はじめに
近年、Kubernetesの採用が進む中、複数のチームが関わり、複数のクラウドプロバイダーへのデプロイを行い、異なるスタックを扱う組織では、その導入の複雑さが新たな問題となっています。本書 『Platform Engineering on Kubernetes』は、Kubernetes に登場しつつあるベストプラクティスとオープンソースツールを活用し、これらのクラウドネイティブの問題を技術的に組織的にどのように解決するかを示してくれます。
本書では、Kubernetes上に優れたプラットフォームを構築するための要素を明確に定義し、組織の要件に合わせて必要なツールを体系的に紹介しており、実際の例とコードを交えながら各ステップをわかりやすく説明することで、最終的にはクラウドネイティブなソフトウェアを効率的に提供するための完全なプラットフォームを作成できるようになるとともに、プラットフォームチームと開発チームの緊密な連携の重要性が強調され、両者の垣根を越えてアプリケーションとインフラストラクチャが一体となったソフトウェア開発を実現することこそが、クラウドネイティブ時代のDevOpsの理想形だと感じました。
ぜひ、本稿をお読みいただき、クラウドネイティブ時代のプラットフォームエンジニアリングに必要な知識とスキルと自社に最適なプラットフォームを設計・構築できるようになる必要性を感じたのであれば『Platform Engineering on Kubernetes 』をぜひ、読んでいただきたいです。

『Platform Engineering on Kubernetes』 の構成
本書は全9章で構成されており、カンファレンスのアプリケーションを構築するための "walking skeleton" (PoC、概念実証、デモアプリケーション)を用いて解説が進められる。
- 第1章では、プラットフォームとは何か、なぜそれが必要なのか、そしてクラウドプロバイダーが提供するものとどう違うのかを紹介する。
- 第2章では、Kubernetes 上で動作するクラウドネイティブで分散されたアプリケーションを構築する際の課題を評価する。
- 第3章では、異なるクラウドプロバイダー上でアプリケーションを実行するためのリソースの構築、パッケージ化、デリバリーに必要な追加手順に焦点を当てる。
- 第4章では、パイプラインの概念を中心に、GitOps アプローチを用いて複数の環境の構成を宣言的なアプローチで管理する方法を説明する。
- 第5章では、Crossplane を使用してクラウドプロバイダー間でアプリケーションのインフラストラクチャコンポーネントをプロビジョニングする Kubernetes ネイティブなアプローチについて説明する。
- 第6章では、開発環境の作成に特化した、Kubernetes 上にプラットフォームを構築することを提案する。
- 第7章では、プラットフォームチームが利用可能なリソースにどのように接続するかを決定できるアプリケーションレベルの API で開発チームを支援することに焦点を当てる。
- 第8章では、新しいリリースを本格的にコミットする前に実験するために使用できるリリース戦略を示す。
- 第9章では、プラットフォームの構築に使用するツールからデータを取り込み、プラットフォームエンジニアリングチームがプラットフォームの取り組みを評価するための重要な指標を計算する2つのアプローチを評価する。
本書の最後には、Kubernetes 上でプラットフォームがどのように構築されるのか、プラットフォームエンジニアリングチームの優先事項は何か、そして成功するためにクラウドネイティブスペースの学習と最新情報の把握がいかに重要であるかについて、明確なイメージと実践的な経験が得られるようになっています。
知識を身体化するハンズオンもしくは黙って写経しろ
本書のリポジトリは公開されており、読者は書籍の内容に沿ってハンズオンを実施することができます。これは非常に重要な点です。なぜなら、実際に手を動かして体験することで、書籍で得た知識を体験として自分のものにできるからです。技術書を多読するタイプなのですが別に一度で理解できるタイプの人間ではないので読んでみて良いと思った書籍のみ手を動かして理解するようにしています。
Kubernetesは、複雑で広範囲に及ぶ分野です。書籍を読んで理解したつもりでも、実際に試してみると躓くことが多々あります。その都度、問題を解決していくことで、より深い理解を得ることができるのです。
ですから、読者の皆さんには、ぜひ書籍と一緒にハンズオンに取り組んでいただきたいと思います。文章を読んだだけで分かった気にならないでください。実際に手を動かし、試行錯誤することが、本当の意味での学習には欠かせません。
CloudNative Days Tokyo 2023 実行委員会が公開している『一日で学ぶクラウドネイティブ技術実践ハンズオン』は、クラウドネイティブ技術の基礎から実践的な内容まで、1日で集中的に学べる充実した内容となっています。クラウドネイティブの概念やコンテナ技術、Kubernetes、マイクロサービスアーキテクチャなどの主要なトピックがカバーされており、実際にハンズオン形式で技術を体験できるのが特徴です。クラウドネイティブ技術の入門としてお勧めの教材となっています。
また、所属組織でも独自のクラウドネイティブ技術に関する研修を提供しております。弊社の研修では、実際の業務で活用できる実践的なスキルの習得に重点を置いています。カリキュラムの概要については公開しておりますので、ご興味のある方はぜひご覧ください。クラウドネイティブ技術の習得を目指す方に向けて、効果的な学習の機会を提供できればと考えております。
1 (The rise of) platforms on top of Kubernetes
クラウドネイティブ時代の本格的な幕開けとともに、Kubernetesは急速に普及し、コンテナ化されたアプリケーションを運用するための事実上の標準となりました。本章では、まずプラットフォームの定義とその必要性が丁寧に説明されています。プラットフォームとは、企業が顧客向けのソフトウェアを開発・運用するために必要な一連のサービスを提供するものであり、開発チームが効率的に価値を届けるためのワンストップショップの役割を果たします。また、プラットフォームは静的なものではなく、組織の成熟度に合わせて進化していくべきものというような主張がされている点が印象的でした。

クラウドプロバイダーが提供するサービスは、レイヤー別に分類され、それぞれの特徴が解説されています。
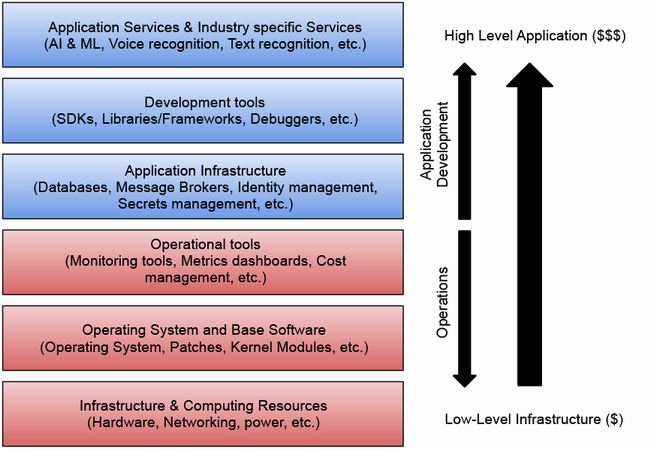
特に、アプリケーション固有のニーズを満たすためには、これらのサービスを組み合わせ、独自のレイヤーを構築する必要があると強調されています。この点については、『CloudNativeな時代に求められる Webサービス基盤モデルの再考』というタイトルで登壇した際にもまとめています。
また、クラウドプロバイダーが提供するプラットフォームの特徴として、API、SDK、CLI、ダッシュボードなどが挙げられています。これらのツールを効果的に組み合わせることで、開発チームはアプリケーションをスムーズに構築・デプロイできます。一方で、プロバイダー固有のツールやワークフローを学習するコストも無視できないと指摘されています。
Google Cloud Platform (GCP) を例に、クラウドプロバイダーが提供するダッシュボード、CLI、API の実際の使用例が紹介されています。これらのツールは、リソースのプロビジョニングを大幅に簡素化してくれますが、一方でプロバイダー固有の知識が必要とされる点にも触れられています。
クラウドプロバイダーのプラットフォームが広く受け入れられている理由として、API主導の設計、充実したツールの提供、そして従量課金モデルが挙げられています。特に、開発チームが必要なリソースをオンデマンドで利用できる点は、ビジネスのアジリティを高める上で大きなメリットだと言えます。
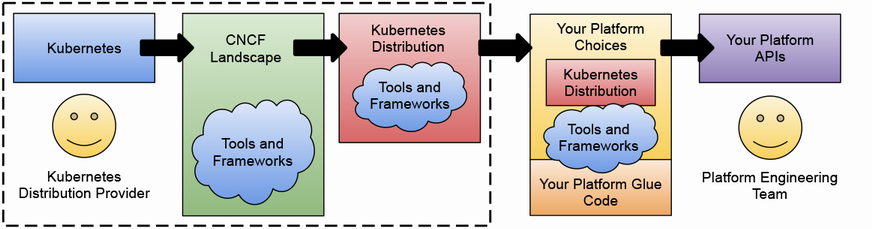
次に、Kubernetes 上にプラットフォームを構築することの意義と、そのためのエコシステムについて解説されています。Kubernetes は、クラウドネイティブなアプリケーションを開発・運用するための基盤として広く採用されていますが、それ自体はプラットフォームではなく、プラットフォームを構築するための構成要素を提供するものだと位置づけられています。
Kubernetes を導入する際には、単にツールを選定するだけでなく、組織の文化や成熟度に合わせて、段階的にプラットフォームを構築していくことが重要だと説かれています。

また、プラットフォームチームは、開発チームを内部の顧客と捉え、彼らのワークフローに合わせてプラットフォームを設計すべきだと強調されています。
Cloud Native Computing Foundation (CNCF) は、クラウドネイティブなエコシステムを推進する団体であり、Kubernetes を含む多くのオープンソースプロジェクトをホストしています。

これらのプロジェクトを適切に組み合わせることで、ベンダーロックインを回避しつつ、柔軟なプラットフォームを構築できると説明されています。
プラットフォームエンジニアリングの役割と、その重要性についても述べられています。プラットフォームチームは、社内の開発チームを顧客と捉え、彼らが効率的にソフトウェアを開発・デリバリーできるように、プラットフォームというプロダクトを提供します。
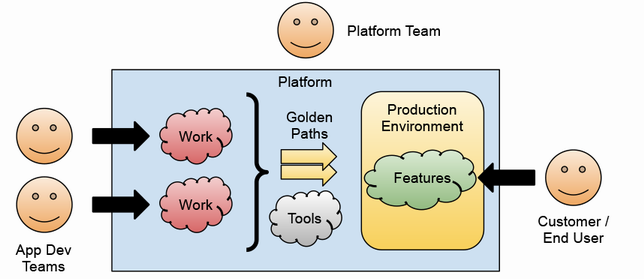
国内でもPlatform Engineering MeetupやPlatform Engineering Kaigi 2024が開催され、とても注目される分野となっています。Platform Engineeringは、開発チームが効率的にアプリケーションを開発、デプロイ、運用できるようにするための基盤を提供することを目的としています。この分野では、Kubernetesがプラットフォームの中核として広く採用されています。
自分が最初にKubernetesをプラットフォームとして認識したのは、プラットフォームの上でものを作るということを読んでからです。この記事では、Kubernetesがプラットフォームとしてどのような役割を果たすのかが詳しく解説されており、開発者がアプリケーションに集中できる環境を提供することの重要性が強調されています。
また、Kubernetesを始めたばかりで、Platform Engineeringの概念についてよく分からないという人は、k8sを始める人に知ってもらいたい、Platform Engineeringの話を読むことをおすすめします。このスライド資料では、Platform Engineeringの基本的な考え方や、Kubernetesを活用したプラットフォーム構築の手法が分かりやすく解説されています。
platformengineering.connpass.com
また、プラットフォームは単なるツールの寄せ集めではなく、開発チームのワークフローに合わせて設計され、シームレスな開発体験を提供することが求められます。
市販のプラットフォームを導入するだけでは、組織特有のニーズを満たすことは難しいと指摘されています。Red Hat OpenShift や VMware Tanzu などの製品は、一定の抽象化を提供してくれますが、それでも組織に合わせたカスタマイズが必要になるケースが多いようです。
結局のところ、自社に最適なプラットフォームを構築するためには、社内でプラットフォームエンジニアリングに取り組む必要があるということですね。本書の中にも組織の話がたくさん出てくるし、本稿でも少し組織のような話に逸れます。『DXを成功に導くクラウド活用推進ガイド CCoEベストプラクティス』は、クラウドサービスを効果的に活用し、DXを成功させるために不可欠な、自社のユースケースに適したサービスの選択・統合と社内でのクラウドエキスパートの育成について、特にリーダーシップ、ビジネス、テクノロジーを備えたクラウド活用推進組織「CCoE」の存在の重要性を強調しています。本書では、CCoEの基本概念から立ち上げ方法、課題解決方法まで、先進企業の実例を交えてわかりやすく説明しています。クラウドネイティブ時代に適応し、DXを成功させるためには、プラットフォームの構築と進化、クラウドサービスの効果的な活用、そしてCCoEの組織化が重要であり、これらの取り組みを通じて、企業は顧客により高い価値を提供し、競争力を高めていくことができるでしょう。これらの課題解決の手引きとなる一冊であり、合わせて読むのがオススメの書籍です。

