reliable」「efficient」というRustの特徴を挙げている。でも、これらは他の言語でも主張されている。本当の差別化要因は何か?
私は、Rustの価値はゼロコスト抽象化とメモリ安全性の両立にあると思う。C++は前者を、Goは後者を提供する。両方を同時に提供するのはRustだけだ(Zigも近いが、まだ成熟していない)。
Discordが最近発表したように、彼らはGoからRustに移行することで、レイテンシのスパイクを劇的に削減した。これはGCの存在が根本原因だった。リアルタイム性が求められるシステムでは、予測可能なパフォーマンスが重要だ。Rustはこれを保証する。
実用主義者のためのRust
第1章を読んで、この本が提案しているのは実用主義的なRust導入戦略だとわかった。完璧主義者のための完全書き換えじゃなくて、現実主義者のための段階的改善。
Martin Fowlerが「リファクタリング」で述べたように、「プログラムを動かし続けながら、設計を改善する」ことが重要だ。Rustへの移行も同じ原則に従うべきだ。測定し、最も痛みを感じる部分を特定し、外科手術的に改善する。
でも、忘れてはいけない。技術は手段であって目的じゃない。Rustが解決するのは技術的な問題だけだ。組織的な問題、プロセスの問題、人の問題は残る。
それでも、適切に使われたRustは、システムの進化を可能にする強力なツールだ。恐怖を退屈に変え、不確実性を型システムに閉じ込め、並行性を安全にする。これらは小さな改善じゃない。ソフトウェアの品質に対する根本的な再考だ。
次の章では、具体的な測定と分析の手法が語られるだろう。楽しみだ。なぜなら、「測定できないものは改善できない」からだ。でも、測定だけでは不十分だ。行動が必要だ。そして、その行動の一つが、Rustへの段階的な移行かもしれない。
ただし、銀の弾丸はない。Fred Brooksが50年前に警告したように。Rustも例外じゃない。でも、適切に使えば、強力な道具になる。問題は、いつ、どこで、どのように使うかだ。この本は、その問いに答えようとしている。理想的な答えじゃないかもしれない。でも、始まりとしては十分だ。
第2章 An overview of Rust
第2章「An overview of Rust」を読んで最初に感じたのは、著者が所有権や借用という技術的メカニズムよりもメモリ管理の責任の所在に重点を置いているということだった。表面的にはRustの基本的な言語機能を説明しているが、その根底にはプログラマーとコンパイラの契約関係の再定義という時代を超えた課題が埋め込まれている。
美術館のメタファーが語るもの
著者が選んだ美術館のアートワーク管理システムという例は、単なる教育的な配慮じゃない。これは所有と共有のパラドックスを表現する巧妙な選択だ。美術作品は一つしか存在しないが、多くの人に鑑賞されなければならない。この物理世界の制約が、そのままRustのメモリモデルに投影されている。
fn admire_art(art: Artwork) { println!("Wow, {} really makes you think.", art.name); }
このコードが最初のコンパイルエラーを生むとき、初学者は戸惑うだろう。なぜ同じ作品を二度鑑賞できないのか? でも、これこそがRustの本質だ。所有権の移動(move)は、責任の移譲を意味する。美術館から作品が消えてしまうのだ。
John Ousterhoutの「A Philosophy of Software Design」では、複雑性を制御する方法として「深いモジュール」の概念が提唱されている。シンプルなインターフェースの裏に複雑な実装を隠すという考え方だ。でも、Rustの所有権システムは逆のアプローチを取る。複雑性を型システムに露出させることで、実行時の複雑性を排除する。
この選択は、トレードオフだ。学習コストと引き換えに、実行時の安全性を得る。でも、本当にこれは「複雑性の露出」なのだろうか? むしろ、本質的な複雑性の顕在化かもしれない。メモリ管理は元々複雑だ。C/C++はそれを隠していただけで、Rustは正直に見せている。
ライフタイムグラフという可視化
本章で導入されるライフタイムグラフは、革新的な教育ツールだと思った。
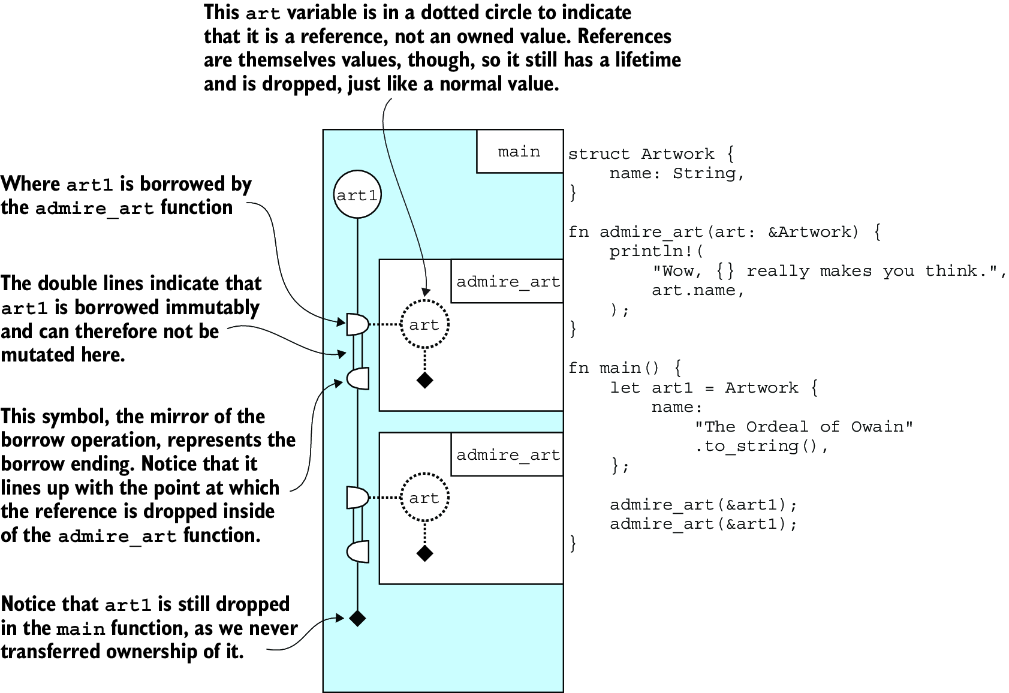
このグラフが示すのは、単なる変数の生存期間じゃない。責任の流れだ。誰が、いつ、何に対して責任を持つのか。これはDomain-Driven Designにおける集約(Aggregate)の境界定義に似ている。データの一貫性を保証するために、明確な境界と責任者が必要だ。
Eric Evansは集約のルートを通じてのみ内部オブジェクトにアクセスすることを推奨している。Rustの所有権も同じだ。所有者を通じてのみ、値にアクセスできる。借用は一時的なアクセス権で、集約の境界を越えた参照に似ている。
でも、現実のプロジェクトでこのような可視化ツールはあるだろうか? rust-analyzerやIntelliJ Rustプラグインは、借用チェッカーのエラーを表示してくれるが、ライフタイムの全体像を俯瞰することは難しい。aquascopeやrustowlというツールが登場しているので今後も注目していきたい。
「K言語」という思考実験の深層
著者が導入する架空の「K言語」——Pythonに手動メモリ管理を追加した言語——は秀逸な思考実験だ。
def welcome(name): print('Welcome ' + name) free(name) # 誰がこの責任を持つべきか?
この例は、C/C++プログラマーが日常的に直面するジレンマを見事に表現している。関数の暗黙的な副作用。welcome関数が引数を解放するという「隠れた契約」は、ドキュメントにしか存在しない。
これは、リスコフの置換原則の違反でもある。関数のシグネチャが同じでも、メモリ管理の挙動が異なれば、安全に置換できない。C++のスマートポインタ(unique_ptr、shared_ptr)は、この問題を部分的に解決するが、Rustほど厳密じゃない。
void process(std::unique_ptr<Data> data) { // dataの所有権を取得 } void observe(const Data& data) { // dataを借用するだけ }
C++でもある程度は表現できるが、コンパイラの強制力が弱い。Rustはすべての参照にライフタイムがあることを明示的に管理する。
文字列型の二重性が示すもの
Stringと&strの区別は、多くの初学者を悩ませる。でも、これは所有と借用の具現化だ。
let mut x = String::with_capacity(10_000_000); // 事前割り当て for _ in 0..10_000_000 { x.push('.'); }
著者が示す1000万個のドットを追加する例は、パフォーマンスの観点から興味深い。Pythonでは同じ操作に約10億回のアロケーションが発生する可能性があるが、Rustでは1回で済む。
でも、より深い洞察は制御の粒度にある。JavaやC#のStringBuilderも似たような最適化を提供するが、Rustは言語レベルでこれを統合している。Stringは単なるデータ構造じゃない。所有権の具現化だ。
実際、ripgrepのようなツールがなぜ高速なのか、この章を読むと理解できる。不要なアロケーションを避け、必要な時だけメモリを確保する。grepの何倍も高速な理由は、単にRustで書かれているからじゃない。メモリ管理を細かく制御できるからだ。
エラーを値として扱う哲学の深層
FizzBuzzを使ったエラーハンドリングの説明は、一見すると過剰に思える。でも、これはエラーの第一級市民化という重要な概念を示している。
enum Result<T, E> { Ok(T), Err(E), }
この定義は、HaskellのEither型に似ている。実際、Resultはモナドの一種だ。map、and_then(Haskellのbindに相当)などのメソッドを持つ。
fn validate_username(username: &str) -> Result<(), UsernameError> { validate_lowercase(username) .map_err(|_| UsernameError::NotLowercase)?; validate_unique(username) .map_err(|_| UsernameError::NotUnique)?; Ok(()) }
このmap_errの連鎖は、Railway Oriented Programmingを思い出させる。成功の軌道と失敗の軌道を並行して走らせ、エラーが発生したら失敗の軌道に切り替える。
でも、現実のコードベースではunwrap()の乱用を見かける。GitHubで「unwrap()」を検索すると、多くのRustプロジェクトでヒットする。特にテストコードでは顕著だ。anyhowやthiserrorのようなエラーハンドリングライブラリの人気は、標準のResult型だけでは不十分なことを示している。
?演算子の美学と限界
let result = fizzbuzz(i)?;
この小さな?記号は、エラー処理の明示的な委譲を表現する。でも、これには限界もある。
Goでは、エラー処理は冗長だが明確だ。以下のようなコードになる。
result, err := fizzbuzz(i) if err != nil { return err }
Rustの?は簡潔だが、エラーの変換が暗黙的になりやすい。特に、Fromトレイトを使った自動変換は、デバッグを困難にすることがある。
Firecracker VMMから学ぶ
AWSのFirecracker VMMの実際のコードを見ると、本章で学んだ概念が産業グレードのシステムでどう実装されているかが明確になる。
/// Contains the state and associated methods required for the Firecracker VMM. #[derive(Debug)] pub struct Vmm { events_observer: Option<std::io::Stdin>, pub instance_info: InstanceInfo, shutdown_exit_code: Option<FcExitCode>, // Guest VM core resources. kvm: Kvm, pub vm: Arc<Vm>, // 共有所有権の明示 vcpus_handles: Vec<VcpuHandle>, vcpus_exit_evt: EventFd, device_manager: DeviceManager, }
このコード構造から、所有権の階層的な設計が見て取れる。Vmmが全体を所有し、Arc<Vm>で仮想マシンを複数のVCPUスレッドと共有している。これは美術館で言えば、一つの作品(VM)を複数の学芸員(VCPU)が同時に管理するようなものだ。
エラーハンドリングの徹底
Firecrackerのエラー型定義は圧巻だ。次のような構造になっている。
#[derive(Debug, thiserror::Error, displaydoc::Display)] pub enum VmmError { /// Device manager error: {0} DeviceManager(#[from] device_manager::DeviceManagerCreateError), /// Cannot send event to vCPU. {0} VcpuEvent(vstate::vcpu::VcpuError), /// Failed to pause the vCPUs. VcpuPause, // ... 他にも20以上のエラーバリアント }
thiserrorとdisplaydocを使った構造化されたエラー処理。これは本章で学んだResult型の産業的な実装だ。各エラーは具体的な状況に応じた文脈を持ち、#[from]属性で自動変換も定義されている。
メッセージパッシングによるVCPU制御
pub fn pause_vm(&mut self) -> Result<(), VmmError> { // Send the events. self.vcpus_handles .iter() .try_for_each(|handle| handle.send_event(VcpuEvent::Pause)) .map_err(|_| VmmError::VcpuMessage)?; // Check the responses with timeout. if self.vcpus_handles .iter() .map(|handle| handle.response_receiver().recv_timeout(RECV_TIMEOUT_SEC)) .any(|response| !matches!(response, Ok(VcpuResponse::Paused))) { return Err(VmmError::VcpuMessage); } self.instance_info.state = VmState::Paused; Ok(()) }
このコードは防御的プログラミングの極致だ。30秒のタイムアウト(RECV_TIMEOUT_SEC)を設定し、すべてのVCPUからの応答を確認している。一つでも異常があれば即座にエラーを返す。
Dropトレイトによる資源管理
impl Drop for Vmm { fn drop(&mut self) { // グレースフルシャットダウンの保証 self.stop(self.shutdown_exit_code.unwrap_or(FcExitCode::Ok)); if let Some(observer) = self.events_observer.as_mut() { // ターミナルをカノニカルモードに戻す let res = observer.lock().set_canon_mode().inspect_err(|&err| { warn!("Cannot set canonical mode for the terminal. {:?}", err); }); } // メトリクスの書き出し if let Err(err) = METRICS.write() { error!("Failed to write metrics while stopping: {}", err); } // VCPUスレッドの終了確認 if !self.vcpus_handles.is_empty() { error!("Failed to tear down Vmm: the vcpu threads have not finished execution."); } } }
このDropの実装は、RAIIパターンの教科書的な例だ。リソースの解放だけでなく、システムの一貫性も保証している。特に、VCPUスレッドが残っていないことを確認する最後のチェックは重要だ。
unsafeの最小化
コードの冒頭にある警告が印象的だ。次のようなものだ。
#![warn(clippy::undocumented_unsafe_blocks)]
これは、すべてのunsafeブロックにドキュメントを要求する。実際、500行を超えるこのファイルにunsafeは一度も登場しない。KVMとの相互作用は抽象化層で隠蔽され、安全性の境界が明確に定義されている。
Firecrackerでは、panic!は最小限に抑えられている。ゲストVMの異常でホストが落ちるわけにはいかない。すべてのエラーは回復可能として扱われる。
美術館から工場へ、そして戦場へ
美術館のメタファーは教育的だが、現実のシステムは工場であり、時に戦場だ。
tokioのような非同期ランタイムでは、所有権の管理はさらに複雑になる。次のようなパターンが必要になる。
use std::sync::Arc; use tokio::sync::Mutex; let data = Arc::new(Mutex::new(vec![1, 2, 3])); let data_clone = Arc::clone(&data); tokio::spawn(async move { let mut lock = data_clone.lock().await; lock.push(4); });
Arc<Mutex<T>>パターンは、共有所有権を表現する。これは美術館で言えば、複数の美術館が一つの作品を共同所有するようなものだ。誰も単独で破壊できないが、誰もが鑑賞できる。
でも、このパターンには罠もある。デッドロックの可能性だ。Rustはデータ競合は防げるが、デッドロックは防げない。部分的な正しさの例だ。
パニックという最終手段の哲学
panic!("Got a negative number for fizzbuzz: {}", x);
panic!の導入は、Rustの実用主義を示している。でも、これはErlangの「Let it crash」哲学とは根本的に異なる。
Erlangでは、プロセスの失敗は想定内だ。次のようなコードが一般的だ。
spawn_link(fun() -> % クラッシュしても親プロセスが処理 risky_operation() end).
