はじめに
前回の続きで第二部のIII. Working With Servers And Other Application Runtime Platforms (サーバーおよびその他のアプリケーションランタイムプラットフォームとの作業)という部の読書感想文になります。
前回の記事 syu-m-5151.hatenablog.com
次回の記事 syu-m-5151.hatenablog.com
書籍のリンク
")
第三部 目次
III. Working With Servers And Other Application Runtime Platforms (サーバーおよびその他のアプリケーションランタイムプラットフォームとの作業)
10. Application Runtimes (アプリケーションランタイム)
- アプリケーションの実行環境に関する概要と管理方法を提供します。
11. Building Servers As Code (サーバーをコードとして構築する)
- コードを使用してサーバーを構築する方法について詳しく説明します。
12. Managing Changes To Servers (サーバーへの変更の管理)
- サーバーに加えられる変更を効果的に管理する戦略を提供します。
13. Server Images As Code (サーバーイメージをコードとして)
- サーバーイメージをコード化するアプローチとその利点について解説します。
14. Building Clusters As Code (クラスターをコードとして構築する)
- クラスターを効率的にコードで構築する手法について紹介します。
III. Working With Servers And Other Application Runtime Platforms (サーバーおよびその他のアプリケーションランタイムプラットフォームとの作業)
10. Application Runtimes(アプリケーションランタイム)
アプリケーションランタイムの章では、システムの3層モデルの一部として「インフラストラクチャシステムの部品」でアプリケーションランタイムを導入しています。ここでは、インフラ層からリソースを組み合わせて、アプリケーションをデプロイできるランタイムプラットフォームを提供する方法に焦点を当てています。アプリケーションランタイムは、インフラ管理ツールを使用して定義および作成されたインフラストラクチャスタックで構成されています。これは、どの言語や実行スタックで実行されるか、サーバー、コンテナ、またはFaaSサーバーレスコードにパッケージ化してデプロイされるかなど、それを使用するアプリケーションの理解から始まります。本章は、アプリケーションに対するランタイムプラットフォームとしてのインフラリソースの構成方法に焦点を当て、後の章でこれらのリソースをコードとして定義および管理する方法について詳しく説明しています。
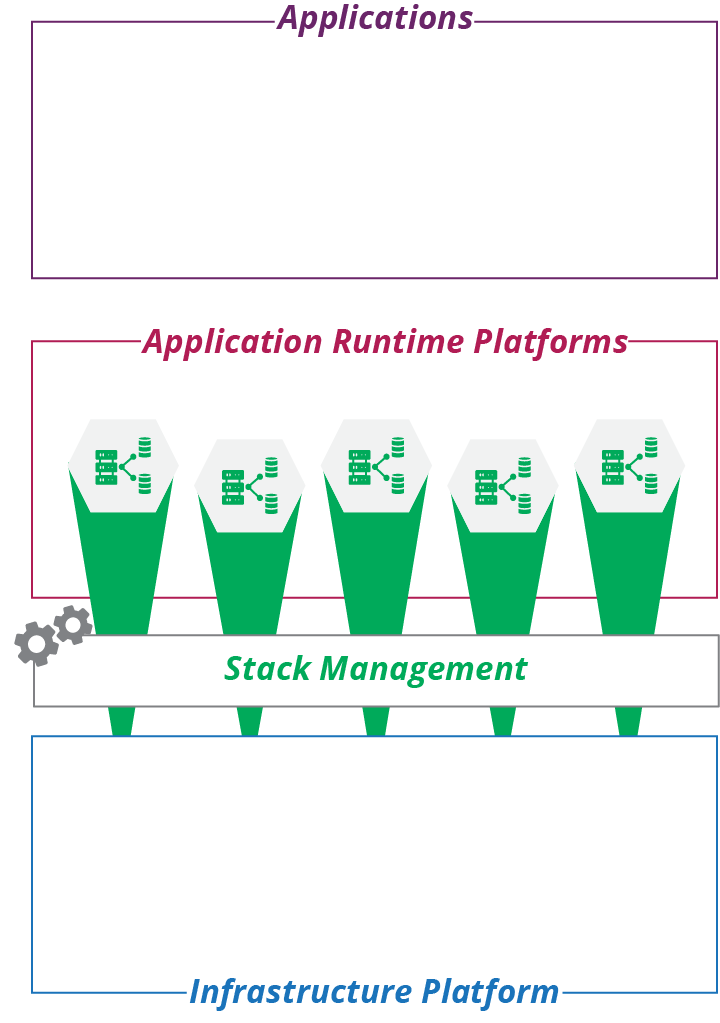 Figure 10-1. The application layer composed of infrastructure stacks より引用
Figure 10-1. The application layer composed of infrastructure stacks より引用
Cloud Native and Application-Driven Infrastructure
クラウドネイティブとアプリケーション主導のインフラに関するこのセクションは、現代インフラのダイナミックな性質を最大限に活用するソフトウェア設計に重点を置いています。Herokuの12ファクターメソドロジーやKubernetesエコシステムとの関連性は、現代のアプリケーション開発の重要性を強調しています。このアプローチは、特に大規模なシステムの再構築や運用において、私の経験と一致しています。クラウドネイティブは、可変性と拡張性を重視したアプローチであり、これが現代のソフトウェア開発の標準となっています。
Application Runtime Targets
アプリケーションランタイムターゲットを選定する際には、アプリケーションポートフォリオのランタイム要件を分析し、それに合わせたランタイムソリューションを設計することが重要です。これは、特に異なる技術スタックを持つ複数のプロジェクトを管理する場合に非常に役立ちます。ランタイムターゲットの選択は、アプリケーションのパフォーマンスと効率に大きく影響します。例えば、サーバーレス環境やコンテナベースの環境では、従来のサーバーベースのランタイムとは異なるアプローチが必要です。