本書で使用されるカンファレンスのアプリケーションの例も紹介されています。この「ウォーキングスケルトン」と呼ばれるサンプルアプリケーションは、クラウドネイティブなアーキテクチャのベストプラクティスを示すと同時に、以降の章で紹介されるプラットフォーム構築の手法を実践的に学ぶためのユースケースとして機能します。
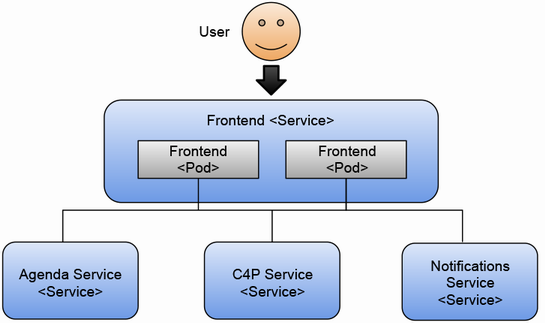
このカンファレンス用のアプリケーションは、マイクロサービスアーキテクチャに基づいて設計された Web アプリケーションであり、複数のバックエンドサービスと、それらを呼び出すフロントエンドで構成されています。

各サービスは独立して開発・デプロイできるため、チーム間の自律性を高めつつ、アプリケーション全体の柔軟性と回復性を向上させることができます。
モノリシックなアーキテクチャと、マイクロサービスアーキテクチャの違いについても説明されています。モノリシックなアプリケーションでは、すべての機能が1つのコードベースに含まれているため、スケーリングや更新に制約が生じやすくなります。

一方、マイクロサービスでは、各サービスが独立して開発・デプロイできるため、より柔軟で回復性の高いアプリケーションを構築できると説明されています。
最後に、本書で扱うプラットフォーム構築の手法が、カンファレンスのアプリケーションを例に概説されています。各章では、CI/CD、環境の管理、クラウドリソースのプロビジョニングなど、プラットフォームを構成する様々な要素が取り上げられ、それらを組み合わせることで、開発チームの生産性を高めるプラットフォームを構築していく過程が紹介されます。また、プラットフォームの効果を測定するための指標や手法にも触れられており、継続的な改善の重要性が強調されています。
第1章を通じて、プラットフォームを Kubernetes 上に構築することの意義と、そのための手法が体系的に説明されていました。特に、プラットフォームを「内製のプロダクト」と捉え、開発チームを「顧客」と見なすという視点は、DX時代における開発組織のあり方を考える上で示唆に富むものでした。これらのSREとの手法の違いについては以下のような内容で登壇したことがあります。
私自身、大規模な Web アプリケーションの開発に携わった経験から、モノリシックなアーキテクチャの限界を痛感しています。機能追加や変更に多大な時間と工数を要していたのが、マイクロサービス化を進めることで、各チームが独立して開発を進められるようになり、リリースサイクルを大幅に短縮できました。クラウドネイティブなアプリケーション開発において、マイクロサービスアーキテクチャが果たす役割の大きさを実感しています。
また、CNCF のプロジェクトを活用しつつ、自社に最適なプラットフォームを構築していくアプローチは、クラウドネイティブな開発に取り組む多くの組織にとって参考になるはずです。私自身、日々の業務の中で、クラウドネイティブな開発の推進と、それを支えるプラットフォームの構築に取り組んでいます。本書で得られる知見を活かし、自社に最適なプラットフォームを設計・運用していきたいと考えています。
著者の深い知見と経験に基づく解説は、インフラエンジニアのみならず、アプリケーション開発者やアーキテクトなど、様々な立場の読者に価値を提供してくれるでしょう。プラットフォームチームと開発チームの関係性や、CNCF の活動など、日々の業務では触れる機会の少ないトピックについても、明快に解説されていたのが印象的でした。
本書の残りの章では、このような考え方を基盤に、より具体的なプラットフォーム構築の手法が展開されていきます。第1章で示された知見は、プラットフォームエンジニアリングに携わる全ての人にとって、大きな助けになるはずです。著者の知見とバランス感覚に裏打ちされた記述は、まさにクラウドネイティブ時代の最前線に立つエンジニアならではのものです。
これからのソフトウェア開発には、プラットフォームチームと開発チームの緊密な連携が欠かせません。インフラエンジニア、SREやプラットフォームエンジニアは両者の架け橋となり、組織全体でクラウドネイティブの価値を最大限に引き出せるよう尽力しなければなりません。本書を通じて得られる知見を糧に、クラウドネイティブ時代の開発の最前線に立ち続けられるのではないでしょうか?しかし、技術的にKubernetesを完全に網羅しているわけではないので『Kubernetes完全ガイド 第2版』、『Docker/Kubernetes実践コンテナ開発入門 改訂新版』、『Kubernetes Best Practices, 2nd Edition』、『Kubernetes Patterns, 2nd Edition』などを読むと良いと思います。
2 Cloud-native application challenges
本章では、クラウドネイティブアプリケーションを開発・運用する上での実践的な課題が幅広く議論されました。
議論の出発点となったのは、アプリケーションを実行するためのKubernetesクラスター環境をどのように選択するかという点です。ローカル環境でKindを使う方法は手軽である一方、リソースに制限があり、本番環境とは異なる挙動をする可能性があることが指摘されました。Kindは、Docker上にKubernetesクラスターを起動するツールで、開発者の手元で手軽にKubernetesを体験できる利点がある反面、プロダクション環境とは異なるサイジング・設定になりがちという欠点があります。
対して、クラウドプロバイダのマネージドサービスを使えば、本番に近い環境でアプリケーションを開発できますが、コストがかかるほか、開発者がリモート環境での作業に慣れる必要があるといったトレードオフが存在します。GKE(Google Kubernetes Engine)やEKS(Amazon Elastic Kubernetes Service)などのマネージドサービスは、運用の手間を大幅に削減できる一方、クラウドベンダーの仕様に縛られるというデメリットもあります。
私も実際にKindを用いたローカル環境とGKEを用いたクラウド環境の両方を経験しましたが、著者の指摘通り、それぞれに一長一短があることを実感しています。例えば、Kindは気軽に使える反面、ノード数が限られるためスケーリングのテストには向きません。一方、GKEは本番環境に近い挙動が期待できますが、クラスターの起動に時間がかかります。開発のフェーズやチームの状況に合わせて適切な環境を選択することが重要だと改めて認識しました。

環境の選択に関する議論に続いて、Helmを使ってカンファレンスアプリケーション(PoC)をKubernetesクラスターにデプロイする方法が具体的に紹介されました。Helmは、Kubernetes上のアプリケーションを管理するためのパッケージマネージャーです。Helmでは、アプリケーションの各コンポーネントを定義した複数のマニフェストファイルを「Chart」という単位でまとめて管理します。
Helmを使うと、たった1つのコマンドで、アプリケーションの実行に必要な様々なKubernetesリソース(デプロイメント、サービス、ConfigMapなど)を一括デプロイできるのが大きな魅力です。Helmのようなツールを活用することで、複雑なマニフェストファイルを手書きで管理する手間を大幅に削減できます。また、変数化されたテンプレートを使うことで、環境ごとの設定の差異を吸収するのも容易になります。
また、デプロイ後は、kubectlを駆使して、デプロイメント、サービス、Ingressなどのリソースを詳細に調べることで、アプリケーションの動作を深く理解することができます。例えば、kubectl describe deploymentでデプロイメントの詳細情報を確認したり、kubectl logsでPodのログを追跡したりできます。
私も日頃からkubectlを多用していますが、改めてその重要性を認識しました。トラブルシューティングにおいては、kubectl describeやkubectl logsが特に有用です。Podが期待通りの状態になっていない場合、kubectl describeでPodの詳細情報を確認することで、原因を特定するための手がかりが得られることが多いです。ログに関しても、kubectl logs -fでストリーミング表示すれば、リアルタイムでアプリケーションの挙動をモニタリングできます。
アプリケーションのデプロイと動作の確認を通じて、著者はクラウドネイティブアプリケーション特有の課題についても議論を展開していたので必読だと思います。
最も重要な課題の1つが、一時的な障害が発生してもシステム全体を停止させないことです。マイクロサービスアーキテクチャでは、あるサービスで障害が発生しても、他のサービスには影響を与えないようにすることが求められます。そのためには、個々のマイクロサービスを冗長化し、一部のインスタンスが停止しても他のインスタンスが処理を引き継げるような設計が必要不可欠です。
Kubernetesでは、この要件を満たすために、マイクロサービスを複数のレプリカ(Pod)で運用することが一般的です。例えば、本章の例では、フロントエンドサービスのレプリカを2つ起動することで、一方が停止しても他方がリクエストを処理し続けられるようにしていました。Deployment(デプロイメント)リソースの「replicas」フィールドで、起動するレプリカの数を指定できます。
実際、私も過去に、あるマイクロサービスがデプロイに失敗し、全体のシステムが停止してしまった苦い経験があります。その教訓から、現在ではユーザー向けのサービスを複数のレプリカで運用するようにしています。障害の影響を最小限に抑えるには、可用性を維持しつつ、もちろん無限にお金を使えれば解決に近づく問題ではあるのでリソース消費量のバランスを取ることが肝要です。
また、レプリカ数を動的に変更できるようHPA(Horizontal Pod Autoscaler)を設定し、負荷に応じて自動的にスケールするような工夫もしています。HPAを使えば、CPUやメモリの使用率に基づいて、Pod数を自動的に増減できます。これにより、トラフィックが増大した際にもサービスのパフォーマンスを維持しつつ、利用が低調な時間帯にはリソースを節約することが可能になります。
サービス間の疎結合性を保つことも、システムの可用性を高めるための重要な要素です。あるサービスで障害が発生した際も、ユーザーが他のサービスの機能を継続して利用できるようにすることが理想的です。そのためには、各サービスが依存するサービスの障害を適切に処理し、エラーをユーザーに伝搬させないようにするなど、レジリエンスを持たせる必要があります。

著者が紹介していたように、サーキットブレーカーパターンを実装したり、適切にタイムアウトを設定したりすることが有効です。サーキットブレーカーとは、障害が発生したサービスへのリクエストを一時的にブロックし、迅速にエラーを返すことでカスケード障害を防ぐ仕組みです。また、各リクエストにタイムアウトを設定しておくことで、ダウンストリームのサービスの応答が遅い場合でもアプリケーション全体が停止するのを防げます。
加えて、私からは、Istioのようなサービスメッシュを導入し、サービス間の通信を細かく制御する方法も提案したいです。サービスメッシュは、マイクロサービス間の通信を透過的にインターセプトし、ルーティングやトラフィック管理、セキュリティ、可観測性などの機能を提供するインフラストラクチャ層です。
例えば、Istioを使えば、特定のマイクロサービスへのリクエストに対して、自動的にリトライを行ったり、エラー率が閾値を超えた際にサーキットブレーカーを発動させたりすることができます。さらに、バージョンの異なるサービスに対して、トラフィックを段階的に切り替えるカナリアデプロイメントも容易に実現できます。これらの機能により、マイクロサービスのレジリエンスとリリース管理が大きく改善されるでしょう。
ステートフルなサービスをKubernetes上で運用する際の留意点についても言及がありました。ステートフルというのは、リクエスト間で状態を保持する必要のあるサービスを指します。代表例は、データベースやメッセージキューなどです。
ステートフルサービスをコンテナとして運用する場合の課題は、Podが再起動した際にデータが失われないようにすることです。そのためには、データを永続化するためのストレージが不可欠です。Kubernetesには、各Podにボリュームを割り当てる仕組みがあり、ファイルシステムやブロックストレージ、オブジェクトストレージなど、多様なストレージをPodにマウントできます。
また、ステートフルサービスでは、Pod間でデータを同期する必要があるため、スケーリングが難しくなります。この問題に対処するため、Kubernetesには、StatefulSetというリソースが用意されています。StatefulSetを使うと、各Podに固有のネットワークアイデンティティを付与し、起動順序や停止順序を制御できます。

著者が言及していたように、データベースなどのステートフルなコンポーネントを切り出し、サービス自体はステートレスに保つことが望ましいアプローチだと言えます。例えば、ユーザーのセッション情報をRedisなどのキャッシュサーバーで管理することで、アプリケーションサーバー自体はステートレスになり、シームレスにスケールさせることができるようになります。私のチームでも同様の手法を取り入れており、大きな効果を上げています。
分散システムにおいては、データの整合性の問題も避けて通れません。マイクロサービスアーキテクチャでは、データがサービス間で分散されているため、あるサービスから見たデータの状態が、他のサービスから見た状態と異なっている可能性があります。「結果整合性」と呼ばれるこの状態は、ビジネス要件に応じて許容されるケースもあれば、強い整合性が求められるケースもあります。
いずれにせよ、データの不整合を検知し、解消するためのメカニズムが必要です。著者が提案していたのは、CronJobを使って定期的にデータの整合性をチェックする方法です。CronJobは、cron構文で記述されたスケジュールに従ってジョブ(Pod)を実行する仕組みです。例えば、毎日深夜に、各サービスのデータを突き合わせ、不整合があればアラートを上げるような運用が考えられます。

より洗練された方法としては、CDCを使って変更データをリアルタイムでキャプチャし、関連サービスに伝播させるような方法も考えられます。CDCとは、Change Data Captureの略で、データベースの変更を即座に検出し、他のシステムに通知する技術のことです。CDCを使えば、データの更新を全てのサービスに「できるだけリアルタイム」で反映させることができます。
ただし、サービス間の疎結合性という観点からは、同期的な通信は避けたほうが良いかもしれません。非同期メッセージングを使ってイベントドリブンに通信するアプローチのほうが、マイクロサービスの理想に適っているでしょう。
アプリケーションの適切な監視も、本章で大きく取り上げられたトピックでした。クラウドネイティブのアプリケーションでは、インフラからアプリケーションまで、あらゆる階層で可観測性(オブザーバビリティ)を確保することが求められます。
著者が注目していたのは、OpenTelemetryです。OpenTelemetryは、CNCF(Cloud Native Computing Foundation)が主導するオープンソースプロジェクトで、メトリクス、ログ、トレースを統合的に扱うためのフレームワークを提供しています。OpenTelemetryに準拠したライブラリやエージェントを使えば、アプリケーションのコードに変更を加えることなく、各サービスから統一的なフォーマットで可観測性データを収集できます。
収集したメトリクスは、Prometheusなどの時系列データベースに保存し、Grafanaなどの可視化ツールで分析・モニタリングするのが一般的です。