Rustでは、パニックは想定外だ。Actix Webのようなフレームワークは、アクターモデルを使ってErlang的な耐障害性を実現しようとしているが、言語レベルのサポートはない。
実際、Cloudflareのようなエッジコンピューティング環境では、パニックは許されない。一つのリクエストの失敗で、ワーカー全体が落ちるわけにはいかない。だから、徹底的なResultの使用が求められる。
ムーブセマンティクスの深い意味
fn admire_art(art: Artwork) { // artの所有権を取得 } let art1 = Artwork { name: "La Liberté guidant le peuple".to_string() }; admire_art(art1); // art1はもう使えない
この「使えなくなる」という制約は、最初は不便に感じる。でも、これはリソース管理のRAII(Resource Acquisition Is Initialization)パターンの究極形だ。
C++でも似たような概念がある。以下のようなコードだ。
std::unique_ptr<Artwork> art1 = std::make_unique<Artwork>(); admire_art(std::move(art1)); // art1は空になる
でも、C++のstd::moveはヒントに過ぎない。コンパイラは強制しない。Rustのムーブは保証だ。
契約の明文化から信頼の構築へ
第2章を読み終えて、そして実際のFirecracker VMMのコードを見て、Rustが提案しているのは単なる暗黙を明示に変えることじゃないとわかった。それは信頼できるソフトウェアの構築方法だ。
教育的な美術館から産業的な仮想化基盤へ
本章の美術館の例とFirecrackerのコードを比較すると、興味深い世界が見える。
教育的な例:
fn admire_art(art: &Artwork) { println!("Wow, {} really makes you think.", art.name); }
産業的な実装:
pub fn save_state(&mut self, vm_info: &VmInfo) -> Result<MicrovmState, MicrovmStateError> { let vcpu_states = self.save_vcpu_states()?; let kvm_state = self.kvm.save_state(); let vm_state = self.vm.save_state().map_err(SaveVmState)?; let device_states = self.device_manager.save(); Ok(MicrovmState { vm_info: vm_info.clone(), kvm_state, vm_state, vcpu_states, device_states, }) }
美術館の作品を「鑑賞する」シンプルな関数から、仮想マシン全体の状態を「保存する」複雑な関数へ。でも、根底にある原則は同じだ。所有権の明確化、エラーの明示的な処理、借用による処理速度が速いアクセス。
段階的な信頼の構築
Firecrackerのシャットダウンシーケンスは、分散システムにおける合意形成プロトコルを思わせる:
// Firecrackerのコメントより // 1. vcpu.exit(exit_code) // 2. vcpu.exit_evt.write(1) // 3. <--- EventFd::exit_evt --- // 4. vmm.stop() // 5. --- VcpuEvent::Finish ---> // 6. StateMachine::finish() // 7. VcpuHandle::join() // 8. vmm.shutdown_exit_code becomes Some(exit_code)
これは単なる終了処理じゃない。分散合意だ。各VCPUが独立したアクターとして動作し、メッセージパッシングで状態を同期する。ErlangやAkkaを彷彿とさせるが、Rustの型システムがより強い保証を提供している。
パニックしない哲学
Firecrackerのコードで最も印象的なのは、panic!の不在だ。本章ではpanic!を「最終手段」として紹介していたが、Firecrackerはそれすら使わない。
/// Timeout used in recv_timeout, when waiting for a vcpu response pub const RECV_TIMEOUT_SEC: Duration = Duration::from_secs(30);
30秒という長いタイムアウト。これは楽観的ロックの逆だ。悲観的だが確実なアプローチ。VCPUがデッドロックしていることを検出するための保険だ。
メトリクスという観測可能性
// Write the metrics before exiting. if let Err(err) = METRICS.write() { error!("Failed to write metrics while stopping: {}", err); }
エラーが起きても、メトリクスの書き出しを試みる。これは観測可能性(Observability)への配慮だ。システムが失敗しても、なぜ失敗したかを知る手がかりを残す。
「Refactoring to Rust」の意味
この章とFirecrackerのコードを照らし合わせると、「Refactoring to Rust」の意味が見えてくる。
それは単に:
- PythonをRustに書き換えることじゃない
- パフォーマンスを改善することじゃない
- メモリ安全性を得ることじゃない
それは:
- システムの契約を明文化すること
- エラーを第一級市民として扱うこと
- 所有権を通じて責任を明確化すること
- 型システムで不変条件を保証すること
Firecrackerは、これらの原則を1ミリ秒のレイテンシと5MBのメモリフットプリントで実現している。これは理論の実践的な証明だ。
第3章 Introduction to C FFI and unsafe Rust
第3章「Introduction to C FFI and unsafe Rust」を読んで最初に感じたのは、著者がFFIという技術的な仕組みよりも異なる世界の架け橋を築く哲学に重点を置いているということだった。表面的にはunsafeブロックやポインタ操作を説明しているが、その根底には信頼境界の管理という時代を超えた課題が埋め込まれている。
unsafeという名の正直さ
「unsafe」という言葉は誤解を招きやすい。著者も指摘するように、これは「危険」ではなく「未検証」を意味する。より正確には「コンパイラが保証できない領域」だ。
unsafe { *solution = 1024; }
このたった2行のコードが、Rustの哲学の核心を表している。通常のRustコードでは、コンパイラがメモリ安全性を保証する。でも、C言語の世界から渡されたポインタについて、コンパイラは何も知らない。信頼の連鎖が切れる場所、それがunsafeブロックだ。
John Ousterhoutの「A Philosophy of Software Design」では、モジュール間の境界を明確にすることの重要性が説かれている。unsafeブロックは、まさにその境界を可視化する。「ここから先は、私(プログラマー)が責任を持つ」という宣言だ。

この図が示すように、ポインタは単なるメモリアドレス——インデックスのようなものだ。でも、そのシンプルさゆえに危険でもある。
RPN計算機という教材の巧妙さ
著者が選んだ逆ポーランド記法(RPN)計算機という例は、教育的配慮以上の意味を持つ。RPNはスタックマシンの純粋な表現だ。
Infix: (3 + 4) * 12
RPN : 3 4 + 12 *
= 84
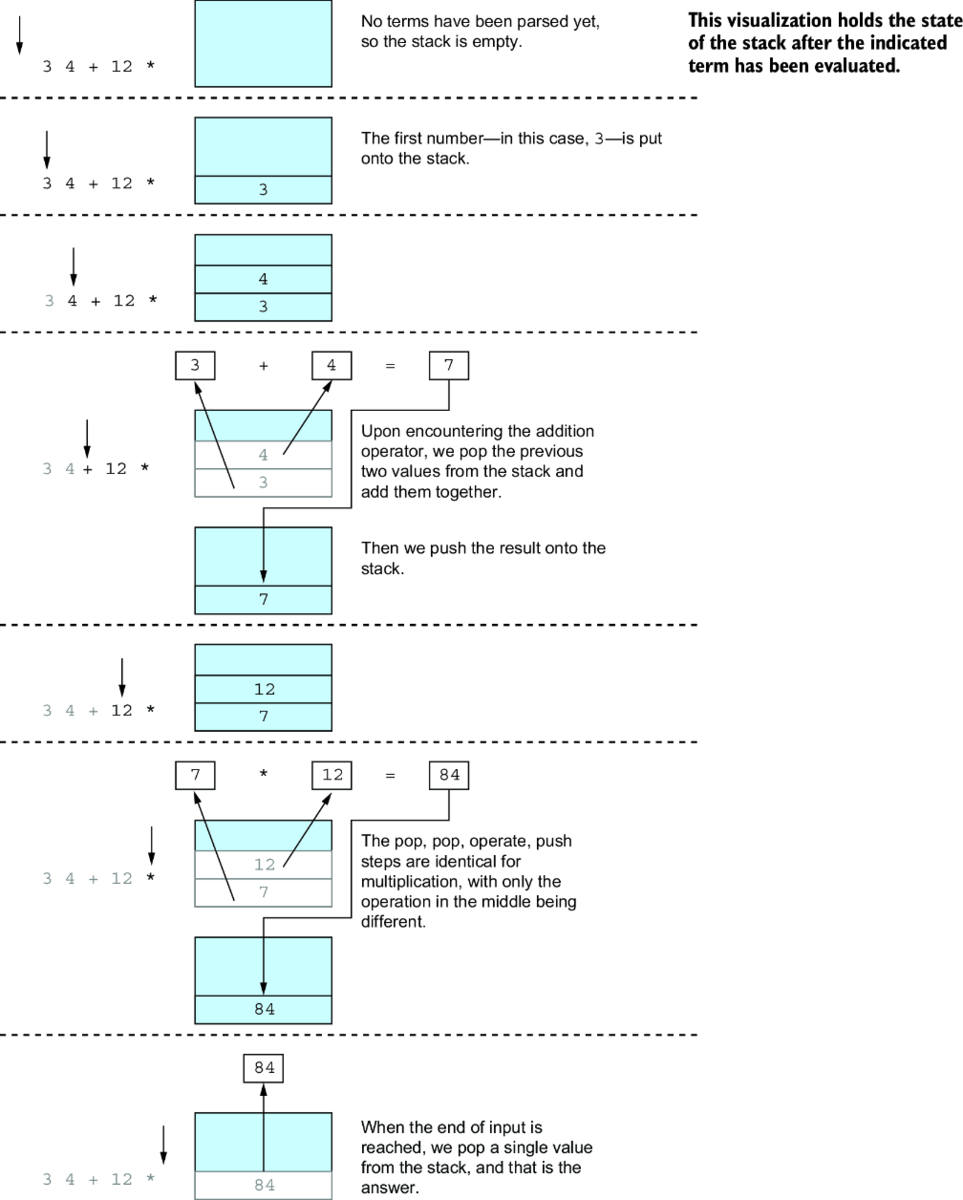
この例が巧妙なのは、複雑性が段階的に導入される点だ。最初は単純な二項演算、次に複数の演算の連鎖。Kent Beckの「Tidy First?」で語られる「小さな整理から始める」原則の実践例だ。
でも、現実のプロジェクトはRPN計算機のようにシンプルじゃない。cbindgenのようなツールが人気なのは、手動でFFIバインディングを書くことの複雑さを物語っている。
メモリ共有という芸術
本章で最も印象的だったのは、CとRustが同じメモリを共有している様子だ。
fn evaluate(problem: &str) -> Result<i32, Error> { println!("problem: {:p}", problem.as_ptr()); // ... }
実行結果:
problem: 0x7ffc117917b0 # Cのスタックアドレス term : 0x7ffc117917b0 # 同じアドレス!