Deployable Parts of an Application
アプリケーションのデプロイ可能な部分を理解することは、効率的なアプリケーションデプロイメント戦略を策定する上で重要です。実行可能ファイル、サーバー設定、データ構造などを適切に管理することは、私の経験上、運用の効率化に直結します。デプロイメントの自動化は、特に大規模なアプリケーションにおいて、時間とリソースの節約につながります。
Deployment Packages
デプロイメントパッケージのセクションは、異なるランタイム環境に適したパッケージ形式の理解を深めます。これは、適切なツールとプロセスを選択する上でのガイドとなります。デプロイメントパッケージは、アプリケーションの構成とデプロイメントを標準化し、異なる環境間での一貫性を保証します。
Deploying Applications to Servers
サーバーへのアプリケーションデプロイメントに関しては、物理的または仮想的なサーバーを利用する従来のアプローチに焦点を当てています。これは、インフラの柔軟性とアプリケーションのニーズのバランスをとる上で重要な考慮点です。サーバーベースのデプロイメントは、特にレガシーシステムや特定のセキュリティ要件を持つアプリケーションにおいて、依然として重要な役割を果たします。
Packaging Applications in Containers
コンテナでのアプリケーションパッケージングについては、依存関係をアプリケーションパッケージに取り込むことの利点と課題を詳述しています。コンテナ化の進展は、アプリケーションのデプロイメントと運用の柔軟性を大きく向上させています。コンテナは、異なる環境間でのアプリケーションの実行を標準化し、デプロイメントプロセスを単純化します。
Deploying Applications to Server Clusters
サーバークラスターへのアプリケーションデプロイメントは、スケーラビリティと冗長性を確保するための重要な手法です。私の経験でも、効果的なクラスターマネジメントはシステムの可用性を大幅に向上させることができます。サーバークラスターは、負荷分散や障害耐性の向上に寄与します。
Deploying Applications to Application Clusters
アプリケーションクラスターへのデプロイメントは、ホストサーバー間でのアプリケーションインスタンスの分散に注目しています。これは、特に大規模なアプリケーションにおいて、リソースの効率的な利用とスケーラビリティの向上を実現します。クラスター内の異なるサーバーで異なるアプリケーションを実行することにより、リソースの最適化と柔軟な運用が可能になります。
Packages for Deploying Applications to Clusters
クラスターへのアプリケーションデプロイメントに必要なパッケージに関するセクションでは、複雑なインフラストラクチャ上で複数のプロセスとコンポーネントをデプロイする方法について説明しています。このアプローチは、現代の大規模アプリケーションの運用に不可欠です。クラスターベースのデプロイメントは、アプリケーションのスケールアップとスケールダウンを効率的に管理するための鍵となります。
Deploying FaaS Serverless Applications
FaaS(Function as a Service)サーバーレスアプリケーションのデプロイメントは、サーバーやコンテナの詳細を抽象化し、インフラの複雑さから開発者を解放します。これは、迅速な開発とデプロイメントを可能にし、特にイベント駆動型アプリケーションやマイクロサービスアーキテクチャに適しています。サーバーレスは、リソースの使用に基づいた課金モデルを提供し、コスト効率を向上させます。
Application Data
アプリケーションデータに関して、特にデータ構造の変更やデータの継続性の確保の重要性に焦点を当てています。これは、データベースの設計と運用における私の経験と一致し、データの変更と管理がシステムの信頼性と拡張性に大きく寄与することを示しています。
Data Schemas and Structures
データスキーマと構造のセクションでは、構造化されたデータストレージと非構造化、またはスキーマレスなデータストレージの違いを説明しています。スキーマ移行ツールの使用は、私の経験では、データベースのバージョン管理と変更の追跡に非常に有効であることが分かりました。
Cloud Native Application Storage Infrastructure