著者の主張に大いに同意します。特に、大規模なシステムになるほど、各サービスが出力するログやメトリクスを個別に追跡するのは非常に骨の折れる作業になります。OpenTelemetryのようなフレームワークを活用し、可観測性データを一元的に管理することが必要不可欠だと考えられます。
加えて、PrometheusのアラートマネージャーでSLO(Service Level Objective)を定義し、それに基づいてアラートを発報する仕組みを整えることも重要だと感じられます。SLOとは、サービスが満たすべき具体的な指標のことで、可用性やレイテンシーに関する目標値を定量的に表したものです。SLOに対する違反が発生した際に適切にアラートが上がるようにしておくことで、障害の検知と対応を迅速に行えるようになります。
本章で取り上げられた課題は、いずれもクラウドネイティブアプリケーションの開発において避けては通れないものばかりです。個々の課題にベストプラクティスで対処することに加えて、著者は課題の根本的な解決のためには"プラットフォームエンジニアリング"の実践が不可欠だと述べています。
つまり、開発者がアプリケーションのコア機能の開発に専念できるよう、ビルド、デプロイ、運用などに関わる様々なプラットフォーム機能を自動化し、効率化することが求められるのです。
プラットフォームチームによる自動化の推進は、開発チームの生産性を大きく向上させることが期待できます。一方で、プラットフォームチームと開発チームのコミュニケーションは欠かせません。開発者のフィードバックを受けて、継続的にプラットフォームを改善していくことが肝要だと言えるでしょう。
クラウドネイティブアプリケーションの課題を可視化し、プラットフォームエンジニアリングの必要性を明らかにした本章の議論は示唆に富むものでした。著者の知見を参考にしながら、開発者体験の向上と、より信頼性の高いシステムの構築を目指していくことが重要だと感じました。また、プラットフォーム自動化の取り組みを通じて、チーム全体の生産性を高めていくことも大きな目標になるはずです。
次章以降では、より具体的なプラクティスが順次展開されるとのことです。クラウドネイティブの世界の最前線で活躍するエンジニアの知恵を学べる良い機会だと思います。本章で得られた知識を土台として、より実践的なスキルを身につけていくことが望まれます。
カンファレンスアプリケーション(PoC)を題材に、プラットフォームの構築からアプリケーションの継続的デリバリーまでを一気通貫で学べるのは、他書にはない本書の大きな魅力だと感じました。
本章では実際に手を動かしながら学べる内容が豊富でした。Helmを使ったデプロイ、kubectlを用いたトラブルシューティング、Deploymentの設定など、クラウドネイティブアプリケーションに携わる上で必須のスキルを体験的に学ぶことができたのは非常に有益でした。
もちろん、著者も強調していたように、これらはあくまで基礎の一部に過ぎません。実際のプロダクション環境では、もっと複雑で予期せぬ事態が起こりうるでしょう。そうした事態にも柔軟に対応できるよう、本書で得た知見を活かしつつ、継続的にスキルを磨いていくことが肝要だと感じました。
著者の豊富な知識と経験に基づいた本書を通じて、DevOpsの文化を組織に根付かせ、高品質なソフトウェアを継続的に提供できるチームを作り上げていくための多くの学びが得られることを期待したいと思います。Engineering Managementの観点からも、示唆に富む章になっています。
3 Service pipelines: Building cloud-native applications
本章では、クラウドネイティブアプリケーションの継続的デリバリーを実現するための要となるサービスパイプラインについて、非常に深く掘り下げた議論が展開されていました。
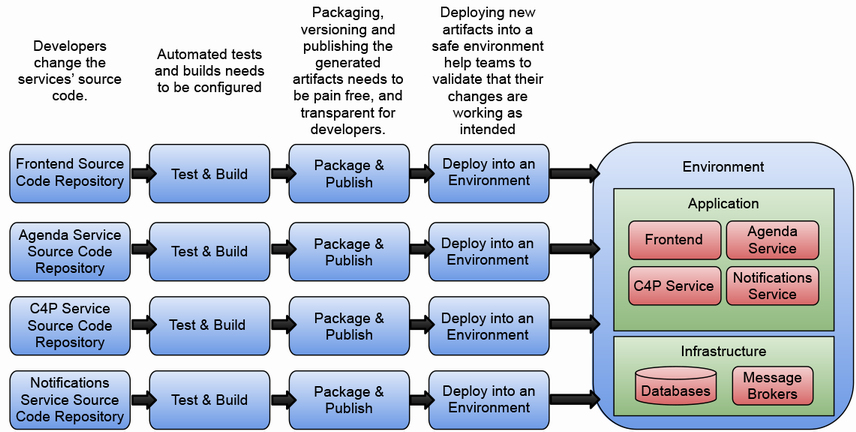
サービスパイプラインとは、ソースコードから複数の環境にデプロイ可能なリソースを生成するまでのプロセスを定義するものです。trunk-basedな開発や、1サービス=1リポジトリという実践を行うことが、チームがソフトウェアのビルドとリリースを効率的に標準化するのに役立ちます。
しかし、これはあくまで一般論であって、実際にはチームやアプリケーションに合ったやり方を見つける必要があります。万能の解決策などなく、トレードオフを考えなければならない場面も多いでしょう。アプリケーションを構成するサービスがどのくらいの頻度で変更されるのか、それらのサービスをどのように各環境にデプロイしていくのか。こうした問いに答えることで、サービスパイプラインの始点と終点を定義しやすくなります。
例えば、UIを担うフロントエンドサービスの変更は、バックエンドのAPIに比べてより頻繁に行われるかもしれません。

そうした場合、フロントエンド側のパイプラインは、できるだけ軽量でシンプルなものにしておく必要があります。頻繁なリリースサイクルに対応するため、ビルドやデプロイのプロセスを自動化し、効率化することが重要です。また、フロントエンドの変更がバックエンドに与える影響を最小限に抑えるため、両者の間にはしっかりとしたインターフェース定義が必要となります。

一方、ビジネスロジックの中核を担うようなバックエンドサービスのパイプラインは、より厳格で、各種テストも充実させておく必要があるでしょう。バックエンドは、システムの根幹を成すコンポーネントであり、その品質と信頼性は非常に重要です。そのため、単体テスト、統合テスト、負荷テストなど、様々な観点からのテストを実施し、バグや脆弱性を早期に発見・修正することが求められます。また、バックエンドの変更は、他のサービスに広範な影響を与える可能性があるため、慎重にバージョン管理し、必要に応じてロールバック可能な状態を維持しておくことも大切です。
このように、フロントエンドとバックエンドでは、その役割や特性に応じて、パイプラインの設計や運用方針を適切に調整することが重要です。こうした違いを意識しつつ、それぞれのサービスに適したパイプラインを設計していく。これは、サービスの独立性を確保しつつ、開発・リリースプロセス全体の効率を高める上で非常に重要なことだと言えます。
マイクロサービスアーキテクチャが主流となる中で、サービスの独立性を担保しつつ、リリースプロセス全体の効率化を図る上で、サービスパイプラインは欠かせない存在です。サービスパイプラインを適切に設計し、運用することが、クラウドネイティブな開発の成功の鍵を握ると言っても過言ではありません。

著者は、サービスパイプラインを効果的に機能させるためのベストプラクティスをいくつも提示しています。例えば、trunk-based developmentを採用し、メインブランチを常にデプロイ可能な状態に保つことです。これにより、いつでもリリースができる状態を維持しつつ、変更を小さくすることで、リスクを最小限に抑えられます。
また、メインブランチへのマージを厳格に管理することも重要です。レビューを徹底し、自動化されたテストをパスしたコードのみを受け入れるルールを設ける。これにより、メインブランチの品質を常に高く保てるはずです。
加えて、Consumer-Driven Contract (CDC) テストの重要性も強調されていました。マイクロサービス間の依存関係を、テストとして明示的に管理することで、あるサービスの変更が他のサービスに与える影響を最小限に食い止められるのです。
CDCテストでは、あるサービス(Consumer)が依存するサービス(Provider)のAPIについて、期待する振る舞いを契約(Contract)として定義します。そしてその契約に基づいて、自動テストを生成するのです。
これにより、Providerの実装が変更されても、Contract自体が守られている限り、Consumerには影響が及ばないことが保証されます。この手法は、マイクロサービス間の結合度を適切な形に保つ上で、非常に有効だと言えるでしょう。
CDCテストを導入することで、各チームは自分たちのペースでサービスを進化させつつ、他のチームに与える影響を最小限に抑えられます。これは、マイクロサービスアーキテクチャのメリットを最大限に引き出すための重要な実践だと言えます。
こうしたプラクティスは、単に技術的なものではありません。チーム間のコミュニケーションを円滑にし、リリースに関わる様々なステークホルダーの協調を促すことにも寄与します。サービスパイプラインを設計する際には、常にチームとプロセスに与える影響を考慮する必要があるでしょう。
さらに、個々のサービスのライフサイクルに合わせて、パイプラインを柔軟に調整することの重要性も説かれていました。画一的な基準を全てのサービスに適用するのではなく、変更頻度や重要度に応じて最適化していくことが求められます。
例えば、ユーザーに対するインターフェースとなるフロントエンドのサービスは、UIの変更が頻繁に行われるかもしれません。一方で、システムの根幹を支えるようなバックエンドサービスは、安定性が何より重視されるはずです。
こうした特性の違いを踏まえて、フロントエンドのサービスにはより軽量で実行頻度の高いパイプラインを、バックエンドのサービスにはより厳格でステップの多いパイプラインを適用する、といった工夫が考えられます。要は、サービスの特性に合わせてパイプラインをチューニングしていくことが肝要だということですね。
そのためには、各サービスがどのような特性を持ち、どのようなペースで変更が行われるのかを深く理解する必要があります。開発チームとの密なコミュニケーションを通じて、サービスの性質を見極めていくことが重要だと言えるでしょう。
また、パイプラインを定義する際には、コードとしての管理が鍵になります。アプリケーションのコードと同様に、パイプラインのコードもバージョン管理し、再利用性や保守性を高めていく必要があるのです。
そのためには、Dockerfileやデプロイメント用のマニフェストなど、パイプラインに関わる全てのリソースをコードとして扱うことが重要になります。つまり、Infrastructure as Codeの思想を、パイプラインにも適用するということですね。
これは、単にパイプラインの品質を高めるだけでなく、アプリケーションの運用方法を明確に可視化することにも繋がります。コードを見れば、そのアプリケーションがどのようにビルド・デプロイされるのかが一目瞭然になるのです。
特に、新しくチームに参加したメンバーのオンボーディングを助ける効果は大きいでしょう。パイプラインのコードがドキュメントの役割を果たし、アプリケーションの動作原理の理解を助けてくれるはずです。
加えて、コード化されたパイプラインは、単なる自動化の手段ではありません。それは、チームのエンジニアリング文化そのものを表現するものだとも言えます。
例えば、パイプラインにどのような品質ゲートを設けるのか、どの段階でレビューを行うのか、といった点は、チームの価値観や理念を反映したものになるはずです。
つまり、パイプラインをコード化することは、チームのエンジニアリングプラクティスを明文化し、共有することでもあるのです。それによって、チームのスキルやノウハウの継承がスムーズになり、組織としての開発力の底上げにも繋がります。
本章では、Tekton、Dagger、GitHub Actionsなど、パイプラインを実装するためのツールについても詳しく解説されていました。それぞれのツールの特性を理解し、自身のコンテキストに合ったものを選択することが重要だと感じました。
GitHubが提供するGitHub Actionsのようなマネージドサービスを利用するのも一つの選択肢です。インフラの管理は全てGitHubに任せられるため、初期コストを大幅に下げられます。ただし、実行時間に応じた従量課金制のため、大規模なワークロードを流し続けるとコストが高くつく可能性もあります。
プラットフォームを構築する立場からは、GitHub Actionsのような便利なツールだけに頼るのではなく、自社に最適化されたタスクやパイプラインを柔軟に作れるツールを選ぶ必要があるでしょう。また、開発者がローカルでパイプラインを実行できるようにしておくことも、DXを高める上で重要なポイントになります。
せっかくパイプラインを自動化しても、毎回クラウドにデプロイしないと動作確認ができないようでは、開発者の生産性は大きく損なわれてしまいます。開発者のフィードバックサイクルを如何に短くできるかは、パイプラインツールの選定において考慮すべき大切な視点だと言えるでしょう。
例えばTektonは、Kubernetesとの親和性が高く、宣言的なパイプラインの定義が可能です。Kubernetesのカスタムリソースとしてパイプラインを表現できるため、他のKubernetesリソースとの連携が容易だというメリットがあります。
また、Tektonには豊富なコミュニティ貢献のタスクが用意されているのも魅力の一つです。Tekton Hubと呼ばれるカタログサイトから、再利用可能なタスクを検索し、自分のパイプラインに組み込むことができます。
これらのタスクは、Kubernetesのエキスパートたちによって作られ、ベストプラクティスが詰め込まれています。それらを活用することで、信頼性の高いパイプラインを素早く構築できるでしょう。
一方、Daggerは、プログラミング言語でパイプラインを記述できるため、より動的で複雑な処理を表現しやすいという特徴があります。Go、Node.js、Python、Javaなど、様々な言語のSDKが提供されているのも、開発者にとって嬉しいポイントだと言えます。
言語の持つ柔軟性を活かして、条件分岐や繰り返し処理を含む高度なパイプラインを実装できます。また、言語のエコシステムを活用して、外部ライブラリとの連携も容易です。
例えば、テストの実行結果をSlackに通知したり、カスタムスクリプトを組み込んだりといったことが、シームレスに行えるでしょう。
また、Daggerの大きな特長は、ローカル環境でもそのままパイプラインを実行できる点にあります。手元の環境で簡単にパイプラインの動作検証ができるため、開発者の生産性が大きく向上するでしょう。
クラウド上の環境を完全に再現するのは難しくても、パイプラインのコアとなるロジックは、ローカルで十分にテストできるはずです。これにより、クラウドへのデプロイ回数を減らし、無駄なコストを削減できます。
また、ローカルでパイプラインを実行できれば、開発中のアプリケーションに合わせて、パイプラインを柔軟にカスタマイズしていくことも容易になります。
チームのスキルセットや、アプリケーションのアーキテクチャによって、適切なツール選定は変わってくるでしょう。一つの正解があるわけではありません。重要なのは、チームにとって最も生産性の高い方法を追求し続けることだと感じました。
さらに、ローカル環境でのパイプラインの実行も、開発者の生産性を大きく左右する要素として挙げられていました。クラウド上の環境を完全に再現するのは難しくとも、手元で気軽にパイプラインを実行できれば、圧倒的にフィードバックループが早くなるはずです。
加えて、コードとして表現することで、より柔軟なパイプラインの実現も可能になります。単なるYAMLの設定ファイルでは表現しきれないような、動的なロジックを組み込むこともできるはずです。例えば、あるサービスのテスト結果を受けて、別のサービスのデプロイを条件付きでスキップする、といったことも可能になるでしょう。
この柔軟性は、マイクロサービスの独立性を担保する上でも重要な意味を持ちます。あるサービスの障害が、他のサービスのデプロイを止めてしまうようでは、真の意味でのマイクロサービスとは言えません。
パイプラインを通じて、各サービスのライフサイクルを適切に制御することが、マイクロサービスアーキテクチャを成功に導く鍵だと言えるでしょう。