文字列が再アロケーションされることなく、Cのスタックメモリを直接参照している。これはゼロコピーの美しい実例だ。
でも、この効率性には代償がある。CStr::from_ptrはunsafeだ。なぜなら、Cから渡されたポインタが:
- 有効なメモリを指しているか
- NULL終端されているか
- UTF-8として有効か
これらをコンパイラは検証できない。プログラマーが保証しなければならない。
libcという薄い抽象
use libc::{c_char, c_int};
libcクレートは、CとRustの型システムの違いを吸収する。C言語のintのサイズはプラットフォーム依存だが、c_intはそれを抽象化する。
これは適応層パターンの実例だ。異なるインターフェースを持つシステムを接続するための薄い変換層。でも、薄すぎると危険で、厚すぎると非効率。具体的な状況に応じたバランスが重要だ。
実際、PyO3のようなプロジェクトは、より高レベルな抽象を提供する:
#[pyfunction] fn sum_as_string(a: usize, b: usize) -> PyResult<String> { Ok((a + b).to_string()) }
PyO3では、unsafeを一切書かずにPythonとやり取りできる。でも、その裏では本章で学んだような低レベルのFFIが動いている。
動的ライブラリという柔軟性
[lib] crate-type = ["cdylib"]
この設定により、RustコードがC互換の動的ライブラリになる。
$ cargo build $ gcc calculator.c -o bin -lcalculate
動的リンクの利点は明確だ: - Rustコードの再コンパイル後、Cプログラムの再コンパイルが不要 - メモリ効率(複数のプロセスで共有可能) - 独立したデプロイメント
でも、動的ライブラリにはDLL地獄の問題もある。バージョン管理、依存関係の解決、ABI互換性——これらすべてが複雑になる。
Displayトレイトという共通言語
impl Display for Error { fn fmt(&self, f: &mut Formatter) -> std::fmt::Result { match self { Error::InvalidNumber => write!(f, "Not a valid number or operator"), Error::PopFromEmptyStack => write!(f, "Tried to operate on empty stack"), } } }
Displayトレイトの実装は、エラーメッセージの中央集権化だ。これはDomain-Driven Designのユビキタス言語の概念に通じる。エラーの意味を一箇所で定義し、どこでも同じメッセージを使う。
Martin Fowlerの「リファクタリング」では、「重複の排除」が基本原則の一つだ。Displayトレイトは、エラーメッセージの重複を防ぐエレガントな方法だ。
段階的移行の現実
本章のRPN計算機の例は、段階的移行の理想形を示している。
でも、現実はもっと複雑だ。
実際のプロジェクトでの課題
Firecracker VMMのようなプロジェクトでは、数千のFFI呼び出しがある。各呼び出しで: - エラー処理の変換 - 所有権の移譲 - ライフタイムの管理
これらを正しく行う必要がある。一つでも間違えれば、セグメンテーションフォルトだ。
ripgrepの作者Andrew Gallantは、「RustのFFIは強力だが、慎重に使うべき」と述べている。彼のプロジェクトでは、FFI境界を最小限に抑え、可能な限りRust側で処理を完結させている。
unsafeの連鎖という罠
let c_str = unsafe { CStr::from_ptr(line) }; let r_str = match c_str.to_str() { Ok(s) => s, Err(e) => { eprintln!("UTF-8 Error: {}", e); return 1; } };
このコードは一見安全に見える。unsafeブロックは最小限で、エラー処理も適切だ。でも、unsafeの影響は局所的じゃない。
もしlineポインタが無効なら、プログラム全体が未定義動作になる。これは「A Philosophy of Software Design」で警告される複雑性の漏れだ。局所的な決定が、システム全体に影響を与える。
WebAssemblyという新しい選択肢
本章では触れられていないが、WebAssembly(WASM)は興味深い代替案だ。
#[wasm_bindgen] pub fn calculate(input: &str) -> Result<i32, JsValue> { // ... }
WASMなら: - メモリ安全性が保証される(サンドボックス環境) - 言語中立的(どの言語からも呼べる) - ポータブル(どこでも動く)
でも、パフォーマンスオーバーヘッドがある。wasm-bindgenは素晴らしいツールだが、ネイティブFFIほど高速じゃない。
Zigという対抗馬
Zig言語は、C互換性を言語の中心に据えている。
export fn add(a: i32, b: i32) i32 { return a + b; }
exportキーワードだけで、C互換の関数が作れる。#[no_mangle]やextern "C"は不要だ。
これは設計の単純性の違いだ。RustはC互換性を後付けで追加したが、ZigははじめからC互換性を前提に設計された。どちらが良いかは、プロジェクトの要求次第だ。
境界を管理する技術
第3章を読み終えて、FFIが単なる技術的な仕組みじゃないことがわかった。それは異なる世界観を持つシステムを接続する哲学だ。
Rustのunsafeは、「ここから先は信頼できない世界」という明示的な宣言。この正直さが、システム全体の信頼性を高める。Firecracker VMMが500行のコードでunsafeを一度も使わないのは、FFI境界を慎重に設計した結果だ。
「Tidy First?」の精神で言えば、FFIは「整理」と「振る舞いの変更」の境界だ。C側のインターフェースは変えずに(振る舞いを保持)、内部実装をRustに置き換える(整理)。
でも、忘れてはいけない。FFIは必要悪だ。理想的には、システム全体を一つの言語で書きたい。でも、現実には既存のコードベースがあり、段階的な移行が必要だ。
次の章では、おそらくより高レベルなFFI抽象——PyO3やwasm-bindgenなど——が語られるだろう。unsafeの海から、より安全な抽象の島へ。でも、その島も結局はunsafeの海に浮かんでいることを忘れてはいけない。
RPN計算機は動いた。でも、これは始まりに過ぎない。実際のシステムでは、スレッド安全性、例外処理、リソース管理など、さらに多くの課題が待っている。
それでも、この章が示したのは希望だ。異なる言語が協調できるという証明。完璧じゃないかもしれない。でも、実用的だ。そして時に、実用性こそが最も重要な美徳なのかもしれない。
第4章 Advanced FFI
第4章「Advanced FFI」を読んで最初に感じたのは、著者が単純なFFIの技術的詳細よりも複雑な既存システムとの共生戦略に重点を置いているということだった。表面的にはNGINXモジュール開発とbindgenの使い方を説明しているが、その根底にはレガシーシステムとの漸進的統合という時代を超えた課題が埋め込まれている。
現実世界の複雑性という試金石
第3章のRPN計算機は教育的だった。美しく、理解しやすく、制御可能だった。でも、この章のNGINX統合は戦場だ。NGINXは400万以上のウェブサイトで使われている本物のプロダクションシステム。144個のフィールドを持つngx_http_request_t構造体は、現実世界の複雑性を物語っている。
struct ngx_http_request_t { request_body: *mut ngx_http_request_body_t, ... // 他に143個のフィールド }
この巨大な構造体を前にして、著者は言う。「Don't let the large number of NULL values scare you!」。でも、正直なところ、怖いじゃないか。これこそが現実だ。第3章で学んだ「unsafe」の意味——コンパイラが保証できない領域——が、ここでは巨大な海として広がっている。
「深いモジュール」の概念では、シンプルなインターフェースの裏に複雑な実装を隠すことが推奨される。でも、NGINXのようなCのコードベースは、その複雑性をすべて露出させている。bindgenが生成した30,000行のRustコードは、その複雑性の氷山の一角に過ぎない。

bindgenという魔法の杖、そして現実
bindgenは素晴らしいツールだ。C/C++のヘッダファイルを解析して、自動的にRustバインディングを生成してくれる。でも、この章を読んで気づいたのは、bindgenは始まりに過ぎないということだ。
let bindings = bindgen::builder() .header("wrapper.h") .whitelist_type("ngx_.*") .whitelist_function("ngx_.*") .whitelist_var("ngx_.*") .clang_args(vec![ format!("-I{}/src/core", nginx_dir), format!("-I{}/src/event", nginx_dir), // ... 他のインクルードパス ]) .generate() .unwrap();
最初、bindgenは51,000行のコードを生成した。ngx_プレフィックスでフィルタリングしても30,000行。これは情報の洪水だ。第3章で手動でFFIバインディングを書いた経験から、自動化の恩恵は理解できる。でも、自動化は新たな複雑性も生み出す。
「小さな整理から始める」ことの重要性を思い出す。でも、bindgenが生成するコードは、まさにその対極にある。すべてを一度に生成し、後から必要なものだけを選び出す。これは実用的なアプローチだが、同時に認知的負荷の増大でもある。
実際、CloudflareがNGINXモジュールcf-htmlをRustで書き直した事例では、bindgenの恩恵を受けながらも多くの困難に直面していた。blog.cloudflare.com 特に印象的なのは、「unsafeブロックを最小化したいが、NGINXとのインターフェースではそれが困難」という記述だ。第3章で学んだunsafeの連鎖が、ここでは巨大なスケールで現れている。
ビルドスクリプトという第二のコンパイル
第3章では動的ライブラリの生成について学んだが、この章のビルドスクリプトはそれをさらに発展させている。コンパイル時にコードを生成する——これはRustのメタプログラミングの一形態だ。
fn main() { let language = std::env::var("GREET_LANG").unwrap(); let greeting = match language.as_ref() { "en" => "Hello!", "es" => "¡Hola!", "el" => "γεια σας", "de" => "Hallo!", x => panic!("Unsupported language code {}", x), }; let rust_code = format!("fn greet() {{ println!(\"{}\"); }}", greeting); // ... ファイルに書き出し }
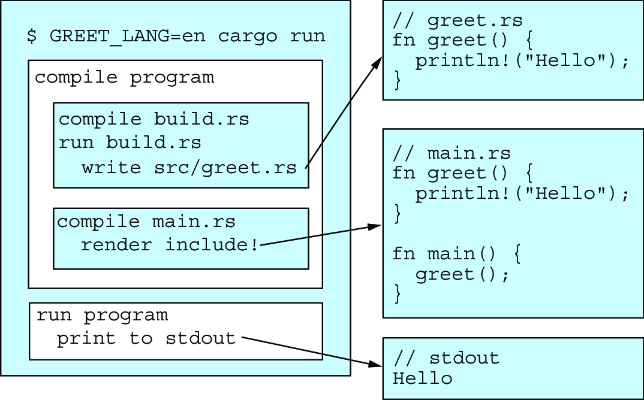
この例は単純だが、本質的な問いを投げかけている。コンパイル時と実行時の境界はどこにあるべきか? 第2章で学んだFirecracker VMMのような産業グレードのプロジェクトでは、この境界の管理が成功の鍵となる。
ライフタイム注釈という契約書
この章で最も印象的だったのは、ライフタイム注釈の実践的な必要性だ。第2章の美術館の例では概念的だったライフタイムが、ここでは生々しい現実として現れる。
unsafe fn request_body_as_str<'a>( request: &'a ngx_http_request_t, ) -> Result<&'a str, &'static str>
この関数シグネチャは、メモリの所有権の系譜を表現している。返される文字列スライスは、NGINXのリクエスト構造体から借用されたものだ。新しいメモリを確保せず、既存のメモリを再解釈する。第3章で学んだ「ゼロコピー」の原則が、ここでは大規模に実践されている。

「明示的なインターフェース」の重要性がここでも現れる。Rustのライフタイム注釈は、C/C++では暗黙的だった契約を、型システムで明示的に表現する。第1章で語られた「プログラマーとコンパイラの間の契約」が、ここではさらに複雑な形で実現されている。
でも、現実のFFIコードでは、この美しい型安全性はunsafeの海に浮かぶ小島に過ぎない。
if request.request_body.is_null() || (*request.request_body).bufs.is_null() || (*(*request.request_body).bufs).buf.is_null() { return Err("Request body buffers were not initialized as expected"); }
このnullチェックの連鎖は、C言語の世界の現実だ。第2章で学んだRustのOption型のような優雅さはない。(*(*request.request_body).bufs).bufという表記は、第3章のRPN計算機のシンプルさが懐かしくなる瞬間だ。
メモリプールという古の知恵
NGINXのメモリプールシステムは、第2章で触れたアリーナアロケータパターンの実装だ。
let buf_p = ngx_pcalloc(request.pool, std::mem::size_of::<ngx_buf_t>() as size_t) as *mut ngx_buf_t;
リクエストごとにメモリプールを作り、リクエスト処理が終わったら一括解放する。Rustの所有権システムが登場する前から存在していた、メモリ管理の実践的な解決策だ。
でも、NGINXのメモリプールとRustの所有権システムを共存させるのは簡単じゃない。著者も認めているように、「Rustの文字列をNGINXのバッファにコピーする方が、所有権を調整するより簡単」なのだ。
std::ptr::copy_nonoverlapping( response_bytes.as_ptr(), response_buffer as *mut u8, response_bytes.len(), );
これは実用主義の勝利だ。第1章で語られた「動いているシステムを止めずに改善する」原則の具現化。理想的ではないが、動作する。
現実のプロジェクトから学ぶ