クラウドネイティブアプリケーションストレージインフラストラクチャは、動的に割り当てられるストレージリソースに重点を置いています。これは、拡張性とリソースの最適化におけるクラウドネイティブのアプローチの利点を反映しています。
Application Connectivity
アプリケーションの接続性に関するセクションでは、インバウンドとアウトバウンドの接続要件と、これらをインフラストラクチャスタックの一部として定義する方法について説明しています。これは、ネットワーク設計とセキュリティを考慮したアプリケーション開発に不可欠な要素です。
Service Discovery
サービスディスカバリーに関しては、動的なインフラストラクチャでのサービスの発見方法として、DNS、リソースタグ、構成レジストリなどを含む様々なメカニズムに焦点を当てています。これは、マイクロサービスアーキテクチャや大規模な分散システムにおいて、サービス間の連携と通信のための重要な概念です。
最後に、この章の結論では、インフラストラクチャの目的は有用なアプリケーションとサービスを実行することであると強調しています。アプリケーション主導のインフラストラクチャアプローチは、アプリケーションのランタイム要件に焦点を当て、アプリケーションの実行に必要なスタック、サーバー、クラスターなどの中間層構造を設計するのに役立ちます。「アプリケーション主導のインフラストラクチャ戦略では、現代的な動的インフラを使用してアプリケーションランタイム環境を構築します。(原文: An application-driven infrastructure strategy involves building application runtime environments for applications using modern, dynamic infrastructure.)」は、現代のインフラストラクチャ設計の核心をついており、私自身の経験でも、動的で柔軟なインフラストラクチャの設計と実装が、効率的で拡張性のあるシステムの構築に不可欠であることを強く感じています。アプリケーションのニーズに応じてインフラを適応させることが、現代のソフトウェア開発と運用の鍵となっています。
11. Building Servers As Code (サーバーをコードとして構築する)
「サーバーをコードとして構築する」章では、サーバーの設定を自動化する方法としてインフラストラクチャとしてのコードが最初に登場したことについて説明しています。システム管理者は、シェル、バッチ、Perlスクリプトを書いてサーバーを設定し、CFEngineはサーバー上のパッケージのインストールと設定ファイルの管理に対して、宣言型で冪等なDSLの使用を先駆けました。そして、PuppetやChefがこれに続きました。これらのツールは、物理サーバーやVMwareを使用した仮想マシン、後にはクラウドインスタンスなど、既存のサーバーから始めることを前提としています。現在では、サーバーがインフラスタックの一部であるか、コンテナクラスターの下層の詳細であるかに焦点を当てています。しかし、サーバーはほとんどのアプリケーションランタイム環境において依然として不可欠な部分です。この章では、サーバーの構成内容(設定する必要があるもの)とサーバーのライフサイクル(設定活動が行われるタイミング)から始まり、サーバー設定コードとツールに関する視点に移ります。この章の中心的な内容は、サーバーインスタンスの作成方法、サーバーを事前に構築して複数の一貫性のあるインスタンスを作成する方法、およびサーバーライフサイクル全体にわたるサーバー設定の適用方法に関する異なる方法を見ています。サーバーのライフサイクルをいくつかの遷移フェーズに分けて考えることが役立つ場合があります。サーバーの基本的なライフサイクルには、サーバーインスタンスの作成と設定、既存のサーバーインスタンスの変更、サーバーインスタンスの破棄という3つの遷移フェーズがあります。
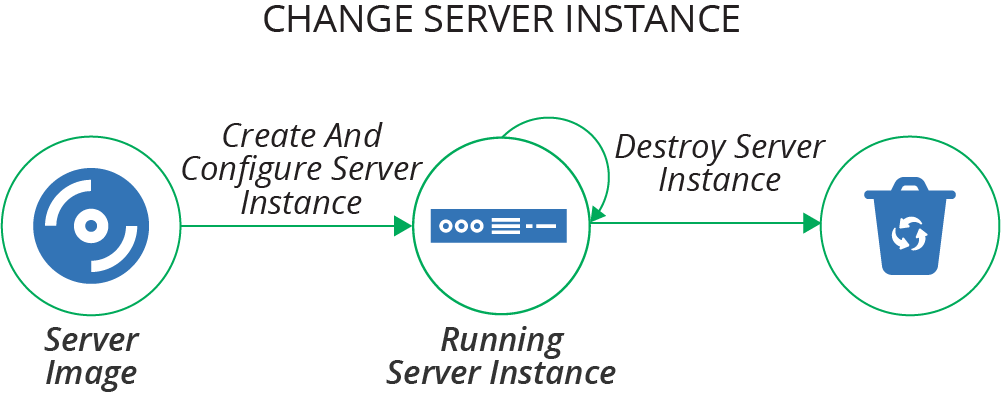 Figure 11-1. The basic server life cycle より引用
Figure 11-1. The basic server life cycle より引用
What’s on a Server
サーバーに存在するものを理解することは、システムの安定性と効率を高める上で重要です。サーバー上のソフトウェア、設定、データの区別は、特に自動化されたインフラ管理において、適切なツールの選択と利用に不可欠です。私の経験からも、これらの要素を適切に管理することがシステムの安定稼働に直接影響を与えます。
Where Things Come From