このように、サービスパイプラインを適切に定義し、運用していくことは、クラウドネイティブなアプリケーション開発において欠かせない実践だと言えます。そのためのツールの選定は、単に機能や性能だけでなく、開発者のエクスペリエンスや、チームのカルチャーとの親和性など、多面的な視点から行う必要があります。

パイプラインを実行するためには、図にあるように、様々なインフラの整備が必要不可欠です。各種リポジトリ、コンテナレジストリ、Kubernetesクラスターなど、多岐にわたるコンポーネントを連携させる必要があります。
これらのインフラを個別のプロジェクトごとに構築するのは非常に非効率です。コストや管理の手間を考えると、組織横断で共有できるプラットフォームとして提供するのが望ましいでしょう。
そこで重要になってくるのが、プラットフォームチームの存在です。プラットフォームチームは、開発チームが利用しやすいパイプラインのテンプレートを用意し、ベストプラクティスをコード化して提供します。
具体的には、言語ごとのビルドやテストのツールセット、デプロイに必要なマニフェストの生成ロジックなどを、プラットフォームとして標準化するのです。開発チームはそれらを利用しつつ、各アプリケーションに特化した処理を付け加えていけば良いでしょう。
こうすることで、開発チームは本質的なロジックの実装に集中でき、しかも一定の品質を担保されたパイプラインを利用できるようになります。まさに、プラットフォームが提供すべき価値だと言えます。
一方で、全てのアプリケーションに対して、一律のパイプラインを適用するのは現実的ではありません。例えば、レガシーなシステムをマイクロサービス化する過程では、新旧のサービスが混在することになります。
レガシーなサービスに対しては、従来のビルドツールやデプロイ手法を踏襲せざるを得ないかもしれません。そうした例外に対しては、プラットフォームチームが柔軟に対応し、段階的な移行をサポートしていく必要があります。
究極的には、パイプラインのコードを通じて、プラットフォームと開発チームのコラボレーションを促進することが肝要です。開発チームはアプリケーションに関する知見を、プラットフォームチームはインフラに関する知見を持ち寄り、パイプラインの継続的な改善を進めていく。それこそが、クラウドネイティブ時代のDevOpsの理想形と言えるでしょう。
本章を通じて、改めてサービスパイプラインの重要性と、その構築の難しさを実感しました。単なるツールの選定や設定の問題ではなく、開発プロセス全体に関わる設計が求められるのです。
組織の文化や、開発チームの成熟度なども考慮しなければなりません。画一的な答えはなく、試行錯誤を重ねながら、自社に最適な形を模索していく必要があります。そのためには、プラットフォームチームと開発チームの密なコラボレーションが不可欠です。
サービスパイプラインは、エンジニアリングの課題であると同時に、組織の課題でもあるのだと、強く認識させられる内容でした。
また、パイプラインのコード化の重要性は、開発者としての自分の仕事の進め方にも示唆を与えてくれました。テストやデプロイの方法をコードの一部として捉え、アプリケーションと一体になったものとして扱うこと。それによって、より俯瞰的に開発プロセスを捉えられるようになるはずです。
さらに、パイプラインのコード化は、アプリケーションの品質を長期的に担保していく上でも重要な意味を持ちます。メンバーが入れ替わっても、その時点での最良のプラクティスが脈々と受け継がれていく。まさに、継続的インテグレーション・継続的デリバリーの価値を体現するものだと言えるでしょう。
ちなみに、著者は継続的デリバリーに関する優れた書籍として、「Continuous Delivery」と「Grokking Continuous Delivery」の2冊を挙げていました。私も特に「Grokking Continuous Delivery」は非常に分かりやすく、お勧めの一冊です。継続的デリバリーの考え方や、パイプラインの設計方法について、体系的に学ぶことができます。
クラウドネイティブの世界で開発者として生きていく上で、サービスパイプラインをどう構築・活用していくかは避けて通れない問題です。ただツールを選ぶだけでなく、自分たちの開発文化そのものを設計する。そんな広い視野を持つことの大切さを、本章は教えてくれました。
もちろん、これは簡単なことではありません。日々の開発タスクに追われる中で、パイプラインまで手が回らないというのが正直なところでしょう。
だからこそ、プラットフォームチームの役割が重要になってくるのです。現場の開発者の負担を減らしつつ、ベストプラクティスの採用を促していく。そのための仕組みと文化を育てていくことが、プラットフォームチームに求められる使命だと言えます。
理想的なサービスパイプラインの姿は、組織によって異なるでしょう。どこを目指すのか、そのために何をすべきかは、組織の状況に応じて見極めていかなければなりません。
ただ、開発者として心に留めておきたいのは、サービスパイプラインの構築は、決して他人事ではないということです。自分たちで作ったアプリケーションを、自分たちの手でより良い形でお客様に届けるために、パイプラインを日々改善していく。そんな当事者意識を持つことが、クラウドネイティブ時代のソフトウェアエンジニアに求められているのだと感じます。
その意味で、本章はサービスパイプラインについての技術的な知見だけでなく、開発者としてのマインドセットを見つめ直すためのヒントも与えてくれました。著者の知見に導かれながら、自分なりのベストプラクティスを追求していきたいと思います。
継続的デリバリーの実現は、一朝一夕にはいきません。しかし、その過程で得られる学びは、エンジニアとしての成長に直結するはずです。プラットフォームチームと開発チームが一丸となって、理想のパイプラインを追求していく。そのために、一人一人が当事者意識を持って臨むことが何より大切だと、本章を読んで強く感じました。
本章の内容は、そのための第一歩を踏み出すための勇気と知見を与えてくれるはずです。著者の経験に基づく生きたアドバイスの数々は、きっと読者の心に響くことでしょう。
理想的なパイプラインを構築するのは簡単ではありませんが、その過程で得られる学びは計り知れません。失敗を恐れず、仮説検証を繰り返しながら、自分たちなりのベストプラクティスを追求していく。そうした探求心こそが、エンジニアを駆り立てる原動力になるはずです。
本書の主題である"プラットフォームエンジニアリング"も、そうした探求の先に見えてくるものだと感じています。開発者とインフラの垣根を越えて、アプリケーションとプラットフォームが一体となった開発スタイルを確立する。それはまさに、クラウドネイティブ時代のソフトウェア開発の理想形と言えるでしょう。
本章はそのためのロードマップを提示してくれました。読者の皆さんには、ぜひ自分たちなりのサービスパイプライン構築に挑戦してみてください。きっと、開発者としての新たな可能性に気づくことができるはずです。
4 Environment pipelines: Deploying cloud-native applications
本章では、サービスパイプラインによって生成されたリソースを実際の環境にデプロイするための「パイプライン」について深く掘り下げられていました。私たちが作り上げたアプリケーションが真の価値を生むのは、それが実際のユーザーに届けられて初めて可能になります。そのためには、開発環境から本番環境まで、様々なステージを経由しながら、アプリケーションを安全かつ確実にデプロイしていく必要があります。この一連のプロセスを自動化し、信頼性と再現性を担保するのが、パイプラインの役割だと言えるでしょう。例のGitOpsのページが移動されたのでGoogle Cloudさんのページを公開しておきます。
著者は特に、GitOpsの考え方を取り入れることの重要性を強調していました。GitOpsとは、環境の設定をコードとして管理し、Gitリポジトリを信頼できる唯一の情報源として扱う手法のことを指します。つまり、インフラストラクチャのあるべき状態を宣言的に記述し、それをGitで管理するのです。GitOpsに従えば、環境の状態は常にGitリポジトリの内容と同期されていなければなりません。環境に変更を加えるには、Gitリポジトリに対してプルリクエストを発行し、レビューを経てマージするというプロセスを踏むことになります。