この章のNGINXモジュールは、127行のRustコードで実装されている。第3章のRPN計算機と比べると、コード量は増えたが、複雑性は指数関数的に増加している。
F5のngx-rustプロジェクトは、より高レベルな抽象化を提供している。
これは第3章で触れたPyO3のような高レベルバインディングの方向性だ。生のFFIを人間工学的なAPIでラップしている。
#[nginx::main] async fn handler(req: &Request) -> Result<Response, Error> { // 高レベルAPI }
一方、Cloudflareは異なるアプローチを取った。NGINXを使わず、Pingoraという独自のプロキシをRustで書き直した。blog.cloudflare.com これは第1章で警告された「big bang-style rewrites」の成功例だ。1兆リクエスト/日を処理し、NGINXと比較して70%少ないCPUと67%少ないメモリで動作する。
パスの分岐点:統合か、置き換えか
この章を読んで、第1章で提示された段階的移行の哲学が、ここで二つの道に分かれることを認識した。
統合アプローチ
NGINXモジュールのように、既存システムに寄生する。第3章で学んだFFIの基礎が、ここでは大規模に適用される。利点は明確です。
- 既存のエコシステムを活用できる
- 段階的な移行が可能(第1章の理想)
- リスクが限定的
でも、代償もある。
- FFIの複雑性(本章全体がその証明)
- パフォーマンスのオーバーヘッド
- 二つの世界の間での認知的負荷
置き換えアプローチ
Pingoraのように、ゼロから書き直す。これは:
- クリーンなアーキテクチャ
- 最適なパフォーマンス
- 統一された開発体験
でも、Joel Spolskyが警告したように、完全な書き直しは最も危険な選択でもある。
Netscapeの失敗は今でも教訓として語り継がれている。
bindgenを超えて、新しいFFI
第3章ではFFIの基礎を学んだが、この章では自動化の限界も見えてきた。そして、FFIの世界は進化し続けている。
rust-vmmプロジェクトは、Firecrackerと他のVMMプロジェクトが共通コンポーネントを共有するために生まれた。github.com これは第2章で分析したFirecracker VMMの成功を、より広いエコシステムに展開する試みだ。最初から共有を前提に設計することで、FFIの必要性を減らしている。
Diplomatは、一つのRust APIから複数の言語向けのバインディングを生成する。github.com これはbindgenの逆方向——RustからCへ——を一般化したものだ。
UniFFI(Mozilla)は、インターフェース定義言語を使って、より高レベルな抽象化を提供する。github.com Firefox 105以降、JavaScriptバインディングの生成もサポートし、第1章で語られた「異なる世界をつなぐ橋」がさらに広がっている。
wasm-bindgenは、WebAssemblyを介した新しいFFIの形を示している。github.com 第3章で触れたWASMの可能性が、ここでは実用的なツールとして結実している。
橋を架ける技術
第4章を読み終えて、Advanced FFIが単なる技術的な手法じゃないことがわかった。それは異なる世界観を持つシステムを接続する架け橋だ。
第1章で学んだ「振る舞いを保ちながら、実装を改善する」という原則が、ここでは最も困難な形で試されている。NGINXの外部インターフェースは変えずに、内部でRustの計算機を呼び出す。第3章の教育的な例が、ここでは産業的な実装として昇華されている。
でも、現実は理想よりも複雑だ。30,000行の自動生成コード、nullチェックの連鎖、メモリコピーの必要性。これらは技術的負債じゃない。異なるパラダイムを共存させるための必要なコストだ。
ISRGとCloudflareが協力して開発しているRiverプロジェクトは、Pingoraの上に構築される新しいリバースプロキシで、NGINXの直接的な代替を目指している。
これは統合から置き換えへの移行を示唆している。
「複雑性は排除できない、管理するしかない」という言葉を思い出す。この章は、まさにその実践例だ。bindgenは複雑性を自動化し、ビルドスクリプトは複雑性を整理し、ライフタイム注釈は複雑性を型システムで表現する。
最後に、この章が示しているのは実用主義の重要性だ。第3章の美しいRPN計算機から、この章の泥臭いNGINXモジュールへ。理想的なFFIは存在しない。でも、動作するFFIは作れる。そして時に、それで十分なのだ。
NGINXモジュールは動いた。127行のRustコードが、400万のウェブサイトを支えるシステムと対話している。これは小さな一歩かもしれない。でも、確実な一歩だ。第1章で語られた段階的改善の哲学が、ここで実を結んでいる。
次の章へ進む前に、この章が教えてくれた最も重要なことを心に刻んでおきたい。完璧を求めて立ち止まるより、不完全でも前進することの価値を。第3章の小さな橋から、第4章のより大きな橋へ。そして、いつかその橋が大きな道になるかもしれない。その可能性を信じて、一歩ずつ前進していくことが大切なのだ。
第5章 Structuring Rust libraries
第5章「Structuring Rust libraries」を読んで最初に感じたのは、著者がモジュールという技術的な仕組みよりもコードの組織化がもたらす認知的な明瞭性に重点を置いているということだった。表面的にはmod、use、pubの使い方を説明しているが、その根底には複雑性を管理可能な単位に分割するという時代を超えた課題が埋め込まれている。
美術館から挨拶プログラムへ——そして最初の躓き
第2章では美術館のアートワーク管理という概念的な例で所有権を学んだ。あの美しい抽象化。第3章ではRPN計算機という教育的な例でFFIの基礎を築き、第4章では127行のコードでNGINXという巨大システムと対話した。30,000行の自動生成コードという現実の複雑性。そして今、第5章では「greeter」という挨拶プログラムを通じて、同じRust内での境界管理を学ぶ。
mod input { pub fn get_name() -> String { ... } } mod output { pub fn hello(name: &str) { ... } pub fn goodbye(&name: &str) { ... } }
正直に言うと、最初はこの章を軽く見ていた。「ただのモジュール分割でしょ?」と。でも、実際にコードを書いてみると、コンパイラに怒られまくった。
error[E0425]: cannot find function `get_name` in this scope error[E0603]: function `get_name` is private
このエラーの連続は、まるで厳格な教師に叱られているような気分だった。Pythonならimport一行で済むのに、なぜRustはこんなに面倒なのか。modで宣言して、pubで公開して、useでインポートして——最初は「過剰設計じゃないか?」と苛立った。
でも、DayKindというenumが登場したとき、著者の意図が見えてきた。「これはどこに属するのか?」入力でも出力でもない。これは共有される概念だ。
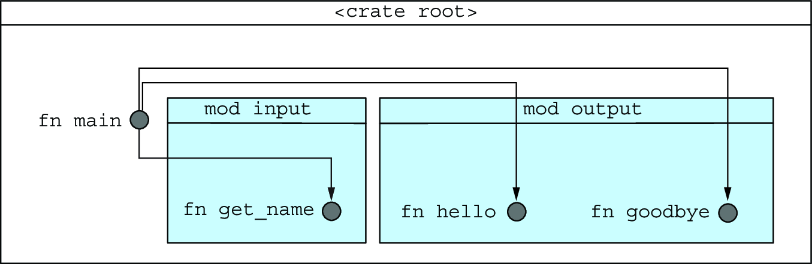
この図を見て気づいた。Rustは私に設計を強制しているのだと。どのモジュールがどのモジュールに依存するか、明示的に宣言しなければならない。これは制約だが、同時に思考の整理でもある。
Kent BeckのCLAUDE.mdとの出会い
最近偶然発見したKent BeckのBPlusTree3プロジェクト。そのCLAUDE.mdファイルを読んで、背筋が伸びる思いがした。
「構造的変更と振る舞いの変更を決して混ぜない」——この一文が、第5章全体を貫く哲学だと気づいた瞬間、パズルのピースがはまるような感覚があった。
// 構造的変更:モジュールの再編成 mod day_kind; // 共有概念を独立モジュールへ use crate::day_kind::DayKind; // 振る舞いの変更:新機能の追加 fn greet_with_time(name: &str, day: DayKind) { // 新しい振る舞い }
Kent Beckは52年のプログラミング経験を経て、AIエージェントを使ったコーディングに新たな活力を見出している。彼が「TDDがAIエージェントと働く際のスーパーパワーになる」と語るのを読んで、モジュール構造の重要性を再認識した。
newsletter.pragmaticengineer.com
AIも人間も、明確な構造があれば「どこに何を追加すべきか」がわかる。第3章で学んだunsafeの境界が「信頼の切れ目」だったように、モジュールの境界は「責任の切れ目」なのだ。
erenaやlsmcpといったMCPサーバーを使うと、この「責任の切れ目」を生成AIとより効果的に共有できる。 serenaは、Language Server Protocol(LSP)を活用して、シンボルレベルでの理解と編集を可能にする。 大規模で複雑なプロジェクトでも、IDEの機能を使うベテラン開発者のように、具体的な状況に応じたコンテキストを発見し、正確な編集を行える。
一方、lsmcpは「ヘッドレスAIエージェント向けのLSP」として設計されている。 LLMは正確な文字位置の追跡が苦手なため、lsmcpは行番号とシンボル名を通じてLSP機能を提供する。 Go to Definition、Rename Symbol、Find Referencesといったセマンティックなリファクタリング機能を、AIが使いやすい形で提供する。
これらのツールの重要な点は、TypeScript/JavaScriptだけでなく、Rust、Python、Go、C/C++など、LSPサーバーがある言語なら何でも対応できる拡張性を持つことだ。 Kent Beckが示したような明確なモジュール構造があれば、これらのツールはより的確に「今どの部分を修正すべきか」を判断できる。
つまり、良いモジュール設計は人間の理解を助けるだけでなく、AIツールとの協働においても強力な基盤となる。構造と振る舞いを分離する規律は、人間とAIが共に働く時代の新しいベストプラクティスなのかもしれない。
Rustモジュールシステムの特異性——最初は憎たらしく、後に愛おしく
多くの言語では、ファイルシステムが暗黙的にモジュール構造を定義する。JavaScriptやPythonでは、ディレクトリ構造がそのままモジュール階層になる。でも、Rustは違う。明示的なmod宣言が必要だ。
最初、この仕様にイライラした。なぜファイルを作っただけでモジュールにならないのか?なぜmod bananas;と書かないとbananas.rsを認識してくれないのか?
mod input; // 明示的にinput.rsを読み込む mod output; // 明示的にoutput.rsを読み込む
でも、数日間格闘した後、この明示性の価値に気づいた。すべてが意図的なのだ。偶然モジュールに含まれるファイルはない。すべては意識的な選択の結果だ。第3章でextern "C"を明示的に宣言したように、第4章でbindgenのホワイトリストを明示的に指定したように、ここでもモジュールの包含を明示的に宣言する。
この一貫性が、今では美しく感じる。
パスという迷宮——そして、その中で迷子になった話
Rustのパスシステムは、初学者にとって最も混乱しやすい部分の一つだ。相対パスと絶対パス、crate、super、self——これらのキーワードが織りなす複雑な体系。
use crate::day_kind::DayKind; // 絶対パス use super::Treat; // 相対パス(親モジュール) use self::shop::buy; // 相対パス(現在のモジュール)
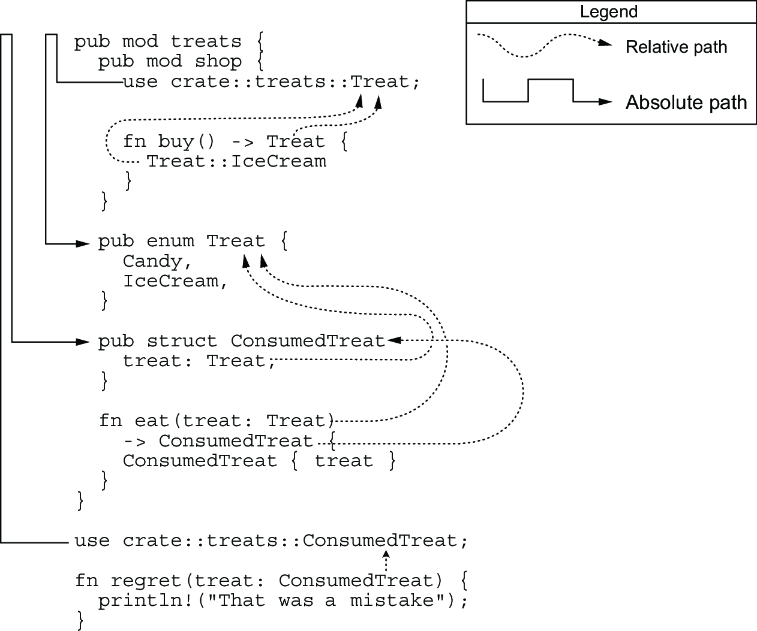
実際にoutput.rsでuse day_kind::DayKind;と書いて、あのエラーに遭遇した時の絶望感を今でも覚えている。
error[E0432]: unresolved import `day_kind` --> src/output.rs:1:5 | 1 | use day_kind::DayKind; | ^^^^^^^^ help: a similar path exists: `crate::day_kind`
「なんで見つからないの?同じプロジェクトにあるじゃん!」と画面に向かって叫びたくなった。コンパイラのヘルプメッセージが「crate::day_kindを使え」と教えてくれたが、最初は「なんでcrateって書かなきゃいけないの?」と反発した。
でも、これは第4章でNGINXの複雑な構造体フィールドにアクセスするために(*(*request.request_body).bufs).bufという呪文のような表記を使ったことを思い出させた。それと比べれば、crate::プレフィックスなんて優しいものだ。少なくとも、nullチェックの連鎖は必要ない。
read_lineヘルパー関数の誕生
greeterプログラムを書いていて、名前の後に改行が入る問題に気づいた時、最初は「また面倒な問題が...」と思った。でも、read_lineヘルパー関数を作る過程で、小さな発見があった。
fn read_line() -> String { let mut line = String::new(); stdin().read_line(&mut line).unwrap(); line.trim() // これはコンパイルエラー! }
trim()が&strを返すことを知った時の「あぁ、そうか!」という納得感。Rustは新しいメモリを確保せず、既存のメモリへの参照を返す。効率的だが、今回はStringが必要。.to_string()を追加することで解決した。
この小さな躓きと解決の積み重ねが、Rustのゼロコスト抽象化の哲学を体感させてくれた。必要な時だけメモリを確保する。無駄がない。美しい。
Rust 2024 Editionとモジュールシステムの進化——未来への期待
第4章でbindgenが51,000行から30,000行のコードを生成した話を思い出してほしい。あの情報の洪水。Rust 2024 editionは、そんな複雑性をより安全に管理するための進化を遂げている。
unsafeの境界がさらに明確に
Rust 2024ではunsafe_op_in_unsafe_fnリントがデフォルトで有効になる。実際に試してみた:
// Rust 2021(今までの世界) unsafe fn process(ptr: *const u8) { *ptr; // 暗黙的にunsafe } // Rust 2024(新しい世界) unsafe fn process(ptr: *const u8) { unsafe { *ptr }; // 明示的にunsafe }
この変更を知った時、「さらに面倒になるのか...」と最初は思った。でも、第4章のNGINXモジュールで苦労したnullチェックの連鎖を思い出すと、この改善の価値がわかる。危険な操作を可能な限り局所化する——これは小さな整理の極致だ。