サーバーの要素がどこから来るかを理解することは、サーバー構築と運用の複雑さを浮き彫りにします。OSのインストール、OSパッケージリポジトリ、言語やフレームワークのパッケージなど、多様な要素の組み合わせがサーバーのセットアップにおいて重要です。私の経験では、これらの要素を適切に組み合わせることが、効率的で堅牢なサーバーインフラの構築に不可欠であることが明らかです。
Server Configuration Code
サーバー設定コードのセクションは、自動化されたサーバー設定のためのツールとアプローチを詳述しています。Ansible、Chef、Puppetなどのツールは、サーバー設定の自動化において非常に重要な役割を果たし、私の経験からもこれらのツールの有効性を実感しています。
Server Configuration Code Modules
サーバー設定コードモジュールについてのこの部分は、コードの組織化とモジュール化の重要性を強調しています。実際のプロジェクトでは、これらの原則がサーバー設定の複雑さを管理するために不可欠です。コードのモジュール化は、メンテナンスの容易さと拡張性を提供します。
Designing Server Configuration Code Modules
サーバー設定コードモジュールの設計についてのセクションは、単一の関心事に焦点を当てたモジュールの重要性を説明しています。これは、効率的なインフラストラクチャ管理に必要なベストプラクティスです。私の経験でも、関心の分離を行うことで、より管理しやすく、エラーの少ないインフラを構築できることが実証されています。
Versioning and Promoting Server Code
サーバーコードのバージョニングと昇格に関するこの部分は、サーバー設定の変更を管理するための戦略を提供します。コードのバージョン管理は、安定したインフラストラクチャ環境の維持において重要です。バージョン管理を通じて、安定性と再現性を保証することができます。
Server Roles
サーバーの役割に関するセクションは、特定の設定モジュール群をサーバーに適用する方法を示しています。これは、サーバー設定の柔軟性と適用性を高めるための有効な手法です。役割に基づくモジュール管理は、特に大規模な環境において、サーバーの設定と運用を簡素化します。
Testing Server Code
サーバーコードのテストに関するこの部分は、インフラストラクチャコードのテスト戦略を提供し、品質保証において重要な役割を果たします。私の経験では、テストはインフラストラクチャの信頼性と整合性を保証するための鍵です。
Progressively Testing Server Code
サーバーコードの段階的なテストについてのセクションは、テスト戦略を効果的に組み立てる方法を示しています。これは、インフラストラクチャの信頼性を高めるために不可欠です。段階的なテストは、コードの整合性を保ちながら、継続的に品質を向上させることができます。
What to Test with Server Code
サーバーコードで何をテストするかについてのこのセクションは、テストの焦点と目的を明確にします。これは、サーバー設定の精度と効率を保証するために重要です。テストを通じて、異なる環境や条件下でのサーバーの挙動を確認し、予期せぬ問題の早期発見と修正を行うことができます。
How to Test Server Code
サーバーコードをどのようにテストするかに関するセクションは、効果的なテスト方法とツールを提供します。InspecやServerspecなどのツールは、サーバーの状態を検証し、期待される動作を保証するために役立ちます。実際のテストプロセスは、特定の条件下でサーバーの設定と動作を確認し、必要に応じて調整を行うことを目的としています。
Creating a New Server Instance
新しいサーバーインスタンスを作成する際には、物理サーバーや仮想マシンの選択、OSのインストール、初期設定の適用が含まれます。これは、効率的で再現性の高いサーバー環境を構築するために重要です。私の経験では、新しいサーバーインスタンスの作成は、システムの拡張性と柔軟性に大きく寄与します。
Hand-Building a New Server Instance
手作業で新しいサーバーインスタンスを構築する方法は、特に小規模な環境や実験的な目的に適しています。しかし、大規模な運用環境においては、この方法は非効率的でエラーが発生しやすいため、自動化されたプロセスに置き換えることが望ましいです。
Using a Script to Create a Server