これにより、変更の履歴が追跡可能になるだけでなく、問題が発生した際にはすぐに前のバージョンに戻せるようになります。また、設定のドリフトを防ぎ、環境間の一貫性を保つことも容易になるのです。インフラストラクチャの状態をコードで表現することで、それを他の人と共有したり、レビューしたりすることが可能になります。つまり、インフラストラクチャの変更も、アプリケーションコードの変更と同様に、プルリクエストベースのワークフローに乗せられるようになるのです。
GitOpsを実装するためのツールとして、本章ではArgo CDが紹介されていました。Argo CDは、Kubernetes向けの継続的デリバリーツールであり、GitリポジトリとKubernetesクラスターを監視し、両者の状態を同期し続けてくれます。具体的には、Gitリポジトリに格納されたマニフェストファイルを読み取り、それをKubernetesクラスターに適用するのです。もし、クラスターの状態がマニフェストファイルの内容と異なっていれば、Argo CDが自動的にそれを修正してくれます。
また、Argo CDは直感的なWebインターフェースを提供しており、そこからデプロイメントの状況をビジュアルに把握できます。どのアプリケーションがどのバージョンで動いているのか、そのヘルスステータスはどうなっているのかなどを一目で確認できるのは、オペレーションの効率化に大きく寄与するでしょう。
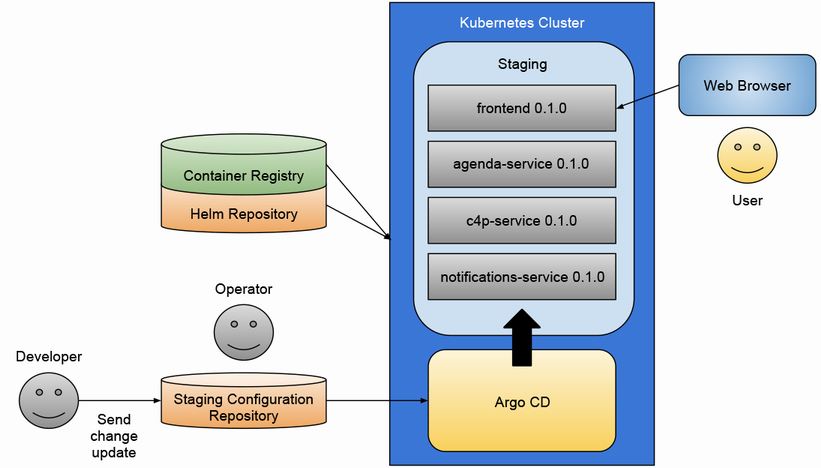
Argo CDとHelmを組み合わせることで、より強力なGitOpsのワークフローを実現できます。Helmは、Kubernetesのパッケージマネージャーであり、アプリケーションの設定値をパラメータ化し、テンプレート化することができます。つまり、Helmを使えば、同じアプリケーションを異なる環境に、異なるパラメータセットで展開することが容易になるのです。
Argo CDは、このHelmチャートも管理対象とすることができます。Gitリポジトリに格納されたHelmチャートを読み取り、それをKubernetesクラスターにデプロイするのです。この組み合わせにより、アプリケーションの設定とインフラストラクチャの設定を、一元的にコードで管理することが可能になります。
本書のステップバイステップのチュートリアルでは、実際にArgo CDとHelmを使って、サンプルアプリケーションをKubernetesクラスターにデプロイする手順が丁寧に解説されていました。これを通じて、GitOpsの実践的なスキルを身につけることができたのは、大変貴重な経験となりました。
パイプラインは、ソフトウェアリソースを本番環境にデプロイする責務を負っています。パイプラインにより、チームが直接クラスターを操作する必要がなくなり、エラーや設定ミスのリスクを減らせます。また、環境の更新後には、きちんと動作確認を行う必要があります。
Argo CD のようなツールを使えば、各環境の内容をGitリポジトリで定義し、信頼できる唯一の情報源として扱うことができます。Argo CD は、クラスターの状態を追跡し、適用された設定にドリフトが発生していないことを保証します。開発チームは、環境で実行されているサービスのバージョンを、環境設定のリポジトリにプルリクエストを発行することでアップグレード・ダウングレードできます。変更はレビューを経てマージされ、承認されれば即座に環境に反映されます。問題が発生した場合は、Gitのコミットを元に戻すことで、ロールバックが可能です。
パイプラインは、私たちの開発プロセスに多くのメリットをもたらしてくれます。まず、環境への直接的な干渉を排除し、設定ミスや不整合によるトラブルを防ぐことができます。手作業によるミスを減らし、オペレーションを自動化・標準化できるのです。
また、環境の設定を統一的に管理することで、本番環境の再現や、新しい環境の立ち上げを容易にします。テスト環境や、開発者一人ひとりの環境を、本番と同じ構成で簡単に作れるようになるでしょう。このことは、「本番で動くから大丈夫」という過信を排除し、より早い段階で問題を発見・解決することにつながります。
加えて、変更管理のプロセスを明確にすることで、開発チーム間のコミュニケーションとコラボレーションを促進します。インフラストラクチャの変更も、アプリケーションの変更と同列に扱われ、レビューの対象になる。これにより、開発者とオペレータの境界が曖昧になり、両者の理解が深まっていくはずです。
パイプラインは、アプリケーションの信頼性と安定性を支える重要な基盤であると同時に、開発者のワークフローを改善する強力な手段でもあるのです。適切に実装・運用されたパイプラインは、ビジネススピードを加速し、イノベーションを促進してくれるでしょう。
一方で、パイプラインの導入には、一定のコストと学習曲線が伴うことも事実です。GitOpsの考え方に基づいて環境を設計し、適切なツールを選定し、チームの文化を変革していくには、時間と努力が必要となるでしょう。単に新しいツールを導入すれば良いというものではなく、それを活用するためのスキルセットやマインドセットを、チーム全体で醸成していかなければなりません。
特に、Kubernetesのようなモダンなプラットフォームを前提としたパイプラインでは、従来のオペレーションとは異なるスキルが要求されます。コンテナやオーケストレーションの知識はもちろん、インフラストラクチャをコードで管理するためのプラクティス、つまりInfrastructure as Code (IaC)についても習熟が必要です。
また、GitOpsは強力なプラクティスである一方、万能ではありません。例えば、データベースのスキーマ変更のように、ステートフルで複雑な処理をどう扱うかは、頭を悩ませる問題です。すべてをGitOpsでカバーしようとするのではなく、他のアプローチと適切に組み合わせていくことが肝要でしょう。
しかし、長期的な視点に立てば、その投資は必ず報われるはずです。パイプラインを通じて得られる俊敏性と安定性は、ビジネスの成功に直結する重要な要因になると私は確信しています。変化の激しい現代のビジネス環境において、いかに素早く、安全に価値を届けられるかが、競争力の源泉になるのですから。
パイプラインは、クラウドネイティブなアプリケーション開発において欠かせない要素です。単純な自動化の仕組み以上に、それは私たちの開発文化そのものを変革する起爆剤にもなり得ます。サービスパイプラインとパイプラインが織りなす継続的デリバリーの世界。そこには、より柔軟で、より俊敏で、より確実なソフトウェア開発の未来が広がっているのです。
本章を通じて、パイプラインの真価と、それを実装するための具体的な方法論を学ぶことができました。GitOpsという新しいアプローチは、私にとって目から鱗が落ちる思いでした。単にツールを導入するだけでなく、宣言的にインフラストラクチャを記述し、それを中心にワークフローを回していく。そうしたマインドセットの変革の必要性を強く感じさせられました。
Kubernetesという土壌の上に、Argo CDやHelmを駆使して、信頼性と速度を兼ね備えたデリバリーパイプラインを築く。本章は、そのための道標となってくれるはずです。私たち一人ひとりが、チームやプロジェクトの文脈に合わせてこの知見を咀嚼し、パイプラインをどう実装していくか。そこには正解はなく、試行錯誤の連続になるかもしれません。
レビューを経ずにインフラストラクチャの変更が行われたり、手動での作業が残っていたりと、理想とする状態には程遠いのが実情でしょう。しかし、だからこそDevOpsの実践が求められているのだと、私は考えます。パイプラインは、開発者とオペレータの協力を促し、継続的な改善を導く強力な仕組みです。それを通じてチームのフィードバックループを回していくことが、私や私たちに課せられた使命だと言えます。
ステップバイステップのチュートリアルを実践して、Argo CD を用いてGitOpsの考え方に基づいたデプロイを体験できました。はじめは小さなスコープから始めて、徐々にカバレッジを広げていくのが良いかもしれません。
5 Multi-cloud (app) infrastructure
本章では、クラウドネイティブアプリケーションのインフラストラクチャをマルチクラウド環境で管理する上での課題と、それを解決するためのアプローチについて詳細に解説されていました。マイクロサービスアーキテクチャの普及により、アプリケーションを構成する各サービスは、データベースやメッセージブローカーなどの依存コンポーネントを必要とするようになりました。これらのコンポーネントをクラウドプロバイダー固有の方法で構築・運用すると、ベンダーロックインの問題が生じ、アプリケーションのポータビリティが損なわれます。つまり、あるクラウドプロバイダーで構築したアプリケーションを、別のクラウドプロバイダーに移行することが難しくなるのです。
この問題を解決するために、筆者はKubernetes APIとCrossplaneの活用を提案しています。Crossplaneは、Kubernetesのエコシステムの一部として開発されたオープンソースのプロジェクトで、主要なクラウドプロバイダーのリソースをKubernetesのカスタムリソースとして管理することができます。Crossplaneを使うことで、クラウドプロバイダーに依存せずにインフラをプロビジョニングできるため、マルチクラウド戦略を推進する上で非常に重要な役割を果たします。
Crossplaneの中核となる機能が、Composite Resource Definitions(XRDs)です。XRDsは、Kubernetesのカスタムリソースを定義するための仕組みで、ドメイン固有の概念をKubernetesのオブジェクトとして表現できます。例えば、"Database"や"MessageQueue"といったアプリケーションが必要とするコンポーネントを、XRDsを通じて抽象化することができます。プラットフォームチームは、XRDsを適切に設計することで、アプリケーションチームが必要とするリソースを宣言的に要求できるインターフェースを提供します。
XRDsを定義する際には、アプリケーションチームのニーズを的確に捉えることが重要です。単に技術的な観点からリソースを抽象化するのではなく、アプリケーションチームがどのような概念で infrastructure as code を考えているのかを理解する必要があります。例えば、あるアプリケーションチームは "Database" というリソースを、「リレーショナルデータベースであること」「高可用性を備えていること」「自動バックアップが設定されていること」といった特性を持つものとして捉えているかもしれません。一方、別のチームは "Database" を、「ドキュメント指向のデータベースであること」「スキーマレスであること」「地理的に分散されたレプリケーションを備えていること」といった特性を持つものとして考えているかもしれません。
プラットフォームチームは、これらの異なる要求を抽象化し、統一的なインターフェースを提供する必要があります。つまり、XRDsの設計には、アプリケーションチームとのコミュニケーションと、ドメインの深い理解が不可欠なのです。また、XRDsを定義する際には、将来の拡張性も考慮しなければなりません。アプリケーションチームのニーズは常に変化するため、XRDsもそれに合わせて進化させる必要があります。したがって、XRDsの設計はアプリケーションチームとの継続的な対話を通じて、段階的に洗練させていくべきものだと言えます。
XRDsに対応するCompositionの設計も、同様に重要です。Compositionは、XRDsによって定義されたリソースを、実際のクラウドプロバイダー上のリソースにマッピングするための仕組みです。つまり、Compositionは、XRDsとクラウドプロバイダーの間の橋渡しの役割を果たします。Compositionを定義する際には、クラウドプロバイダーのサービスやAPIに関する深い知識が必要になります。
例えば、あるCompositionでは、XRDsで定義された "Database" リソースを、Amazon RDSのPostgreSQLインスタンスにマッピングするかもしれません。その際、RDSインスタンスの作成に必要なすべてのパラメータ(インスタンスクラス、ストレージサイズ、ネットワーク設定など)を、XRDsで指定されたパラメータから適切に設定しなければなりません。また、RDSインスタンスに付随するその他のリソース(セキュリティグループ、モニタリング設定、バックアップ設定など)も、同時に作成・設定する必要があります。
これらのリソースの作成や設定には、AWSのAPIやSDKを使用することになります。したがって、Compositionの設計には、クラウドプロバイダーのAPIやSDKに関する知識と、それらを効果的に活用するためのプログラミングスキルが求められます。また、クラウドプロバイダーのベストプラクティスやレコメンデーションにも精通している必要があります。例えば、AWSには、Well-Architectedフレームワークというベストプラクティスの集大成がありますが、Compositionの設計はこれに沿ったものであるべきです。
さらに、Compositionの設計には、運用面での考慮も欠かせません。作成したリソースを適切にモニタリングし、問題が発生した際には速やかに検知・通知できる仕組みを用意しなければなりません。また、リソースの変更管理やバージョン管理、ロールバック機能なども必要になります。これらの運用機能は、クラウドプロバイダーのサービスを活用することで実現できる場合もありますが、Compositionレベルでの抽象化が必要なケースもあるでしょう。
加えて、Compositionではインフラストラクチャのコストの最適化も考慮する必要があります。クラウドプロバイダーのサービスは、そのほとんどが従量課金制で提供されています。したがって、Compositionで作成するリソースのスペックや数量を適切に設定し、不要なコストが発生しないように注意しなければなりません。そのためには、アプリケーションの要件を正確に把握し、それに見合ったリソースを過不足なくプロビジョニングすることが求められます。
以上のように、XRDsとCompositionの設計には、アプリケーションドメインに関する知識、クラウドプロバイダーのサービスやAPIに関する知識、プログラミングスキル、運用スキル、コスト最適化のスキルなど、多岐にわたる専門性が必要とされます。つまり、プラットフォームチームには、従来のインフラストラクチャの管理とは異なるスキルセットが求められるのです。
特に、クラウドプロバイダーのサービスやAPIは常に進化し続けているため、プラットフォームチームはそれらの変化に追随し続ける必要があります。新しいサービスや機能が登場した際には、それらをどのようにCompositionに取り込むか、XRDsのインターフェースにどう反映するかを検討しなければなりません。つまり、Crossplaneを活用したプラットフォームの構築は、継続的な学習と改善のプロセスだと言えます。
また、プラットフォームチームは、アプリケーションチームとインフラストラクチャチームの間に立つ存在でもあります。両チームの要求や制約を理解し、それらを適切にXRDsやCompositionに反映していく必要があります。つまり、プラットフォームチームには、技術的なスキルだけでなく、コミュニケーション能力やコーディネーション能力も求められるのです。
Crossplaneは、GitOpsとの親和性も高いことが特徴の一つです。XRDsで定義されたリソースは、Kubernetesのマニフェストファイルと同様に、Git上で管理することができます。つまり、インフラストラクチャの状態をGitリポジトリで管理し、Gitのワークフローに乗せることで、インフラストラクチャの変更を宣言的に管理できるのです。
GitOpsを採用することで、インフラストラクチャの変更は、Gitリポジトリへのコミットとして表現されます。したがって、変更の経緯を追跡しやすく、変更のレビューやテストも行いやすくなります。また、リポジトリの状態とクラスターの状態を常に同期させることで、インフラストラクチャの状態のドリフトを防ぐこともできます。
GitOpsとCrossplaneを組み合わせることで、アプリケーションのデプロイメントパイプラインにインフラストラクチャの変更を統合することも可能になります。アプリケーションの変更に必要なインフラストラクチャの変更を、アプリケーションのソースコードと同じリポジトリで管理し、同じパイプラインでデプロイすることで、アプリケーションとインフラストラクチャのライフサイクルを一元的に管理できるのです。
ただし、GitOpsの実践には、独自の課題もあります。例えば、Gitリポジトリの構成をどのように設計するか、secrets の管理をどうするか、変更の競合をどう解決するかなど、運用面での検討が必要になります。また、GitOpsではインフラストラクチャの変更がコードとして表現されるため、コードのクオリティを維持するためのプラクティス(レビュー、テスト、リファクタリングなど)も必要になります。
Crossplaneを活用したマルチクラウドでのアプリケーション基盤の構築は、大きな可能性を秘めていますが、同時に多くの課題も抱えています。技術的な複雑さだけでなく、組織やプロセスの変革も必要になります。プラットフォームチームの役割と責任、アプリケーションチームやインフラストラクチャチームとの協調の在り方など、従来とは異なる体制が求められるでしょう。
また、マルチクラウド環境では、各クラウドプロバイダーの特性を理解し、それらを適切に活用することも重要です。単に複数のクラウドを使うのではなく、各クラウドの強みを生かし、弱みを補完し合うような設計が必要になります。そのためには、プラットフォームチームがクラウドプロバイダーの動向を常に把握し、最新の知見を取り入れ続けなければなりません。
さらに、マルチクラウド環境では、セキュリティやコンプライアンス、コスト管理などの課題もより複雑になります。各クラウドプロバイダーのセキュリティ機能や料金体系を理解し、それらを横断的に管理・統制する必要があります。また、クラウド間でのデータの移動や同期、可用性や性能の確保など、アーキテクチャ面での検討も欠かせません。
こうした課題を解決するには、プラットフォームチームの高度な技術力とともに、組織全体での意識改革と協調が不可欠です。アプリケーションチームは、インフラストラクチャを意識したアプリケーション設計を行う必要がありますし、インフラストラクチャチームは、アプリケーションの要件を理解した上でインフラストラクチャを提供する必要があります。また、セキュリティチームや財務チームなど、関連する他部門とのコラボレーションも重要になるでしょう。
つまり、Crossplaneを活用したプラットフォームエンジニアリングは、単なる技術的な取り組みではなく、組織文化の変革でもあるのです。siloを打破し、チーム間のコラボレーションを促進し、継続的な学習と改善を組織に根付かせること。それがプラットフォームチームに求められる重要な役割だと言えます。
本章の内容は、こうしたプラットフォームエンジニアリングの課題と可能性を、Crossplaneを中心に論じたものでした。筆者自身、日々の業務でKubernetesやCrossplaneに携わる中で、その難しさと面白さを実感しています。特に、XRDsとCompositionの設計は、奥が深く、まだまだ学ぶべきことが多いと感じています。
しかし同時に、プラットフォームエンジニアリングのもたらす価値の大きさにも気づかされました。アプリケーションとインフラストラクチャの垣根を越えて、開発と運用の連携を深化させ、ビジネスの俊敏性を高めていく。それは、DXの実現に直結する取り組みだと言えます。
もちろん、そこに至るまでの道のりは平坦ではありません。レガシーシステムとのインテグレーション、組織間の政治的な力学、既存の文化や習慣の壁など、立ちはだかる障壁は数多くあります。しかし、それでもなお、プラットフォームエンジニアリングへの挑戦は避けられないものだと感じています。
なぜなら、それは単に技術的な必然ではなく、ビジネス環境の変化に対応するための組織的な必然でもあるからです。クラウドやDevOpsの普及により、ソフトウェアがビジネスを左右する時代になりました。そんな時代に求められるのは、変化に素早く適応し、イノベーションを継続的に生み出せる組織の仕組みです。
プラットフォームエンジニアリングは、まさにそのような仕組みを実現するためのアプローチだと言えます。開発と運用の連携を高め、アプリケーションとインフラストラクチャをシームレスに扱うことで、ソフトウェア・デリバリーのスピードと質を高める。また、自動化と抽象化を進めることで、チームがよりビジネスに価値のある活動に注力できるようにする。
こうしたプラットフォームエンジニアリングの価値は、もはや特定の業界や企業規模に限定されるものではありません。クラウドネイティブの考え方は、あらゆる業界・規模の企業に浸透しつつあります。つまり、プラットフォームエンジニアリングは、どの企業にとっても無視できない重要な取り組みになりつつあるのです。
とはいえ、プラットフォームエンジニアリングは万能薬ではありません。過度な自動化や抽象化は、かえって複雑性を生み、イノベーションを阻害する可能性もあります。重要なのは、自社のコンテキストをしっかりと理解した上で、適切な段階的アプローチを取ることです。
その意味で、本書はプラットフォームエンジニアリングを進める上での良き指針になるでしょう。Crossplaneを中心とした技術的な側面だけでなく、チームの構成や文化、プロセスといった組織的な側面についても、バランス良く論じられていました。これは、プラットフォームエンジニアリングが、技術と組織の両面にまたがる取り組みだからこそ重要な視点だと感じました。
筆者自身、本章で得られた知見を日々の業務に活かしていきたいと考えています。特に、XRDsとCompositionの設計については、アプリケーションチームとのコミュニケーションを密にし、ドメインモデルを深く理解することの重要性を再認識しました。また、プラットフォームチームの在り方についても、本書で提示された視点を参考に、自社での最適な形を模索していきたいと思います。
6 Let's build a platform on top of Kubernete
Kubernetes上でのプラットフォーム構築に関する具体的な方法論と深い洞察に満ちた、非常に示唆に富む内容でした。著者は、プラットフォームエンジニアリングにおける重要な概念と実践を、豊富な事例とともに解説しています。
第6章の前半では、プラットフォームAPIの設計と、マルチクラスター・マルチテナンシーの課題が中心的に論じられています。
まず著者は、プラットフォームが Kubernetes 上で提供すべき機能を特定することの重要性を説いています。開発チームのワークフローを理解し、彼らが必要とするサービスを抽出することが、プラットフォームAPIの設計の出発点となります。ここでは、開発チームが新しい環境を要求するシナリオを例に、APIのデザインプロセスが丁寧に解説されています。
要求された環境をプロビジョニングし、アクセス情報を返却する自動化ロジックを実装することで、開発チームの生産性を大きく向上できるのです。このアプローチは、プラットフォームエンジニアリングの神髄とも言うべきものです。技術的な実装の前に、ユーザーである開発者の体験を起点に設計を進めるというマインドセットこそが、真に開発者に寄り添ったプラットフォームを生み出す鍵となります。
続く議論では、マルチクラスターおよびマルチテナントのセットアップに関する課題が取り上げられます。本番、ステージング、開発など、様々な環境を提供する必要があるKubernetesベースのプラットフォームでは、これらの課題が避けて通れません。
著者は、プラットフォーム専用のクラスターを設けることで、一貫した管理と高い可用性を実現するアプローチを提案しています。ワークロードとは分離された環境でArgoCD、Crossplaneなどのツールを用いてプラットフォームを構築することで、求められるSLOやセキュリティ要件に適切に対処できるのです。
また、マルチテナンシーの実現方法として、Namespaceによる分離と、完全に独立したクラスターによる分離のトレードオフについても、鋭い考察が展開されています。前者は手軽である一方で分離のレベルが低く、後者は強力な分離を提供する反面コストと運用負荷が大きいという、難しい選択の狭間にある課題です。
この問いに対する著者の提案が、vclusterを用いた仮想クラスターのアプローチです。1つのKubernetesクラスター内に、テナントごとに独立したコントロールプレーンを持つ仮想クラスターを動的に生成することで、Namespaceと独立クラスターの中間的な選択肢を提供できるのです。
APIサーバーレベルの分離により、テナントはクラスター全体に対する高い自由度を享受しつつ、リソースの利用効率を高められる。これは、マルチテナンシーの難しい課題に対する、エレガントな解決策の一つと言えるでしょう。
以上の議論を通じて、読者はKubernetes 上のプラットフォームがどのようなものかを具体的に理解できるようになります。プラットフォーム構築には、インフラストラクチャの設計だけでなく、開発者の体験を起点とした抽象化やAPIのデザインが不可欠だということ。そして、それを実現するためには、Kubernetesの深い理解に加え、マルチクラスター・マルチテナンシーの課題に正面から向き合う必要があるということ。第6章の前半は、そうした重要な気づきに満ちています。
第6章の後半では、これらの知見を実践的なコードとともに示した「ウォーキングスケルトン」の例が紹介されています。
ここで著者が強調するのは、Kubernetes 上にプラットフォームを構築することは、さまざまな要件を持つチームにサービスを提供するために、さまざまなツールを組み合わせる必要がある複雑なタスクだということです。Crossplane、ArgoCD、vclusterなど、多岐にわたるツールへの理解が求められます。
しかし同時に、プラットフォームはビジネス アプリケーションとしてのソフトウェア プロジェクトでもあります。主要なユーザーが誰になるかを理解することから始め、明確な API を定義することが、プラットフォームを構築する上で何を優先すべきかを決める鍵となります。技術的な側面だけでなく、開発者の体験を起点とした設計が肝要なのです。
ウォーキングスケルトンの例では、Crossplaneを用いて Environment という Custom Resource を定義し、それをKubernetesのAPIサーバーに適用するだけで、開発者はシンプルなYAMLを書くだけで必要な環境を要求できるようになります。このアプローチは、宣言的インフラストラクチャの理想を見事に体現していると言えるでしょう。コードとインフラの融合により、環境のプロビジョニングがアプリケーションデプロイメントと同じ土俵で扱えるようになるのです。
さらに、vclusterとCrossplaneを組み合わせることで、動的にテナント固有の仮想クラスターを生成する例も印象的でした。これにより、クラウド ネイティブへの移行を加速するために何を構築できるかを社内チームに示すことができます。開発者は、自分専用のKubernetes環境を手に入れつつ、プラットフォームの管理というオーバーヘッドからは開放されるという、まさにDXとインフラ効率化の両立を実現する理想的なアプローチです。
もちろん、実際のプラットフォームではより多くの要素を考慮する必要があります。とはいえ、Crossplane、ArgoCD、vclusterなどのツールを活用することで、プラットフォーム レベルでクラウド ネイティブのベスト プラクティスを促進できることは間違いありません。
ただし、ここで著者が強調しているのは、既存のツールを適切に組み合わせることの重要性です。カスタム ツールや、クラウド ネイティブ リソースの複雑な構成をプロビジョニングおよび維持する独自の方法を作成するのは避けるべきだと述べています。可能な限り、既存のツールやプラクティスを活用し、シンプルさを保つことが肝要なのです。
実際、本書のステップバイステップのチュートリアルに従うことで、Crossplane などのツールを使用して、vclusterオンデマンド開発環境をプロビジョニングする実践的な経験を得ることができます。また、本格的な Kubernetes API サーバーを操作したくない、または操作できないチームのために、簡素化された API も提供されています。これにより、開発チームの認知負荷を軽減しつつ、プラットフォームの恩恵を享受できるようになるのです。
以上のように、複数の Kubernetes クラスターの管理とテナントの分離への対処が、プラットフォーム チームの主要な課題であることを認識しつつ、適切なツールを選定し、シンプルさを保ちながら開発者の体験を向上させていくこと。それこそが、プラットフォームの成功を左右する鍵なのだと、ここからは読み取れます。
第6章の後半では、これらの知見を実践的なコードとともに示した「ウォーキングスケルトン(PoC)」の例が紹介されています。
ここで著者が強調するのは、Kubernetes 上にプラットフォームを構築することは、さまざまな要件を持つチームにサービスを提供するために、さまざまなツールを組み合わせる必要がある複雑なタスクだということです。Crossplane、ArgoCD、vclusterなど、多岐にわたるツールへの理解が求められます。
しかし同時に、プラットフォームはビジネス アプリケーションとしてのソフトウェア プロジェクトでもあります。主要なユーザーが誰になるかを理解することから始め、明確な API を定義することが、プラットフォームを構築する上で何を優先すべきかを決める鍵となります。技術的な側面だけでなく、開発者の体験を起点とした設計が肝要なのです。
ウォーキングスケルトンの例では、Crossplaneを用いて Environment という Custom Resource を定義し、それをKubernetesのAPIサーバーに適用するだけで、開発者はシンプルなYAMLを書くだけで必要な環境を要求できるようになります。このアプローチは、宣言的インフラストラクチャの理想を見事に体現していると言えるでしょう。コードとインフラの融合により、環境のプロビジョニングがアプリケーションデプロイメントと同じ土俵で扱えるようになるのです。
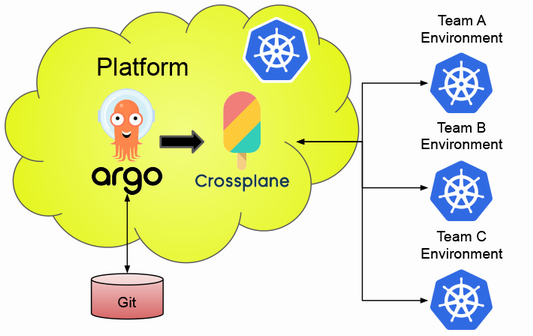
さらに、vclusterとCrossplaneを組み合わせることで、動的にテナント固有の仮想クラスターを生成する例も印象的でした。これにより、クラウド ネイティブへの移行を加速するために何を構築できるかを社内チームに示すことができます。開発者は、自分専用のKubernetes環境を手に入れつつ、プラットフォームの管理というオーバーヘッドからは開放されるという、まさにDXとインフラ効率化の両立を実現する理想的なアプローチです。