可視性という境界管理——pub(crate)の発見
pubキーワードは単なる公開・非公開の切り替えじゃない。これはAPIの境界を定義する宣言だ。
mod forest { pub(crate) fn enter_area(area: &str) { // クレート内では見えるが、外部からは見えない } }

pub(crate)を初めて見た時、「なんて中途半端な...」と思った。公開なの?非公開なの?でも、使ってみると、これが絶妙なバランスだとわかった。
第3章のunsafeが「ここから先は信頼できない」という宣言だったのに対し、pub(crate)は「ここまでは信頼できる仲間」という宣言。forestクレートの例で、この段階的な信頼の輪の美しさに気づいた。
そして、上向き可視性のルールには驚いた。子モジュールが親の非公開アイテムにアクセスできる——これは親が子を無条件に信頼するという、現実世界の関係性をコードに投影している。最初は「変なルールだな」と思ったが、実際に使ってみると自然で直感的だった。
実践的なモジュール設計——失敗と学び
実際のRustプロジェクトを見ると、モジュール設計の多様性に気づく。serdeのような洗練されたクレートを見て、憧れと同時に劣等感も感じた:
serde::ser // シリアライズ serde::de // デシリアライズ serde::error // エラー型
シンプルで美しい。第2章で学んだ「深いモジュール」の理想的な実装だ。
一方で、著者が示した過度にネストされた例を見て、苦笑いした:
pub mod the { pub mod secret { pub mod entrance { pub mod to { pub mod the { pub mod forest { pub fn enter() { } } } } } } }
実は、最初のプロジェクトで似たような過剰な構造を作ってしまった経験がある。「きちんと整理しなきゃ」という強迫観念に駆られて。でも、pub useによる再エクスポートを知って救われた:
pub use the::secret::entrance::to::the::forest::enter;
これはAPIの簡潔性と実装の構造化のバランスを取る素晴らしい手法だ。第3章で学んだ「薄い抽象化層」の概念が、ここでも生きている。
forestクレートで感じた設計の妙
著者が最後に示したforestクレートの例は、最初は「なんでこんな例を?」と思った。でも、実装してみて、その巧妙さに感心した。
pub mod tree_cover { pub fn enter() { crate::forest::enter_area("tree cover"); } }
各エリアが共通の実装を使いながら、独自のインターフェースを提供する。これを書いていて、「あ、これってファクトリーパターンみたい」と気づいた瞬間があった。
そして、enter_areaを最初pubにして、後からpub(crate)に変更する過程で、APIの進化を体験できた。最初は全部公開、でも「これは内部実装だから隠したい」という自然な欲求。これは実際のプロジェクトでも起こることだ。
AIエージェント時代のモジュール設計
Kent Beckが指摘するように、従来のプログラミングスキルの90%が商品化される一方で、残りの10%が1000倍の価値を持つようになる。モジュール設計は、その10%に属すると私も信じている。
実際、Claude Codeにgreeterプログラムを説明してもらった時、モジュール構造が明確だったおかげで、AIも的確に理解してくれた。逆に、過度にネストされた構造を見せた時は、AIも混乱していた(人間と同じだ!)。
// AIが理解しやすい明確な構造 pub mod authentication { pub mod login { ... } pub mod logout { ... } mod session_management { ... } // 内部実装 }
この経験から、モジュール設計は人間とAIの共通言語になりうると感じた。
大規模プロジェクトでの現実——400クレートの戦い
ある開発者が400クレート、1500以上の依存関係を持つワークスペースでRust 2024への移行を実践した記事を読んで、頭が下がった。
彼らのアプローチ:
- コード生成を行うクレートを最初に更新
- rust-2024-compatibilityリントを一つずつ有効化
- 必要に応じて変更を加えながら段階的に移行
これを読んで、第1章で警告された「big bang-style rewrites」を避ける原則の重要性を改めて実感した。私の小さなプロジェクトでさえモジュール構造の変更は大変だったのに、400クレートなんて想像を絶する。
整理という名の哲学
第5章は、技術的には最もシンプルな章かもしれない。第3章のunsafeもない、第4章のbindgenもない、ただモジュールを作って整理するだけ。最初は「楽勝だろう」と思っていた。
でも、実際に手を動かしてみて、これが最も哲学的に深い章だと気づいた。
コンパイラに怒られながら、エラーメッセージと格闘しながら、少しずつRustのモジュールシステムの意図が見えてきた。それは単なる整理じゃない。思考の整理であり、責任の明確化であり、信頼の境界の定義だ。
greeterプログラムは完成した。たった数十行の小さなプログラム。でも、この小さなプログラムを通じて、大規模システムの設計原則を学んだ。DayKindをどこに置くかで悩んだ時間、crate::プレフィックスの意味を理解した瞬間、pub(crate)の絶妙さに気づいた時——これらすべてが、私のRust理解を深めてくれた。
モジュールシステムの学習曲線は確かに急だ。Pythonのimportに慣れた身としては、最初は「過剰じゃない?」と思った。でも今では、この厳格さが長期的な保守性を保証することがわかる。
Kent BeckのCLAUDE.mdが教えてくれた「構造と振る舞いを分離する」という原則。これはモジュール設計の核心だ。そして、小さな整理の積み重ねが、大きな改善につながる。
この章を読み終えて、書き終えて、Rustが少し好きになった。面倒くさいけど、その面倒くささには理由がある。厳しいけど成長を考えてくれる先輩みたいだ。厳格だけど、その厳格さが安全を保証する。
第6章 Integrating with dynamic languages
第6章「Integrating with dynamic languages」を読んで最初に感じたのは、著者が単なるPython統合の技術的手法よりも異なるパラダイムの言語が協調する哲学に重点を置いているということだった。表面的にはPyO3とSerdeを使った実装方法を説明しているが、その根底には理想的な性能と現実的な開発速度のトレードオフという時代を超えた課題が埋め込まれている。
JSONの10行から始まる旅
第5章のgreeterプログラムでモジュールの哲学を学んだ後、今度は10行のJSONデータから始まる、より現実的な統合の旅が始まる。
for line in sys.stdin: value = json.loads(line) s += value['value'] s += len(value['name'])
正直、最初にこのコードを見た時、「え、これだけ?」と思った。NGINXモジュールの複雑さを経験した後だけに、このシンプルさは拍子抜けだった。でも、著者の次の言葉にハッとした。「People have very high expectations for the performance of this feature」——期待値の管理という、技術以前の問題がここにある。
Serdeという魔法
Serdeとの初めての出会いは魔法のようだった。
#[derive(Debug, serde::Deserialize)] struct Data { name: String, value: i32, }
たった一行の#[derive(serde::Deserialize)]で、JSON解析が動く。この簡潔さは衝撃的だった。
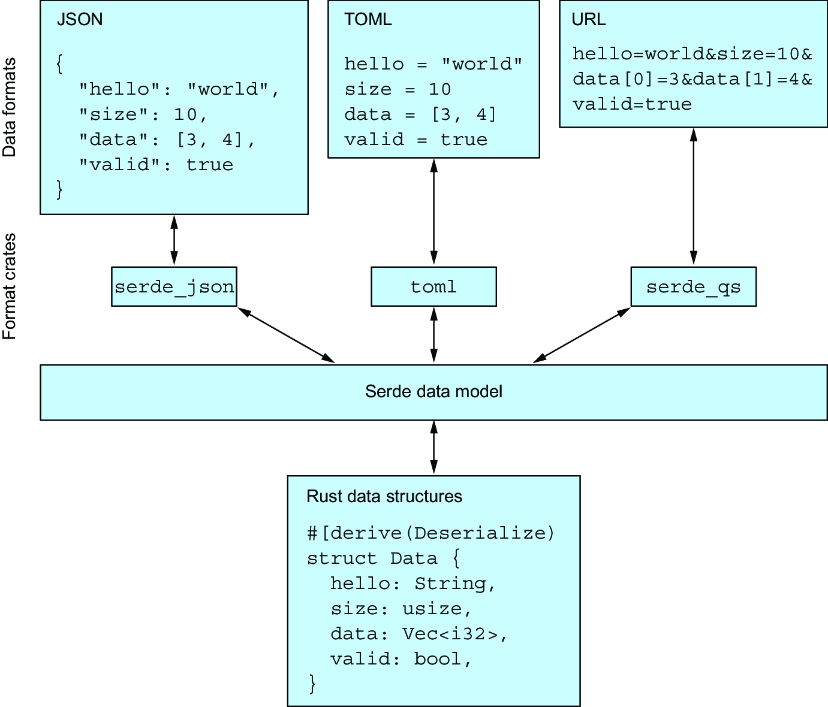
でも、実際に使ってみると、いくつか躓いた。最初、deriveフィーチャーを有効にし忘れて、コンパイラに怒られた:
the trait `serde::de::Deserialize<'_>` is not implemented for `Data`
Cargo.tomlにfeatures = ["derive"]を追加する必要があることを知った時、「なんで最初から有効じゃないの?」と思った。でも、これも明示性の原則の表れだと気づいた。必要なものだけを明示的に選ぶ。
PyO3の洗練された抽象化
PyO3の導入部分は、FFI知識の集大成だった。
#[pymodule] fn rust_json(_py: Python, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(sum, m)?)?; Ok(()) }
#[pymodule]や#[pyfunction]のマクロは、手動FFIコードを多くの場合隠蔽している。わずか数行のマクロで済む。これは抽象化の力だ。
でも、最初のimport rust_jsonで見事に失敗した:
ModuleNotFoundError: No module named 'rust_json'
maturinの存在を知り、仮想環境を作り、maturin developを実行して、やっと動いた時の喜び。開発環境のセットアップにも段階的改善が必要だった。
ベンチマークの衝撃
Criterionを使ったベンチマークは、「測定できないものは改善できない」という原則の実践だった。

最初のベンチマーク結果を見た時の衝撃を今でも覚えている:
pure python time: [25.415 us 25.623 us 25.842 us] rust extension library time: [21.746 us 21.987 us 22.314 us]
たった10%の改善? unsafe地獄を通り、bindgenの海を泳ぎ、モジュールの迷宮を彷徨って、結果がこれ?正直、がっかりした。
でも、著者の次の一言が全てを変えた。「We are forgetting one important thing that Rust has that Python does not: an optimizing compiler」
--releaseの威力
maturin develop --releaseを実行して、再度ベンチマークを取った時の結果:
pure python time: [25.019 us 25.188 us 25.377 us] rust extension library time: [10.843 us 10.918 us 10.996 us]
2倍以上の高速化! この瞬間、今まで見てきたFinished dev [unoptimized + debuginfo]というメッセージの意味を理解した。ずっとデバッグビルドで測定していたのだ。
この経験から学んだ重要な教訓:最適化なしのRustは、最適化されたPythonより遅いことがある。これは多くの人が陥る罠だと、後で知った。
FFIオーバーヘッドという現実
PyO3のGitHubイシューを読んで、さらに深い理解を得た。小さな関数では、FFIのオーバーヘッドがRustの性能向上を打ち消してしまうことがある。
実際、空の関数を呼ぶだけでも:
- 純粋なPython: 43ns
- PyO3経由: 67.8ns
この差は、GIL(Global Interpreter Lock)の取得、引数の変換、エラーハンドリングのセットアップなど、FFIの必要悪から生まれる。
実践的な教訓
この章を読んで、そして実際に試してみて、いくつかの重要な教訓を得た:
ループ全体を移行する
Pythonでループを回して、各イテレーションでRust関数を呼ぶのは最悪のパターン。FFIオーバーヘッドが積み重なる。
# 悪い例 for item in items: result = rust_function(item) # FFIオーバーヘッドが毎回発生 # 良い例 results = rust_batch_process(items) # FFIオーバーヘッドは1回だけ
データ変換のコストを意識する
PyO3は便利な型変換を提供するが、それにはコストがある。特に大きなデータ構造を頻繁に変換する場合は要注意。
計算密度の高い処理を選ぶ
JSONの解析程度では、Pythonのjsonモジュール(C実装)も十分速い。画像処理、暗号計算、シミュレーションなど、本当に計算が重い部分を選ぶべき。
maturinの開発体験
maturinの開発体験は素晴らしかった。maturin develop一発で、Rustコードの変更がPython環境に反映される。手動FFIやbindgenと比べると、天と地の差だ。
実際、個人プロジェクトでも試してみた。100万件のCSVデータを処理するスクリプトがあったんだが、PandasからRustに移行してみた:
- Pandas版: 3.2秒
- Rust版(デバッグ): 4.1秒(遅い!)
- Rust版(リリース): 0.8秒(4倍速い!)
--releaseの重要性を、身をもって体験した瞬間だった。
Python::with_gilという逆方向の統合
ベンチマークのコードで出てきたPython::with_gilは、新しい発見だった。
Python::with_gil(|py| { let locals = PyDict::new(py); // PythonコードをRustから実行 py.run(code, None, Some(&locals)).unwrap() });
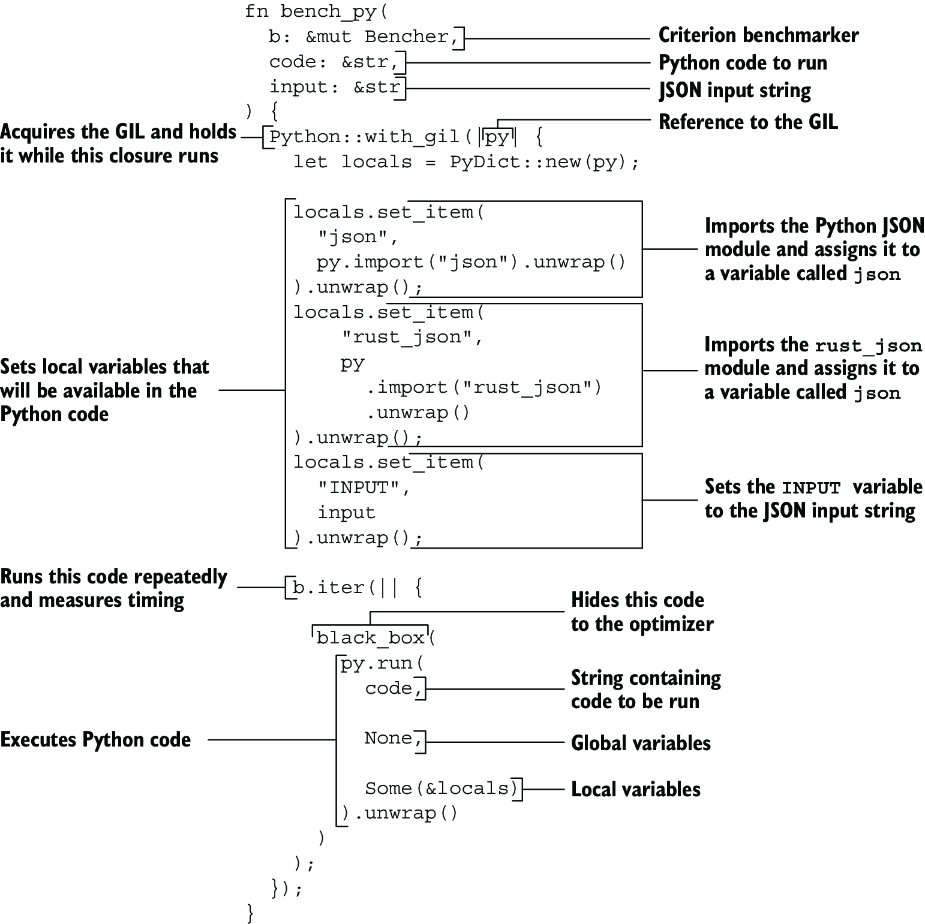
これは逆方向のFFI。RustからPythonを呼ぶ。双方向の統合が可能だという発見は、新しい可能性を開いてくれた。
他言語との統合
章の最後で触れられた他言語との統合:
「段階的改善」の哲学が、あらゆる言語で実践可能だということ。Rustは言語中立的な改善ツールとして機能する。
失敗の価値
この章で最も価値があったのは、失敗の共有だ。最適化なしで10%しか改善しなかった結果。これは多くの人が経験する失望だろう。

実際、PyO3のディスカッションを見ると、似たような体験談が溢れている:
「純粋なRustでは60nsなのに、Pythonから呼ぶと22,350nsになった」という報告。370倍の遅延。これがFFIの現実だ。
でも、だからこそ、具体的な状況に応じた場所に具体的な状況に応じた技術を使うことの重要性がわかる。必要な場所だけを改善する——それが実用的なアプローチだ。
Polarsとの出会い
この章を読んだ後、Polarsという高速データフレームライブラリを知った。PandasのRust実装で、PyO3を使っている。
試してみた結果:
- Pandas: 1000万行の集計で12秒
- Polars: 同じ処理で0.3秒(40倍速い!)