もちろん、実際のプラットフォームではより多くの要素を考慮する必要があります。とはいえ、Crossplane、ArgoCD、vclusterなどのツールを活用することで、プラットフォーム レベルでクラウド ネイティブのベスト プラクティスを促進できることは間違いありません。
ただし、ここで著者が強調しているのは、既存のツールを適切に組み合わせることの重要性です。カスタム ツールや、クラウド ネイティブ リソースの複雑な構成をプロビジョニングおよび維持する独自の方法を作成するのは避けるべきだと述べています。可能な限り、既存のツールやプラクティスを活用し、シンプルさを保つことが肝要なのです。

実際、本書のステップバイステップのチュートリアルに従うことで、Crossplane などのツールを使用して、vclusterオンデマンド開発環境をプロビジョニングする実践的な経験を得ることができます。また、本格的な Kubernetes API サーバーを操作したくない、または操作できないチームのために、簡素化された API も提供されています。これにより、開発チームの認知負荷を軽減しつつ、プラットフォームの恩恵を享受できるようになるのです。複数の Kubernetes クラスターの管理とテナントの分離への対処が、プラットフォーム チームの主要な課題であることを認識しつつ、適切なツールを選定し、シンプルさを保ちながら開発者の体験を向上させていくこと。それこそが、プラットフォームの成功を左右する鍵なのだと、ここからは読み取れます。