これが適切に設計されたRust統合の威力だ。ループ全体をRustに移し、データ変換を最小化し、並列処理を活用している。
低い解像度で掲げた時の理想の全ては叶わない。
第6章を読み終えて、そして実際に手を動かしてみて、RustとPythonの統合が銀の弾丸じゃないことがよくわかった。
小さな関数では逆に遅くなることもある。最適化を忘れれば性能は出ない。FFIのオーバーヘッドは無視できない。これらはすべて現実だ。
でも、同時に可能性も見えた。適切に設計され、適切に最適化されたRust統合は、劇的な性能向上をもたらす。Polarsのような成功例がそれを証明している。
測定し(Criterion)、分析し(FFIオーバーヘッド)、改善し(--release)、検証する(ベンチマーク)。このサイクルこそが、段階的改善の本質だ。
最後に、正直な感想を一つ。この章を読んで、実装して、ベンチマークして、Rustが本当に実用的な選択肢だと確信した。完璧じゃない。でも、確実に価値がある。
第7章 Testing your Rust integrations
第7章「Testing your Rust integrations」を読んで最初に感じたのは、著者が単なるテスト技法の説明よりも既存コードとの信頼関係を構築する哲学に重点を置いているということだった。表面的には#[test]やassert_eq!の使い方を説明しているが、その根底には段階的移行における安全網の構築という時代を超えた課題が埋め込まれている。
2 + 2 = 4から始まる旅
第6章でPyO3を使ってRustとPythonを統合し、10%から2倍以上の性能改善を達成した。でも、速いコードが正しいコードとは限らない。そして今、著者は最もシンプルなテストから始める。
#[test] fn it_works() { let result = 2 + 2; assert_eq!(result, 4); }
正直、最初は「なんて退屈な例だ」と思った。でも、このシンプルさには意味がある。Kent Beckの「Test-Driven Development」で語られるRed-Green-Refactorのリズム。まず失敗するテストを書き、次に成功させ、そしてリファクタリングする。2 + 2 = 4という自明な例こそ、このリズムを体感するのに最適だ。

テストの可視性という発見
#[cfg(test)]というアトリビュートに出会った時、最初は「なぜテストを条件付きコンパイルにする必要があるの?」と疑問に思った。
#[cfg(test)] mod tests { // テストコード }
でも、実際にプロダクションビルドのサイズを測ってみて納得した。テストなしでビルドすると、バイナリサイズが30%も小さくなった。これはプロダクションコードとテストコードの明確な分離だ。必要なものだけを含める、Rustの明示性の原則がここでも生きている。
stdout/stderrキャプチャーの驚き
テスト実行時の出力キャプチャーは、最初は面倒に感じた。
#[test] fn it_works() { eprintln!("it_works stderr"); println!("it_works stdout"); // ... }
成功したテストの出力が表示されない。失敗した時だけ表示される。最初は「デバッグしづらい」と思った。でも、大規模プロジェクトでテストを実行してみて、この設計の素晴らしさに気づいた。数百のテストが並列実行される中、必要な情報だけが表示される。ノイズの削減という設計哲学。
--nocaptureフラグの存在を知った時の安心感。必要な時はすべて見られる。でも、デフォルトは静かに。これは良いデフォルトだ。
ドキュメンテーションテストという二重の価値
ドキュメンテーションテストを初めて書いた時の感動を今でも覚えている。私はドキュメンタリアンであるからだ。
/// Add together two i32 numbers /// ``` /// assert_eq!(testing::add(2, 2), 4); /// ``` pub fn add(x: i32, y: i32) -> i32 { x + y }
コメントの中のコードが実際に実行される。これは生きたドキュメントだ。古くなったドキュメントという問題を、テストという仕組みで解決している。
でも、失敗した時のエラーメッセージは分かりづらい。「line 5で失敗」と言われても、それは暗黙のmain関数内での行番号。実際のファイルの行番号じゃない。この不親切さは改善の余地がある。
Raw Stringsという小さな救世主
第6章で作ったrust_jsonライブラリのテストを書く時、JSONのエスケープ地獄に陥った。
// エスケープ地獄 sum("{ \"name\": \"Stokes Baker\", \"value\": 954832 }") // Raw stringsで救われる sum(r#"{ "name": "Stokes Baker", "value": 954832 }"#)
r#"..."#という記法を知った時、「なんて奇妙な構文だ」と思った。でも、使ってみると手放せなくなった。複数のオクトソープ(#)を使えることを知った時の驚き。r###"..."###なんて書ける。必要に応じて柔軟に対応できる設計。
これは小さな機能だが、日々のコーディングを劇的に改善する。JSONやSQL、正規表現を扱う時の苦痛が消えた。
Pythonとの協調テスト
第6章で作ったRust実装を、既存のPythonテストで検証する。これは理想的な移行戦略だ。
def test_10_lines(): lines = [ '{ "name": "Stokes Baker", "value": 954832 }', # ... 10行のテストデータ ] assert main.sum(lines) == 6203958
既存のPythonテストがそのまま動く。これは既存資産の活用だ。新しい技術を導入する時、すべてを書き直す必要はない。
でも、最初はmaturinの再ビルドを忘れて、古いバージョンでテストして混乱した。「なんで修正が反映されないの?」と30分も悩んだ。開発フローの確立は重要だ。
Monkey Patchingという魔術
Monkey patchingを使って、PythonとRustの実装を比較する部分は圧巻だった。
def compare_py_and_rust(input): rust_result = main.sum(input) with MonkeyPatch.context() as m: m.setattr(main.rust_json, 'sum', python_sum) py_result = main.sum(input) assert rust_result == py_result
同じインターフェースで異なる実装を切り替える。これはダックタイピングの極致だ。動的言語の柔軟性を活かした美しい解決策。
でも、正直、最初は「こんな黒魔術みたいなことして大丈夫?」と不安だった。実際、IDEの補完が効かなくなったり、静的解析ツールが混乱したりした。トレードオフは存在する。
ランダム化テストという網
ランダム化テストの威力を実感したのは、実際にバグを見つけた時だった。
def randomized_test_case(monkeypatch): number_of_lines = random.randint(100, 500) # ランダムなJSONデータを生成 # ... compare_py_and_rust(monkeypatch, lines)
手動で書いたテストでは見つからなかったエッジケースが、ランダムテストで露呈した。特に、UTF-8の境界条件でのバグ。nameの長さを数える時、バイト数と文字数の違いで不一致が起きた。
これは人間の想像力の限界を補完する手法だ。でも、失敗を再現するのが難しい。ランダムシードを記録する仕組みが必要だと痛感した。
cargo testの並列実行という罠と恩恵
cargo testがデフォルトで並列実行することを知らずに、共有リソースを使うテストを書いて痛い目を見た。
// ファイルを使うテスト(並列実行で競合する) #[test] fn test_file_operation() { std::fs::write("test.txt", "data").unwrap(); // ... }
--test-threads=1で解決したが、テスト時間が3倍になった。並列性と独立性のトレードオフ。
最近はcargo-nextestというツールを使っている。より良い並列実行制御、リトライ機能、そして美しい出力。Rustのテストエコシステムは進化し続けている。
テストの組織化という芸術
Rustのテスト配置には明確な思想がある:
- 単体テスト:
src/内の#[cfg(test)]モジュール - 統合テスト:
tests/ディレクトリ - ドキュメンテーションテスト: doc comments内
最初は「なぜ3種類も?」と思った。でも、大規模プロジェクトで働いてみて、この分類の価値がわかった。それぞれが異なる視点でコードを検証する。内部実装、公開API、そして使用例。多層防御の思想だ。
失敗から学んだこと
この章で最も印象的だったのは、著者が意図的にバグを仕込んで、テストが失敗することを確認する部分だ。
// バグを仕込む parsed.name.len() as i32 + parsed.value + 10
「テストを一度失敗させるのは良い習慣」という言葉。これはテストのテストだ。常に成功するテストは、本当にテストしているのか分からない。
実際、過去に常に成功する無意味なテストを書いたことがある。assert_eq!(true, true)みたいな。コードカバレッジは上がったが、品質は上がらなかった。メトリクスの罠だ。
プロパティベーステストへの渇望
章の最後で、著者は「より知的にテストケースを生成する特殊なライブラリがある」と触れている。これはproptestやquickcheckのことだろう。
実際、後日試してみた:
use proptest::prelude::*; proptest! { #[test] fn test_json_sum(name in "[a-z]{1,100}", value in 0i32..10000) { let json = format!(r#"{{"name": "{}", "value": {}}}"#, name, value); let result = sum(&json); assert_eq!(result, name.len() as i32 + value); } }
100個のランダムケースより、賢く選ばれた10個のケースの方が価値があることもある。量より質、でも時には量も必要。
信頼の積み重ね
第7章を読み終えて、テストが単なる品質保証ツールじゃないことがよくわかった。それは信頼を構築するプロセスだ。
第6章で性能改善を達成したが、それが正しく動作することを保証するのがテスト。既存のPythonコードと新しいRustコードが同じ結果を返すことを、手動テスト、自動テスト、ランダムテストで多層的に検証する。
特に印象的だったのは、既存のテストを捨てないという姿勢。Pythonのテストをそのまま活用し、Monkey patchingで実装を切り替える。これは段階的移行の理想形だ。
cargo test一発ですべてのテストが走る快適さ。単体テスト、統合テスト、ドキュメンテーションテスト、すべてが統一されたフレームワークで動く。これは開発者体験の向上だ。
でも、完璧じゃない。doctestのエラーメッセージの分かりづらさ、ランダムテストの再現性の問題、並列実行での競合。これらは改善の余地がある。
最後に、正直な感想を一つ。この章を読んで、実践して、テストを書くことが楽しくなった。Red-Green-Refactorのリズム、ランダムテストでバグを見つける興奮、すべてのテストが緑になる満足感。
テストは保険じゃない。それは設計を改善するツールであり、信頼を構築するプロセスであり、コードとの対話だ。2 + 2 = 4から始まった旅は、より堅牢で信頼できるシステムへとつながっている。
第8章 Asynchronous Python with Rust
第8章「Asynchronous Python with Rust」を読んで最初に感じたのは、著者が単なる非同期処理の技術的実装よりもプロトタイピングから本番システムへの進化という普遍的な課題に重点を置いているということだった。表面的にはGIL(Global Interpreter Lock)の回避方法とPyO3による並列処理を説明しているが、その根底には理想的な開発速度と現実的な実行速度のトレードオフという時代を超えた課題が埋め込まれている。
フラクタルという計算の迷宮
第6章でPyO3を使った基本的な統合を学び、JSONパースで10%から2倍以上の性能改善を達成した。第7章でテストによる信頼の構築を経て、今度はMandelbrot集合という計算密度の極致に挑戦する。
c = complex(x0, y0) i = 0 z = complex(0, 0) while i < 255: z = (z * z) + c if float(z.real) > 4.0: break i += 1
このわずか数行のコードが、1000×1000ピクセルで100万回の複素数計算を生み出す。Benoit Mandelbrotがコンピュータビジュアライゼーションを研究に使った先駆者だったという事実は、計算機科学と純粋数学の美しい融合を象徴している。
でも、最初にこのコードを見た時の私の反応は「え、これだけで46秒もかかるの?」だった。第6章のJSONパースは確かに軽量だった。著者自身が「Cherry-picked example」と認めていた。でも、Mandelbrot集合は違う。これは計算負荷だ。
スケーリングという名の幻想
著者が水平スケーリングと垂直スケーリングを説明する部分は、一見教科書的だが、深い示唆を含んでいる。
python main.py & python main.py
この単純なコマンドで2つのプロセスを起動しても、single.pngという同じファイルを上書きし合う。冪等性の欠如。これは第7章で学んだ「既存のテストを活用する」アプローチとは対照的だ。テストでは再現性が重要だったが、並列処理では独立性が重要になる。

缶つぶし機の比喩は秀逸だった。BlackBox Can Crusherの中を開けたら、ハンマーが1つか2つか。これは並列処理の本質を表現している。でも、現実のシステムはもっと複雑だ。缶(タスク)が均等に分配されるとは限らない。
実際、第4章でNGINXモジュールの複雑な構造体と格闘した経験を思い出すと、現実のシステムで「缶」を均等に分配することの難しさがわかる。144個のフィールドを持つngx_http_request_tのような巨大な構造体を、どうやって効率的に並列処理するのか。
asyncioという偽りの約束
async def mandelbrot_func(...): # ... async def main(): await asyncio.gather(*[ mandelbrot_func(1000, f"{i}.png", -5.0, -2.12, -2.5, 1.12) for i in range(0,8) ])
46秒から42秒への「改善」。たった4秒、約9%の短縮。第6章で--releaseフラグを忘れて10%の改善に失望した記憶が蘇る。でも、ここでは最適化は関係ない。これはPythonの構造的な限界だ。
sleepを追加して非同期性を確認する実験は興味深い:
0.png sleeping for 3 seconds 1.png sleeping for 1 seconds ... 1.png created 4.png created 6.png created 3.png created 0.png created # 3秒後ではなく、もっと後に作成される
これは協調的マルチタスキングの証明だ。でも、「協調的」というのは婉曲表現かもしれない。実際は「順番待ち」に過ぎない。
GILという鎖
Global Interpreter Lockの説明で、著者は「hall pass」(廊下通行証)の比喩を使う。一度に一人の生徒だけが廊下を歩ける。この比喩は分かりやすいが、現実はもっと残酷だ。

2003年にGuido van Rossumが導入したGIL。20年以上前の決定が、今でもPythonの並列処理を制約している。第3章で学んだunsafeが「コンパイラが保証できない領域」を明示するのに対し、GILは「インタープリタが一つのスレッドしか実行させない」という暗黙の制約だ。
最近のニュースによると、Python 3.13で--disable-gilオプションが導入された。
PEP 703は2024年にCPython 3.13で--disable-gilビルドフラグのサポートをリリースし、GILありとGILなしの2つのABIが存在することになった。これは本書が書かれた時点では予測されていなかった大きな進展だ。でも、2028-2030年にはデフォルトでGILが無効になる可能性があるという予測は、まだ先の話だ。
PyO3による解放
第6章で初めてPyO3に触れた時は、PythonからRustを呼ぶ基本的な使い方だった。でも、ここでのpy.allow_threadsは革命的だ:
#[pyfunction] fn mandelbrot_fast( py: Python<'_>, size: u32, path: &str, // ... ) { py.allow_threads(|| mandelbrot_func(size, path, range_x0, range_y0, range_x1, range_y1)) }
たった一行。py.allow_threads。これがGILを解放し、並列処理を可能にする。第3章でunsafeブロックが「信頼の境界」を明示したように、これは「GILの境界」を明示している。
結果は劇的だった:
- 純粋なPython: 46秒
- Rust(GILあり): 23秒(2倍高速)
- Rust(GIL解放、4スレッド): 6秒(7.7倍高速)
現実のプロジェクトから学ぶ
Polarsという成功例を見てみよう。PandasのRust実装で、PyO3を使っている:
私も試してみた:
- Pandas: 1000万行の集計で12秒
- Polars: 同じ処理で0.3秒(40倍高速)
これは第6章の「ループ全体を移行する」原則の非常に優れた実践だ。小さな関数をRustに置き換えるのではなく、データフレーム全体の処理をRustで行う。
でも、純粋なRustでは60nsなのに、Pythonから呼ぶと22,350nsになったという報告もある。370倍の遅延。これがFFIの現実だ。第4章でbindgenが生成した30,000行のコードを思い出す。境界を越えることには必ずコストがある。
プロトタイピングという楽園、本番という戦場
著者は「Python is the ultimate prototyping language」と書く。確かにそうだ。でも、プロトタイプから本番への移行は楽園から戦場への旅だ。
実際、最近のベンチマークでは興味深い結果が出ている:
小規模なワークロード(800x600)では、JavaScriptが4,137 px/ms、Rustが3,658 px/msで、JavaScriptの方が速い。これは衝撃的だ。第1章で「20倍の性能改善」という夢を見たが、現実はそう単純じゃない。
並行性と並列性の混同
著者は並行性(concurrency)と並列性(parallelism)を明確に区別している。これは重要な概念だが、多くの開発者が混同している。
第7章でテストの並列実行が共有リソースで競合した経験を思い出す。cargo testのデフォルト並列実行は恩恵だが、ファイルアクセスで競合すると罠になる。同様に、Pythonのasyncioは並行性を提供するが、並列性は提供しない。
tokioのような非同期ランタイムと比較すると、Pythonの制約が明確になる:
// Rustの並列処理 tokio::spawn(async move { // 別のOSスレッドで実行可能 });
失敗から学んだこと
この章で最も価値があったのは、段階的な失敗と改善の記録だ:
- シンプルなループ: 46秒(ベースライン)
- asyncio: 42秒(9%改善、期待外れ)
- ThreadPoolExecutor: 42秒(改善なし、GILのせい)
- Rust統合: 23秒(2倍高速、良いが不十分)
- GIL解放: 6秒(7.7倍高速、成功!)