本章は、プラットフォームエンジニアリングの本質を、概念と実装の両面から照らし出してくれる、稀有な内容でした。単なるツールの解説にとどまらず、開発者の体験を起点とした設計思想や、チームとの協調の重要性など、プラットフォーム構築に不可欠な知見が余すところなく述べられています。
本章を通じて、私はプラットフォームの構築が、技術とプロセス、そして文化の融合であることを改めて認識しました。優れたツールの選定と適切な組み合わせは もちろん重要です。しかし、それ以上に大切なのは、開発者の声に耳を傾け、彼らの創造性を解き放つ仕組みを築くことなのだと。
Kubernetesとそのエコシステムは、プラットフォームを構築するための強力な基盤を提供してくれます。しかし、それをどう活用し、どのような形でチームに提供するかは、私たち自身の創意工夫次第です。技術の力を借りつつ、開発者の声に耳を傾ける。そのバランス感覚こそが、優れたプラットフォームを生み出す鍵なのだと、本章は教えてくれました。
本章は、プラットフォームエンジニアリングという新しい領域に踏み出すための、確かな一歩を印してくれる内容でした。著者の知見を自分なりに咀嚼し、日々の開発プロセスに活かしていく。その積み重ねの先に、真のDXを実現するプラットフォームが生まれるはずです。
7 Platform capabilities I: Shared application concerns
著者は冒頭で、クラウドネイティブアプリケーションの95%が行っている要件を学ぶことの重要性を強調しています。その要件とは、他のサービスとの通信、永続ストレージへのデータの保存と読み取り、非同期でのイベントやメッセージのやり取り、サービス接続用の認証情報へのアクセスなどです。私自身、日々の開発業務でこれらの課題に幾度となく直面してきました。著者の指摘は、まさに開発現場の実情を的確に捉えたものだと感じました。

これらの共通機能を実装する際の課題として、著者はアプリケーションとインフラストラクチャの間の摩擦を減らすことの重要性を指摘しています。サービス間通信やデータベース接続のために、アプリケーションコードにベンダー固有のライブラリやドライバを追加すると、インフラストラクチャの変更がアプリケーションの変更を強いることになります。この密結合が、開発チームとインフラチームの協調を複雑にし、ソフトウェアデリバリーのスピードを低下させる要因となっているのです。
著者が提案するのは、標準のAPIとコンポーネントで共有の関心事に対処することです。これらの共通機能を標準化されたAPIとして提供し、アプリケーションコードからインフラストラクチャの詳細を切り離すのです。プラットフォームチームがこれらのAPIを実装し、その背後でインフラストラクチャを適切に構成・管理することで、開発チームはビジネスロジックの実装に専念できるようになります。
アプリケーションインフラストラクチャに依存関係を移動すると、アプリケーションコードはプラットフォーム全体のアップグレードに影響されずに済みます。アプリケーションとインフラストラクチャのライフサイクルを分離することで、チームは日常的なユースケースでプロバイダー固有のクライアントやドライバーを扱う代わりに、安定したAPIに依存できるようになります。

この提案には大いに共感を覚えました。私もかねてより、アプリケーションとインフラの責務を明確に分離し、疎結合な設計を追求することの重要性を感じていました。標準化されたAPIを介してインフラストラクチャと対話することで、開発チームはベンダーロックインを回避しつつ、インフラの進化から独立してアプリケーションを開発できるようになります。
著者は、この考え方を具体化するためのツールとして、Dapr(Distributed Application Runtime)とOpenFeatureを紹介しています。
Daprは、分散アプリケーションの構築に必要な共通機能を、標準化されたAPI(Building Block API)として提供するオープンソースのプロジェクトです。Daprは、分散アプリケーションを構築する際の共通の関心事を解決します。HTTP/GRPCリクエストを書くことができる開発者は、プラットフォームチームが接続するインフラストラクチャとやりとりできます。 サービス間通信、状態管理、Pub/Sub、シークレットストアなど、クラウドネイティブアプリケーションに不可欠な機能がコンポーネント化され、統一的なインターフェースで利用できるようになっています。
私は以前からDaprに注目していましたが、改めてその設計思想の優れていることを実感しました。アプリケーションが標準的なHTTP/gRPCのAPIを通じてこれらの機能を利用できるため、プログラミング言語に依存せずに共通機能を実装できます。また、コンポーネントの実装を切り替えるだけで、異なるベンダーのサービスを利用できるのも大きな利点です。インフラの選定はプラットフォームチームに委ね、開発チームはアプリケーションの開発に専念できる。まさにDaprは、アプリケーションとインフラの責務を明確に分離するためのツールと言えるでしょう。
特に、サービス間通信とステートマネジメントのシナリオは、印象的でした。DaprのサービスインヴォーケーションAPIを使えば、サービス間の通信を抽象化し、さまざまな通信プロトコルを透過的に利用できます。またステートストアAPIにより、アプリケーションはデータベースの種類を意識せずに状態を保存・取得できるようになります。実際のアプリケーション開発において、これらのAPIがいかに複雑性を減らし、生産性を高めてくれるかが実感できる内容でした。
一方、OpenFeatureは機能フラグ(Feature Flag)の管理を標準化するためのプロジェクトです。機能フラグを使用すると、新機能を機能フラグの背後にマスクすることで、開発者はソフトウェアのリリースを継続できます。 機能フラグは、リリース済みの機能の有効・無効を動的に切り替える仕組みで、継続的デリバリーの文脈でよく用いられます。しかし、その実装は各社まちまちで、ベンダーロックインが起こりがちでした。OpenFeatureは、アプリケーションが機能フラグを使用して評価する方法を標準化します。OpenFeatureの抽象化に依存することで、プラットフォームチームは機能フラグの保存場所と管理方法を決定できます。 さまざまなプロバイダーが、非技術者向けのダッシュボードを提供し、フラグの表示や操作ができるようになります。

私は機能フラグの重要性を認識しつつも、その導入の複雑さゆえに二の足を踏んでいました。しかしOpenFeatureにより、ベンダーに依存せずに機能フラグを利用できるようになるのは画期的だと感じました。開発チームは機能の実装に集中し、リリースのタイミングはビジネスサイドが制御する。そんな理想的なデリバリープロセスが、OpenFeatureによって実現に近づくのではないでしょうか。
著者はまた、これらの標準化の取り組みを適用する際の留意点についても言及しています。外部APIへの依存は新たな課題を生むため、ローカル開発環境でのテストや、レイテンシーへの配慮が必要になります。また、エッジケースを個別に扱うことで、専門家はアプリケーションの要件に基づいてより意識的なケースを作成できます。これにより、経験の浅いチームメンバーが、データの保存や読み取り、アプリケーションコードからのイベントの発行のみを行う場合に、ベンダー固有のデータベース機能や低レベルのメッセージブローカー設定などのツールの詳細を理解する必要がなく、一般的なシナリオを処理できるようになります。 プラットフォームチームは、開発チームとの緊密なコミュニケーションを通じて、適切な抽象化のレベルを見極めていく必要があるのです。
章の後半では、これらの知見をConferenceアプリケーションに適用する方法が具体的に示されています。Redis や Kafka への依存を Dapr の API で置き換え、機能フラグを OpenFeature で管理する例は、非常に示唆に富むものでした。コード例を見ると、標準APIがいかにしてベンダー依存を排除し、開発者の体験を向上させているかが手に取るようにわかります。

これは私にとって、Dapr と OpenFeature の有用性を確信できる一節でした。ステップバイステップのチュートリアルに従った場合、SQL や NoSQL データベース、Kafka などのメッセージブローカーとやり取りする4つのサービスで構成されるクラウドネイティブアプリケーションのコンテキストで、Dapr や OpenFeature などのツールを使用した実践的な経験を得ることができました。また、実行中のアプリケーションのコンポーネントを再起動せずに、その動作を変更するために機能フラグを変更しました。 Kubernetesの普及により、インフラストラクチャのAPIは標準化されつつあります。一方で、アプリケーションレイヤーの共通機能は、いまだ各社独自の実装に委ねられているのが実情です。Dapr と OpenFeature は、このアプリケーションレイヤーに標準化をもたらす画期的なプロジェクトだと言えるでしょう。
本章を通じて、私はプラットフォームチームの役割の重要性を改めて認識しました。単にインフラを提供するだけでなく、アプリケーションの共通関心事をカプセル化し、開発者の生産性を高めることがプラットフォームの本質的な価値だと。Dapr や OpenFeature のようなツールを活用しつつ、開発チームに寄り添ったプラットフォームを構築すること。そこにこそ、プラットフォームエンジニアの腕の見せ所があるのだと感じました。
もちろん、標準化された API を導入するだけで全てが解決するわけではありません。エッジケースをどう扱うか、レガシーなシステムとの整合性をどう取るか。プラットフォーム構築の道のりは平坦ではありません。しかし、アプリケーションとインフラの責務を分離し、開発チームの生産性を高めるという指針は普遍的なものだと信じています。プラットフォームエンジニアリングの真髄は、技術の標準化とコミュニケーションの両輪にあるのだと、本章は教えてくれました。
本章は、クラウドネイティブ時代のアプリケーション開発の課題と、それを解決するための処方箋を示してくれる、示唆に富んだ内容でした。Dapr や OpenFeature のような取り組みは、まさにクラウドネイティブの「今」を体現するものだと言えるでしょう。同時に、それらを適切に活用し、開発チームに価値を届けるには、プラットフォームチームの深い理解と尽力が不可欠です。
プラットフォームエンジニアリングの真価が問われるのは、技術の選定よりもむしろ、技術をいかに活用するかにあるのかもしれません。標準化と抽象化を追求しつつ、現場の声に真摯に耳を傾ける。そのバランス感覚こそが、優れたプラットフォームを生み出す鍵なのだと、本章は示唆しています。
本章で紹介されたツールやプラクティスは、開発者としての私の日々の実践にも大いに役立つはずです。Dapr や OpenFeature を実際のプロジェクトで活用し、その効果を体感してみたいと思います。同時に、インフラストラクチャの標準化が進む中で、アプリケーションレイヤーの共通関心事にも目を向けることの大切さを、胸に刻んでおきたいと思います。
著者の知見を自分なりに咀嚼し、より良いアプリケーション開発とデリバリーのあり方を追求していく。エンジニアとしての私の使命は、まさにそこにあるのだと、改めて認識させられた次第です。クラウドネイティブの世界は、日進月歩で進化を続けています。Dapr や OpenFeature に象徴されるように、アプリケーションレイヤーの標準化も着実に進んでいます。私たちがすべきことは、その流れを見極めつつ、自分たちのコンテキストに適した形で活用していくことです。
8 Platform capabilities II: Enabling teams to experiment
Kubernetesを基盤としたプラットフォーム上で、チームが新しいバージョンのアプリケーションを安全かつ柔軟にリリースするための手法について、深く掘り下げた内容でした。
著者は冒頭で、カナリアリリース、ブルー/グリーンデプロイメント、A/Bテストなどの一般的なリリース戦略を実装することの重要性を説いています。これらの手法は、新しいバージョンのソフトウェアを段階的に展開し、問題を早期に発見しつつ、ユーザーへの影響を最小限に抑えるために不可欠です。しかし、著者が指摘するように、これらのリリース戦略をKubernetesの組み込みリソースだけで実装するのは非常に難しい作業です。Deploymentの複製や、Serviceの設定変更など、手作業での操作が多くなり、ミスも起こりやすくなります。
そこで著者が紹介するのが、Knative ServingとArgo Rolloutsという2つのプロジェクトです。これらのツールは、Kubernetesの上に高レベルの抽象化を提供することで、リリース戦略の実装を大幅に簡素化してくれます。
Knative Servingは、洗練されたネットワーク層を導入し、サービスの異なるバージョンへのトラフィックをきめ細かく制御できるようにします。Knative Serviceを使えば、カナリアリリースやブルー/グリーンデプロイメント、A/Bテストを、複数のKubernetesリソースを手動で作成することなく実現できます。

Knative Servingの大きな魅力は、トラフィックの移動を簡単に行えることと、Knativeのオートスケーラーが需要に応じてサービスをスケールアップ/ダウンしてくれることです。これにより、運用の負担が大幅に軽減されるのです。
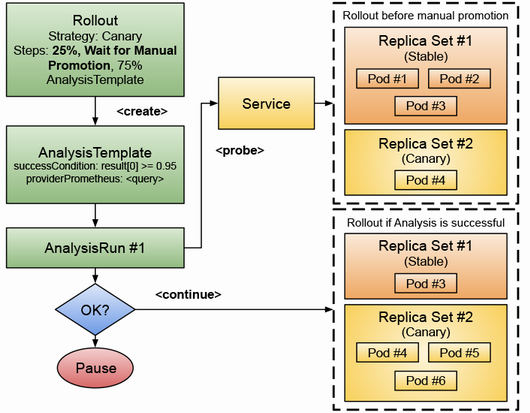
一方、Argo Rolloutsは、ArgoCDと連携し、Rolloutというリソースを使ってリリース戦略を実装する方法を提供します。Argo RolloutsはAnalysisTemplateとAnalysisRunという仕組みも備えており、新しいリリースの自動テストを行い、安全にバージョン間を移行できるようにしてくれます。