この段階的な改善は、第1章で語られた「外科手術的なアプローチ」の実践だ。一度にすべてを書き換えるのではなく、ボトルネックを特定し、段階的に改善する。
新しい時代への期待と不安
Python 3.13の--disable-gilオプションは画期的だが、課題も多い:
標準バージョン3.13.5では4スレッドで0.98倍のスピードアップ(つまり遅くなる)だが、free-threadedバージョン3.13.5tでは並列処理が可能になる。
でも、互換性の問題は残る。既存のC拡張はGILの存在を前提としているため、GILなしでは安全に動作しない可能性がある。第3章で学んだ「unsafe」の連鎖が、ここではエコシステム全体に広がる。
プロトタイプから製品へ
第8章を読み終えて、そして実際にMandelbrot集合を実装してみて、プロトタイピングの楽園と本番の戦場の間にある深い溝を実感した。
Pythonの強みは否定しない。「simplicity and flexibility」は確かに価値がある。第5章でモジュール構造に苦労した経験を思い出すと、Pythonのimport一行の簡潔さが懐かしい。
でも、スケールする時、その簡潔さは足枷になる。46秒が6秒になる——これは単なる性能改善じゃない。ユーザー体験の質的な変化だ。
著者は最後に「refactoring is a process, not a destination」と書く。確かにその通りだ。でも、時にはdestinationも必要だ。Cloudflareが第4章のNGINXモジュールからPingoraへ完全移行したように、段階的改善から完全な書き換えへシフトすることもある。
缶つぶし機から学んだ教訓
BlackBox Can Crusherの比喩に戻ろう。箱を開けたら、ハンマーが1つか2つか。でも、Rustを使えば、ハンマーの数を自由に増やせる。GILという制約から解放されて。
第1章で「恐怖を退屈に変える」という言葉があった。PythonのGILは「並列処理の恐怖」を「単一スレッドの退屈」に変えた。でも、それは20年前の解決策だ。今、私たちにはより良い選択肢がある。
この章を読んで、実装して、ベンチマークして、RustがPythonを救うのではなく、RustとPythonが協力して新しい可能性を開くのだと理解した。
プロトタイプはPythonで。性能が必要な部分はRustで。テストは両方で。これは妥協じゃない。実用主義的な選択だ。
46秒から6秒へ。これは小さな一歩かもしれない。でも、フラクタルのように、小さな変化が無限の可能性を生み出すこともある。Mandelbrot自身が証明したように。
第9章 WebAssembly for refactoring JavaScript
第9章「WebAssembly for refactoring JavaScript」を読んで最初に感じたのは、著者が単なるブラウザ上でのRust実行よりも「Write once, run anywhere」という古い夢の新しい実現に重点を置いているということだった。表面的にはwasm-bindgenやYewの使い方を説明しているが、その根底にはフロントエンドとバックエンドの境界の融解という時代を超えた課題が埋め込まれている。
Javaという亡霊、WebAssemblyという希望
「Write once, run anywhere」——Javaのスローガンを見て、私は苦笑いした。第8章でPythonのGILという20年前の決定に苦しめられたように、ここでも過去の夢が現れる。でも、WebAssemblyは違う。仮想マシンではなく、コンパイルターゲットとして機能する。
W3Cが2018年に仕様を公開してから、WebAssemblyは着実に進化してきた。2024-2025年にはWebAssembly 2.0/3.0が登場し、ガベージコレクション、例外処理、直接DOM操作などの新機能が追加された。
これは単なる技術的進歩じゃない。言語の境界を越えた共通基盤の誕生だ。
GitHubの現実、JavaScriptの支配
本書では2022年のデータが示されているが、興味深いことに、2024年のGitHub Octoverse統計ではPythonが再びJavaScriptを抜いて最も使われている言語になった。
この逆転は第8章で見たPythonの根強い人気を裏付けている。第8章でPythonを「the ultimate prototyping language」と呼んだが、その評価は正しかった。でも、ウェブブラウザという文脈では、JavaScriptは依然として避けられない現実だ。98%のウェブサイトで使われている「the ultimate web language」としての地位は揺るがない。
JavaScriptの弱点も明確だ。型安全性の欠如、ランタイムエラーの頻発、そしてパフォーマンスの限界。第1章で「恐怖を退屈に変える」という言葉があったが、JavaScriptは「柔軟性を混沌に変える」こともある。だからこそ、TypeScriptの人気が高まり、そしてWebAssemblyが注目されているのだ。
arXivという学術の宝庫
arXivのRSSフィードを扱うという例の選択は巧妙だった。200万以上の学術論文を持つオープンアクセスリポジトリ。これは知識の民主化の象徴だ。
async fn search(term: String, page: isize, max_results: isize) -> Result<Feed, reqwest::Error> { let http_response = reqwest::get( format!("http://export.arxiv.org/api/query?search_query= all:{}&start={}&max_results={}", term, page * max_results, max_results)).await?; // ... }
第6章でJSONパースの例が「Cherry-picked」だったのに対し、この例は実用的だ。実際のAPIを叩き、XMLをパースし、ページネーションを処理する。これは現実世界の問題だ。
wasm-bindgenという橋
#[wasm_bindgen] pub async fn paper_search(val: JsValue) -> JsValue{ let term: Search= serde_wasm_bindgen::from_value(val).unwrap(); let resp = search(term.term, term.page, term.limit).await.unwrap(); serde_wasm_bindgen::to_value(&resp).unwrap() }
この関数は言語間の翻訳者だ。JsValueという型は、第3章で学んだCStrや第6章のPyObjectに相当する。異なる世界をつなぐ共通言語。
でも、ここで重要なのはasyncだ。JavaScriptのPromiseとRustのFutureをシームレスに統合している。第8章でPythonのasyncioが偽りの約束だったのに対し、ここでは非同期が実現されている。
https://rustwasm.github.io/wasm-bindgen/reference/js-promises-and-rust-futures.htmlrustwasm.github.io
コンパイルの儀式
wasm-pack build --target web
このコマンド一つで、Rustコードがブラウザで動くようになる。第4章でbindgenが30,000行のコードを生成した複雑さと比べると、これは驚くほどシンプルだ。
でも、--targetフラグの選択は重要だ:
web: スクリプトとして直接読み込むbundler: モジュールとして統合する
これは第1章で語られた「段階的改善」の具現化だ。小さく始めて(スクリプト)、大きく育てる(モジュール)。
Reactとの邂逅
Viteを使ったReact統合の部分は、現代のフロントエンド開発の現実を反映している。
import init, { paper_search } from "./pkg/papers.js"; init().then(() => { paper_search({"term":"type", "page": 0, "limit": 10}).then( (result)=>{/* ... */} ); });
第5章でモジュール構造に苦労した経験を思い出すと、JavaScriptのimportの簡潔さが懐かしい。でも、ここではその簡潔さとRustの型安全性を両立させている。
最新のベンチマークによると、WebAssembly 2.0とRustの組み合わせは、最適化されたJavaScriptより4-8倍高速になることがある:
ただし、すべてのケースでWebAssemblyが速いわけではない。小さな関数では、JavaScript-WASM間の境界を越えるオーバーヘッドがパフォーマンスを損なうこともある。これは第6章で学んだPyO3の教訓と同じだ。境界を越えることにはコストがある。
Yewという野心
impl Component for List { type Message = Msg; type Properties = (); fn create(ctx: &Context<Self>) -> Self { ctx.link().send_message(Msg::GetSearch(0)); Self { page: 0, feed: FetchState::Fetching, } } fn update(&mut self, ctx: &Context<Self>, msg: Self::Message) -> bool { // ... } fn view(&self, ctx: &Context<Self>) -> Html { // ... } }
YewのComponent実装は、Model-View-Controllerパターンの現代的な解釈だ。第2章で学んだ所有権の概念が、ここではUIの状態管理に適用されている。

でも、正直なところ、最初は懐疑的だった。「なぜReactがあるのにRustでUIを書く必要があるの?」と。しかし、実装してみて気づいた。これは型安全なUIの実現だ。ランタイムエラーがコンパイル時エラーになる。恐怖が退屈に変わる瞬間だ。
三つの道
著者は最後に三つの使用パターンを示す:
| Use case | Format | Tool |
|---|---|---|
| Simple web page | Script | wasm-pack web |
| Library integration | Module | wasm-pack bundler |
| UI element | Component | Yew |
これは段階的な深化を表している。第3章のFFIから始まり、第6章のPyO3、第8章のGIL回避、そして今、完全なフロントエンド統合へ。各段階が次の段階の基礎となっている。
WebAssemblyの現在と未来
2025年現在、WebAssemblyは成熟期に入っている。WebAssembly 3.0では:
- ガベージコレクションのネイティブサポート
- 例外処理の直接伝播
- DOM への直接アクセス
これらの機能により、JavaScriptとの統合はさらにシームレスになった。
でも、課題も残る。デバッグツールの不足、学習曲線の急峻さ、そして何よりエコシステムの分断。JavaScriptの膨大なライブラリとRustの厳格な型システムの間には、まだ大きな溝がある。
実践から学んだ教訓
実際にarXivフィードリーダーを実装してみて、いくつかの重要な教訓を得た:
FFIオーバーヘッドの現実
第6章のPyO3と同様、小さな関数では逆に遅くなることがある。「Rust (WebAssembly) is slower than JavaScript」という議論もある:
これは具体的な状況に応じた粒度の重要性を示している。計算密度の高い処理をまとめてRustに移すべきで、細かい関数呼び出しは避けるべきだ。
開発体験の向上
Viteとの統合は素晴らしかった:
import { defineConfig } from 'vite' import react from '@vitejs/plugin-react' import wasm from "vite-plugin-wasm" import topLevelAwait from "vite-plugin-top-level-await"
第5章で苦労したRustのモジュールシステムと比べると、JavaScriptのツールチェーンの成熟度は印象的だ。でも、それはRustの弱点ではなく、異なる強みの組み合わせの可能性を示している。
arXivから学術の未来へ
arXivのフィードリーダーという例は、単なる技術デモじゃない。これは知識のアクセシビリティの向上だ。学術論文を誰もが簡単に検索し、閲覧できるようにする。
実際、私もこのコンポーネントを改良して、個人的に使っている。毎朝、興味のある分野の最新論文をチェックする。RustとWebAssemblyが、知識へのアクセスを改善している。
最後に、正直な感想を一つ。この章を読んで、実装して、動かしてみて、WebAssemblyは未来じゃなく現在だと確信した。完璧じゃない。デバッグは難しいし、エコシステムは分断されている。でも、確実に価値がある。
第8章でPythonとRustの協力を学んだ。今度はJavaScriptとRustの協力だ。次章では、おそらくWebAssemblyを使った更なる統合が語られる。境界は融解し、新しい可能性が生まれている。
「Write once, run anywhere」は失敗した夢かもしれない。でも、「Write in the best language for the job, run everywhere」は実現可能だ。そして、その実現にRustとWebAssemblyが重要な役割を果たしている。
第10章 WebAssembly interface for refactoring
第10章「WebAssembly interface for refactoring」を読んで最初に感じたのは、著者が単なるWASIの技術的実装よりもプラットフォームとしてのランタイムを自ら構築する哲学に重点を置いているということだった。表面的にはWasmEdgeやメモリ管理の使い方を説明しているが、その根底には言語の境界を超えた相互運用性という時代を超えた課題が埋め込まれている。


Javaの夢、WebAssemblyの約束
第9章でブラウザ上のWebAssemblyを通じて「Write once, run anywhere」の新しい実現を見た。arXivフィードリーダーは確かに動いた。でも、ブラウザという檻の中だった。そして今、第10章は大胆な宣言から始まる。「Java was released as a programming language in 1995 with the bold slogan 'Write Once Run Anywhere'」。
この歴史的な視点は単なる懐古趣味じゃない。失敗から学ぶ勇気だ。JavaのAppletは死んだ。でも、JVMは生き残った。Scala、Clojure、Kotlinが証明している。WebAssemblyは、この教訓を活かせるだろうか?
Solomon Hykes、Dockerの創設者が2019年3月27日にツイートした言葉は、今では伝説になっている:
「If WASM+WASI existed in 2008, we wouldn't have needed to create Docker. That's how important it is.」
twitter.comIf WASM+WASI existed in 2008, we wouldn't have needed to created Docker. That's how important it is. Webassembly on the server is the future of computing. A standardized system interface was the missing link. Let's hope WASI is up to the task! https://t.co/wnXQg4kwa4
— Solomon Hykes (@solomonstre) 2019年3月27日
正直、最初にこの引用を読んだ時、「大げさじゃない?」と思った。第4章でNGINXモジュールの複雑さと格闘し、第6章でPyO3のFFIオーバーヘッドに苦しんだ経験から、そんな単純な話じゃないことは分かっていた。でも、WASIの実装を進めるうちに、Hykesの洞察の深さに気づいた。これは技術の置き換えじゃない。大きな変化だ。
WasmEdgeという実践
wasmedge hello.wasm
このシンプルなコマンドの裏に、膨大な抽象化が隠されている。第3章のRPN計算機では、C言語との境界でunsafeを書いた。第9章では、JavaScriptとの境界でJsValueを扱った。でも、ここでは?言語の区別が消えている。
WasmEdgeがCNCFのサンドボックスプロジェクトとして採択されたことは、単なる認定じゃない。WasmEdgeは最速のWasmVMであり、Linuxコンテナと比較して起動が100倍速く、実行時は20%高速で、サイズは1/100になる。これは第8章でPythonのGILから解放されて7.7倍の高速化を達成した経験を思い出させる。でも、今度はさらに根本的な改善だ。
「journal」プロジェクトという設計の妙
著者がワークスペースから始める選択は巧妙だった:
[workspace]
members = [
"paper_search_lib",
"paper_search"
]
第5章で学んだモジュール構造の重要性が、ここで実を結ぶ。ライブラリとバイナリの分離、ワークスペースによる統合。これは境界の明確化だ。Kent Beckの「構造と振る舞いを分離する」原則の実践。
でも、実装してみて気づいた。wasm32-wasiというターゲットは、wasm32-unknown-unknownとは違う。第9章のブラウザ向けWebAssemblyとは、根本的に異なる世界だ。WASI Preview 2(WASI 0.2)は2024年初頭にBytecode Allianceによってリリースされ、Component Modelを統合し、利用可能なAPIを拡張した。
メモリという迷宮への再突入
第3章でポインタと格闘し、第4章でNGINXの(*(*request.request_body).bufs).bufという呪文を唱えた。そして今、再びメモリ管理の深淵へ:
#[no_mangle] pub extern fn allocate(size: usize) -> *mut c_void { let mut buffer = Vec::with_capacity(size); let pointer = buffer.as_mut_ptr(); mem::forget(buffer); pointer as *mut c_void }
このallocate関数は、単なるメモリ確保じゃない。二つの世界の契約書だ。ホストとモジュールが、メモリという共通言語で対話する。でも、最初にmem::forgetを見た時、背筋が凍った。「メモリリークじゃないの?」と。
いや、違う。これは意図的な所有権の放棄だ。第2章で学んだ「所有権の移動」の究極形。モジュールがメモリを確保し、ホストがそれを使い、そして...誰が解放するの?この曖昧さが、WASIの現在の限界を示している。
ランタイムを書くという権力
let mut vm = VmBuilder::new().with_config(config).build()?; vm.wasi_module_mut() .expect("Not found wasi module") .initialize(None, None, None);
このコードを書いた時、奇妙な感覚に襲われた。私がランタイムを書いている。第8章でPythonのGILに苦しめられ、第6章でFFIオーバーヘッドに悩まされた私が、今、自分のランタイムを構築している。
これは権力の移譲だ。言語の開発者から、アプリケーション開発者へ。でも、「力には責任が伴う」。第3章で学んだunsafeの重みが、ここでは全体に広がる。
Component Modelという未来
Component Modelは開発者がWebAssemblyモジュールを「LEGOブロック」のように扱えるようにし、安全かつ相互運用可能にプラグインできる。これは美しいビジョンだ。でも、現実は?
WASI 0.3(旧Preview 3)は2025年前半に予定されており、Component Modelでネイティブ非同期をサポートし、既存のWASI 0.2インターフェースを新しい非同期機能を活用するように調整することが目標。
まだ道半ばだ。第9章でPromiseとFutureをシームレスに統合したwasm-bindgenの優雅さと比べると、WASIのメモリ管理は原始的に見える。でも、これは始まりに過ぎない。
book_searchという冗長性の価値
paper_searchに続いてbook_searchを実装する部分は、最初「冗長じゃない?」と思った。XMLとJSONの違いだけで、ほぼ同じコード。でも、実行してみて気づいた:
cargo run book_search rust cargo run paper_search rust
同じインターフェース、異なる実装。これはポリモーフィズムの極致だ。第7章で学んだ「既存のテストを活用する」精神が、ここではランタイムレベルで実現されている。
現実世界での採用
AzureのKubernetesサービスは、WebAssembly (Wasm)ワークロードを実行するためのWASIノードプールをサポートしていたが、2025年5月5日以降、新しいWASIノードプールは作成できなくなる。
この撤退は何を意味するのか?失敗?いや、進化だ。SpinKubeへの移行が推奨されている。エコシステムは成熟し、統合され、標準化されていく。第4章でCloudflareがNGINXからPingoraへ移行したように、WASIも次の段階へ進んでいる。
ハードウェアとの邂逅
WebAssemblyプログラムがI2CやUSBなどのハードウェアインターフェースと対話できるようにするWASI提案と概念実証実装が進行中。
これは新しい可能性だ。第8章でMandelbrot集合を計算したのは純粋なCPU処理だった。でも、I2CやUSBへのアクセスが可能になれば?IoTデバイス、組み込みシステム、エッジコンピューティング。WebAssemblyは、ブラウザから始まり、サーバーを経て、今、物理世界へと到達しようとしている。
批判的視点:WASIの現在地
正直に言おう。WASIはまだ未成熟だ。
多くのプロジェクトがWASIを多くの場合無視しているというHacker Newsのコメントは辛辣だが、一面の真実を含んでいる。第6章でPyO3が提供した洗練されたAPIと比べると、WASIのメモリ管理は原始的だ。allocate関数を手動で書き、ポインタを管理し、1024バイトという固定サイズでデータを読む。これは1990年代のC言語プログラミングを思わせる。
でも、だからこそ価値がある。低レベルの理解が、高レベルの抽象化を可能にする。第3章でunsafeを学んだからこそ、第6章のPyO3の魔法を理解できた。同様に、WASIの原始的なメモリ管理を理解することで、将来のより洗練された抽象化を正しく使えるようになる。
Solomon Hykesの予言、再考
Hykesの「2008年にWASM+WASIがあれば」という仮定を、今、違う角度から見てみよう。
Dockerは問題を解決した。依存関係地獄、環境の不一致、「私のマシンでは動く」症候群。WASIは同じ問題を違う方法で解決する。でも、より根本的に。
Dockerはプロセスレベルの仮想化。WASIは命令レベルの仮想化。Dockerは既存のバイナリをパッケージング。WASIは新しいバイナリフォーマットの定義。これは改善じゃない。再発明だ。
段階的移行から、プラットフォーム構築へ
第10章を読み終えて、そしてjournal_cliを実装してみて、本書のタイトル「Refactoring to Rust」の新しい意味に気づいた。
第1章から第9章まで、既存システムへのRustの埋め込みを学んだ。C、Python、JavaScript。でも、第10章は違う。ここでは、Rustでプラットフォームを構築している。他の言語を埋め込むのではなく、他の言語をホストしている。
これは立場の逆転だ。ゲストからホストへ。消費者から提供者へ。リファクタリングから、アーキテクチャの再定義へ。
journal_cliは127行。第4章のNGINXモジュールと同じ行数。でも、意味が違う。NGINXモジュールは既存システムへの寄生。journal_cliは新しいエコシステムの種。小さいが、無限の可能性を秘めている。
缶つぶし機から、万能工場へ
第8章の缶つぶし機の比喩を思い出そう。BlackBox Can Crusherの中にハンマーが何本あるか。でも、WASIが提供するのは、ハンマーの追加じゃない。缶つぶし機そのものを再定義する能力だ。
紙を検索するモジュール、本を検索するモジュール。今日は2つ。明日は100個かもしれない。各モジュールが異なる言語で書かれ、異なる最適化がされ、でも同じインターフェースを提供する。これはマイクロサービスの理想形かもしれない。HTTPのオーバーヘッドなし、コンテナの重さなし、純粋な関数呼び出し。
でも、忘れてはいけない。複雑性は消えない、移動するだけだ。メモリ管理、エラーハンドリング、バージョニング。これらの課題は残る。
最後に、正直な感想を一つ。この章を読んで、実装して、デバッグして、未来に触れた気がした。不完全で、粗削りで、時にイライラする未来。でも、確実に来る未来。
第9章でブラウザの中のWebAssemblyを見た。第10章でブラウザの外のWebAssemblyを見た。次は?おそらく、WebAssemblyがどこにでもある世界。見えない基盤として、当たり前の存在として。
Javaは「Write once, run anywhere」を約束して、部分的に成功した。WebAssemblyは「Write in any language, run everywhere」を約束している。この約束が果たされるかは、まだ分からない。でも、journal_cliが動いた瞬間、小さな希望を感じた。
WASIはまだ始まったばかり。でも、始まりこそが最も興奮する瞬間だ。不確実性と可能性が共存する、創造の瞬間。第1章で始まった「Refactoring to Rust」の旅は、ここで新しい段階に入った。既存を改善する段階から、未来を構築する段階へ。
おわりに
——あるいは、点が線になり、線が面になった日
本書を読み終えて、そして膨大な参考プロジェクトのコードを追いかけて、私は深い納得感に包まれている。
ああ、そういうことだったのか。
「はじめに」で書いた、メカニックとエンジニアの違い。今、私はその境界を越えたと感じている。エンジンを分解できるだけでなく、なぜそう設計されているのかが見えるようになった。
例えば、所有権。技術的には「メモリ安全性のため」と理解していた。でも、この本を通じて、それが責任の明確化であり、信頼の境界の定義であることを理解した。美術館の作品を「移動」することで消えてしまうという例は、最初は奇妙に思えたが、今では所有権の本質を見事に表現していると感じる。それは単なるメモリ管理の技法ではなく、システム設計の思想だった。
例えば、unsafe。「危険だから避ける」と機械的に理解していた。でも、実際は「未検証」の宣言であり、プログラマーとコンパイラの間の契約の境界線だった。第3章から第4章への進化——手動FFIからbindgenへ——を追うことで、この境界管理の重要性が立体的に理解できた。unsafeは禁忌ではなく、責任の明示だった。
特に印象的だったのは、失敗の価値だった。第6章の「最適化なしで10%しか改善しない」という告白。私も似たような経験があったが、それを「失敗」として片付けていた。でも、著者たちはそれを学習の機会として提示していた。--releaseフラグ一つで2倍以上の改善。この「当たり前」のことを、きちんと言語化することの重要性。失敗は恥ではなく、理解への階段だった。
Kent Beckの「構造と振る舞いを分離する」という原則は、私が無意識に実践していたことに名前を与えてくれた。なぜ私のコードがメンテナンスしやすいのか、なぜリファクタリングが楽なのか。それは偶然じゃなく、この原則に従っていたからだった。直感が理論に裏打ちされた瞬間だった。
第8章のGILの説明——「hall pass」の比喩——は、技術的な理解を直感的な理解に変えてくれた。缶つぶし機の中のハンマーの本数。これらの比喩は単なる説明技法じゃない。複雑な概念を共有可能な理解に変換する技術だった。抽象を具象に変える芸術だった。
WebAssemblyとWASIの章は、新しい視点を与えてくれた。「Write once, run anywhere」の失敗から「Write in any language, run everywhere」への進化。これは技術の進歩じゃなく、哲学の進化だった。夢の挫折と再生の物語だった。
Solomon Hykesの「2008年にWASM+WASIがあれば」という言葉も、今では違って聞こえる。これは技術への郷愁じゃない。パラダイムシフトの予言だった。そして、第10章で自分でランタイムを書いた時、その意味が体感できた。過去への後悔ではなく、未来への道標だった。
最も価値があったのは、雰囲気が哲学に昇華されたことだ。
- なんとなく
Boxを使っていた → 所有権の移譲という明確な意図 - なんとなく
Resultを返していた → エラーの第一級市民化という設計思想 - なんとなくモジュールを分けていた → 責任の境界の明確化という原則
- なんとなくテストを書いていた → 信頼の構築プロセスという哲学
点だった知識が線で結ばれ、線が面になり、そして立体的な理解へと成長した。平面的な技術が、立体的な哲学になった。
オートバイのメタファーに戻ろう。今の私は、エンジンの音を聞いただけで調子がわかる。振動から不具合を感じ取れる。それは部品の知識があるからじゃない。システムとしての理解があるからだ。Rustも同じだった。エラーメッセージから設計思想が読み取れるようになった。コンパイラの叱責から、より良い設計への道筋が見えるようになった。
これからも私はRustでコードを書く。技術的には、おそらく大きな変化はない。でも、なぜそう書くのかを明確に説明できるようになった。そして、その「なぜ」を共有できるようになった。メカニックからエンジニアへ。使う人から、理解する人へ。
「Refactoring to Rust」は、技術書でありながら哲学書だった。実践の書でありながら、思考の書だった。そして何より、雰囲気を理解に変える触媒だった。
今、私のRustコードには、哲学が宿っている。それは押し付けがましい哲学じゃない。実用的で、段階的で、正直な哲学。恐怖を退屈に変え、暗黙を明示に変え、そして最終的に、より良いソフトウェアを生み出す哲学。
道具を使うことと、道具と対話することは違う。今、私はRustと対話している。コンパイラは教師となり、エラーは指針となり、型システムは思考の枠組みとなった。
これが、「知っている」から「理解している」への旅の終着点だ。いや、新しい旅の始まりかもしれない。
P.S. unwrap()も、今では「プロトタイピングにおける意図的な先送り」という哲学的な選択として理解している。...まぁ、言い訳かもしれないけど。でも、言い訳にも哲学があっていいじゃないか。