この2つのプロジェクトの存在は、Kubernetes上でのソフトウェア・デリバリーの課題の大きさを物語っていると感じました。アプリケーションのデプロイだけでなく、それを安全かつ柔軟に行うための機能が、プラットフォームに求められているのです。
特に印象的だったのは、Knative Servingのトラフィック制御機能の強力さです。重み付けベースのルーティングや、ヘッダーベースのルーティングなどを使えば、カナリアリリースの過程で新旧のバージョンへのアクセスを動的に制御できます。これは、リスクを最小限に抑えつつ、新機能の検証を進められる画期的な方法だと感じました。

また、Argo Rolloutsの分析テンプレートの仕組みにも目を見張りました。あらかじめ定義した指標に基づいて、新バージョンの動作を自動的に検証できるのは、リリースプロセスの安全性と効率を大いに高めてくれるはずです。
もちろん、これらのツールを使いこなすには、一定の学習と運用コストがつきまといます。Kubernetes自体の知識に加え、Knative ServingやArgo Rolloutsの概念を理解する必要があります。特に、Istioなどのサービスメッシュとの連携については、さらに高度な知識が求められるでしょう。
しかし、長期的に見れば、その投資は確実に報われるはずです。プラットフォームが提供する柔軟なリリース戦略は、ビジネスの俊敏性を高め、イノベーションを加速する力になります。より速く、より安全に価値を届けられるようになることは、競争力の源泉になるのですから。
本章を通じて、私はプラットフォームチームの役割の重要性を改めて認識しました。単にKubernetesのリソースを提供するだけでなく、アプリケーションのリリースプロセスをどう効率化するかを考え、適切なツールを選定・提供していくこと。それこそが、開発チームの生産性を真に高めるための鍵なのだと感じました。

そのためには、Knative ServingやArgo Rolloutsだけでなく、Istio、Dapr、OpenFeatureなど、クラウドネイティブのエコシステムを幅広く理解することが求められます。それぞれのツールの特性を把握し、自社のコンテキストに合った形で組み合わせていく。その作業は決して容易ではありませんが、避けて通れないものだと思います。
私自身、日々の業務の中で、これらのツールを実際に活用し、その効果を体感してみたいと思います。サービスのデプロイに留まらず、リリースプロセスの自動化と効率化にも目を向ける。そのマインドセットを持つことが、プラットフォームエンジニアとして成長するための第一歩になるはずです。
また、本章では、ビジネスサイドのチームとの協調の重要性も浮き彫りになりました。プロダクトマネージャーや非エンジニアのステークホルダーに、新バージョンの検証を柔軟に行える環境を提供すること。これにより、ビジネス主導のイノベーションを後押しできるのです。

本章を読み終えて、改めてプラットフォームの真価は、それがエンパワーメントの手段であることだと感じました。開発者の創造性を強化して、ビジネスの意思決定を迅速化する。その先にこそ、ソフトウェアがもたらす本当の価値があるのだと。
プラットフォームの構築は、単なる技術的課題ではありません。組織の文化を変え、人々の働き方そのものを変えていく営みです。その変革の旅路は、険しく長いものになるでしょう。でも、そこで得られる学びと成長は、きっとかけがえのないが大変なものになるはずです。
9 Measuring your platforms
プラットフォームのパフォーマンスを測定することの重要性と、その具体的な手法について深く掘り下げた内容でした。特に、DORAメトリクスの導入と、それを支えるデータパイプラインの設計には、多くの技術的な示唆が含まれていました。
DORAメトリクスは、ソフトウェアデリバリーのパフォーマンスを評価するための事実上の標準として、広く認知されつつあります。デプロイ頻度、リードタイム、変更失敗率、サービス復旧時間の4つの指標は、いずれもデリバリープロセスの重要な側面を捉えており、それらを組み合わせることで、チームの成熟度を多面的に評価できます。

しかし、これらのメトリクスの計算は、決して容易ではありません。データソースが多岐にわたるうえ、それぞれのツールが出力するデータのフォーマットは千差万別だからです。デプロイ頻度を計算するには、CIツールのログとデプロイ環境のイベントを紐づける必要がありますし、リードタイムの算出には、コミットログとデプロイログの時間差を計る必要があります。
この複雑性に対する著者の答えが、CloudEventsとCDEventsの活用です。CloudEventsは、クラウドネイティブなイベントを表現するための、ベンダー中立な仕様です。すでにServerless Workflow、Keptn、Knative、Kubernetesなど、多くのプロジェクトがCloudEventsをサポートしており、イベントデータの相互運用性が大きく向上しつつあります。
CDEventsは、CloudEventsの拡張仕様であり、継続的デリバリーの文脈で共通に発生するイベントを定義したものです。コード変更、ビルド、テスト、デプロイ、リリースなど、パイプラインのあらゆるフェーズがカバーされており、それぞれのイベントが持つべきデータの構造も規定されています。

つまり、CDEventsに準拠したイベントを集約することで、DORAメトリクスの計算に必要なデータの多くを、統一的なフォーマットで取得できるようになるのです。これは、データ統合のコストを大幅に削減し、メトリクスの信頼性を高めることにつながります。
とはいえ、既存のツールをCDEventsに対応させるのは、一朝一夕にはいかないでしょう。そこで著者が提案しているのが、CloudEventsとCDEventsを活用したデータパイプラインの設計です。各ツールが出力するイベントをCloudEventsとして取り込み、それをCDEventsに変換する。そのうえで、変換されたイベントをもとにメトリクスを計算する、というアプローチです。
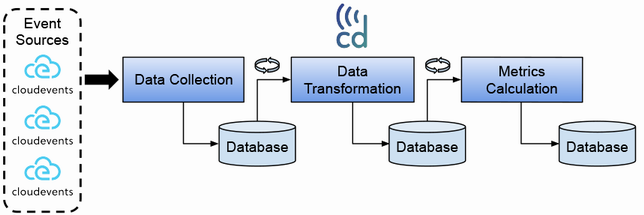
パイプラインの入り口では、Knative Sourcesのようなアダプタを使って、さまざまなツールのイベントをCloudEventsに変換します。例えば、Kubernetes上で動くアプリケーションの場合、KubernetesイベントをCloudEventsに変換するKnative SourceのApiServerSourceを使うことができます。

こうして取り込まれたCloudEventsは、いったんデータストアに保存されます。著者の例ではPostgreSQLが使われていますが、他のデータベースやストレージを使うこともできるでしょう。重要なのは、イベントデータを安全に保管し、後の処理で参照できるようにすることです。
次のステップは、保存されたCloudEventsをCDEventsに変換することです。著者は、この変換処理を関数(function)として実装することを提案しています。関数を使うメリットは、変換ロジックを小さな単位に分割でき、必要に応じて個別にスケーリングできる点にあります。また、新しい変換ロジックを追加する際も、既存の処理に影響を与えずに実装できます。

CDEventsへの変換が完了したら、いよいよDORAメトリクスの計算です。著者の提案では、これもまた関数として実装されます。各メトリックの計算ロジックは、CDEventsから必要なデータを抽出し、所定の計算を行うだけのシンプルなものになります。計算結果は、データストアに保存するか、あるいは直接可視化ツールに送ることができます。

以上が、著者が提案するデータパイプラインのアーキテクチャの概要です。特筆すべきは、その拡張性の高さでしょう。新しいデータソースへの対応は、CloudEventsへの変換機能を追加するだけで実現できますし、新しいメトリクスの計算も、専用の関数を実装するだけで可能になります。また、変換処理とメトリクス計算がステートレスな関数として実装されているため、必要に応じて水平にスケールすることもできます。
この設計は、現時点での技術選択に依存しない、汎用性の高いものだと感じました。実際のシステムを構築する際には、より堅牢なイベントストレージの選定や、耐障害性の確保など、様々な非機能要件も考慮する必要があるでしょう。しかし、その基本的なアプローチは、多くの組織で活用できるはずです。
加えて、本章ではKeptn Lifecycle Toolkit(KLT)というオープンソースプロジェクトも紹介されていました。KLTは、Kubernetes上のアプリケーションのデプロイメントを監視し、その前後に任意のタスクを実行できるようにするためのツールです。

KLTは、Kubernetesの標準機能であるSchedulerを拡張することで実現されています。アプリケーションのデプロイメント時に、KLTのControllerが介入し、デプロイメントの前後に登録されたタスクを実行するのです。
これらのタスクはTaskDefinitionという形で定義され、実際の処理はスクリプト(Deno、Python3など)またはコンテナイメージとして実装されます。例えば、デプロイ前にアプリケーションの設定を検証するタスクや、デプロイ後に自動テストを実行するタスクなどが考えられます。
KLTのアプローチは、先に述べたCloudEvents/CDEventsベースのデータパイプラインとは異なりますが、両者は相互に補完的な関係にあると言えるでしょう。KLTを使えば、デプロイメントのパフォーマンスデータをCloudEventsとして出力し、それをデータパイプラインで処理することもできます。逆に、データパイプラインで計算されたメトリクスを、KLTのタスクで参照することも可能です。
重要なのは、これらのツールを組み合わせることで、プラットフォームのパフォーマンス測定を自動化し、継続的な改善につなげられる点です。今や、デリバリーパフォーマンスの向上は、エンジニアリングチームだけの責任ではありません。組織全体でその重要性を認識し、データに基づいた意思決定を行っていく必要があります。
そのためには、DORAメトリクスのような共通の物差しを導入し、それを可視化・共有していくことが不可欠です。CloudEventsとCDEvents、そしてKLTは、そのための強力な武器になるはずです。もちろん、ツールの導入だけですべてが解決するわけではありません。測定の文化を組織に根付かせ、データに基づいた継続的改善のサイクルを回すこと。それこそが、プラットフォームチームに求められる真の課題なのだと、私は考えます。
本章を通じて、私はプラットフォームのパフォーマンス測定という課題の奥深さを改めて認識しました。適切な指標の選定、データの収集と統合、分析基盤の構築。それらはいずれも、高度な技術力と、現場への深い理解を必要とする難題です。
しかし、その困難に立ち向かうことこそが、プラットフォームエンジニアの本懐なのだと思います。本章が提示してくれたのは、その挑戦への道標でした。実装の細部はともかく、その基本的なアプローチは、多くの組織で活用できるはずです。
KLTのようなツールも、プラットフォームのパフォーマンス測定という文脈で捉え直すことで、新たな価値を見出せるでしょう。重要なのは、DORAメトリクスに代表される共通の物差しを導入し、それを組織全体で活用していくことです。
さいごに
本稿では、『Platform Engineering on Kubernetes』の概要と、各章の要点を技術者の視点でまとめました。本書が提示するのは、クラウドネイティブ時代のソフトウェア開発の理想像です。アプリケーションとインフラストラクチャの垣根を越えて、開発チームとプラットフォームチームが協調しながら、ビジネス価値を継続的に届けていく。その実現のためには、技術的な側面だけでなく、組織文化やプロセスの変革も不可欠だと述べられています。
私はプラットフォームエンジニアリングという概念自体は以前から知っていましたが、本書ではそれをKubernetesと関連づけて深く考察されていました。単にKubernetesというツールを導入するだけでなく、アプリケーションに必要な機能を適切に抽象化し、チームに提供していくことがプラットフォームの本質的な価値だと説明しながら技術的なことを一切疎かにしていない点がとんでもなく素晴らしいです。
また、DORAメトリクスに代表される、デリバリーパフォーマンスの測定の重要性も強調されていました。プラットフォームの価値を定量的に評価し、継続的に改善していくためには、適切な指標の導入と、データに基づいた意思決定が欠かせません。
ただし、本書で紹介されているアプローチをそのまま適用できる組織ばかりではないでしょう。大切なのは、自社のコンテキストを深く理解し、そこに適した形でクラウドネイティブの考え方を取り入れていくことだと思います。
プラットフォームエンジニアリングを実践していく上では、本書で述べられているようなツールやプラクティスに加えて、コミュニケーションが大切だと思いました。モブプログラミング・モブオペレーションなどの取り組みを通じて、チーム内での知識共有や価値観の浸透を図ることが、プラットフォームの継続的な改善と定着に大きく役立つはずです。
本稿では、技術者としての視点から本書の内容をまとめましたが、プラットフォームエンジニアリングの実践には、技術者以外のステークホルダーの理解と協力も不可欠です。マネージャーやビジネスサイドの方々にも本書を読んでいただき、その感想をぜひ共有していただきたいと思います。多様な視点からのフィードバックがあってこそ、真に組織に適したプラットフォームの構築が可能になるはずです。
また、本稿ではプラットフォームに関わる技術的な側面に焦点を当てましたが、実際のプラットフォーム構築には、組織的な要素も欠かせません。各チームのエンジニアの育成や、円滑なコミュニケーションの実現など、プラットフォームエンジニアリングには幅広いスキルが要求されます。こうした非技術的な側面については、また別の機会に掘り下げていきたいと思います。
プラットフォームは日々進化し続けるものです。特定のツールの使い方を習得するだけでなく、その背後にある考え方や原則を理解し、学び続けていく姿勢が求められます。『Platform Engineering on Kubernetes』は、そのための優れた指南書だと感じました。
クラウドネイティブ時代のソフトウェア開発は、まだ道半ばと言えるかもしれません。確立されたベストプラクティスは少なく、私たち一人ひとりが試行錯誤を重ねながら、前に進んでいくしかありません。本書が示してくれた知見と、SREの実践的なアプローチを組み合わせながら、クラウドネイティブ時代のプラットフォームのあるべき姿を、仲間たちと共に探求していきたいと思います。
みなさん、最後まで読んでくれて本当にありがとうございます。途中で挫折せずに付き合ってくれたことに感謝しています。
読者になってくれたら更に感謝です。Xまでフォロワーしてくれたら泣いているかもしれません。