サーバー作成のためのスクリプト使用に関して、このセクションはサーバー作成プロセスの自動化の重要性を強調しています。コマンドラインツールやAPIを利用するスクリプトを作成することで、サーバーの設定が一貫性を持ち、透明性が向上します。私の経験では、このようなスクリプトを活用することで、サーバーのデプロイメントプロセスの効率化とエラーの削減が可能です。
Using a Stack Management Tool to Create a Server
スタック管理ツールを使用したサーバー作成に関するこの部分では、サーバーを他のインフラリソースと一緒に定義する利点を説明しています。Terraformなどのツールを使用することで、サーバーインスタンスの作成や更新が簡素化されます。私の経験上、スタックツールの使用は、インフラリソースの統合と管理を効率的に行うのに役立ちます。
Configuring the Platform to Automatically Create Servers
プラットフォームを設定して自動的にサーバーを作成するこのセクションは、オートスケーリングやオートリカバリーのような機能を利用する方法を示しています。これは、負荷の増加に応じたサーバーの追加や障害発生時のサーバーインスタンスの交換といった、動的な環境において特に重要です。
Using a Networked Provisioning Tool to Build a Server
ネットワークプロビジョニングツールを使用してサーバーを構築するこの部分では、ハードウェアサーバーの動的なプロビジョニングプロセスについて説明しています。PXEブートなどの手法を利用して物理サーバーをリモートで起動し、OSインストールや設定を行うプロセスは、特に物理的なインフラを管理する際に有効です。
Prebuilding Servers
事前にサーバーを構築するこのセクションでは、サーバーの内容を事前に準備する複数の方法を提供しています。これにより、サーバーの構築プロセスを高速化し、複数の一貫性のあるサーバーインスタンスを容易に作成できます。実際に、事前に構築されたサーバーイメージを使用することで、デプロイメントの時間と労力を大幅に削減できることを経験しています。
Hot-Cloning a Server
実行中のサーバーをホットクローニングするこの部分では、クローニングを行う際の利便性とリスクについて説明しています。特に、本番環境のサーバーをクローニングする際には、意図しない影響を避けるために注意が必要です。
Using a Server Snapshot
サーバースナップショットの使用に関するこのセクションでは、ライブサーバーからスナップショットを取得し、そのスナップショットを使用して新しいサーバーを作成する方法を提供しています。これは、特に大規模な環境において、サーバーの一貫性を保つための有効な方法です。
Creating a Clean Server Image
クリーンなサーバーイメージを作成するこの部分では、複数の一貫性のあるサーバーインスタンスを作成するための基盤となるイメージを作成するプロセスを説明しています。これは、サーバーのデプロイメントを標準化し、品質を保つために非常に重要です。
Configuring a New Server Instance
新しいサーバーインスタンスの設定に関するこのセクションでは、サーバーの作成とプロビジョニングプロセスの最後の部分である自動化されたサーバー設定コードの適用について説明しています。このプロセスは、新しいサーバーを作成する際の構成を決定する上で重要な要素です。
最後に、この章はサーバーの作成とプロビジョニングに関する様々な側面をカバーしています。サーバーに含まれる要素にはソフトウェア、設定、データがあり、これらは通常、サーバーイメージとサーバー設定ツールを使用して追加されるパッケージと設定から構成されます。サーバーを作成するためには、コマンドラインツールを使用するかUIを使用することができますが、コード駆動のプロセスを使用することが好ましいです。今日では、カスタムスクリプトを作成することは少なく、スタック管理ツールを使用することが一般的です。サーバーを構築するためのさまざまなアプローチについて説明していますが、通常、サーバーイメージを構築することをお勧めします。
12. Managing Changes To Servers (サーバーへの変更の管理)
この章は、サーバーとそのインフラに対する変更を管理するための多様なアプローチとパターンを探求しています。この章を読んで、サーバーの変更管理における自動化の重要性が強く印象に残りました。特に、変更を例外的なイベントではなく、日常的なルーチンとして取り扱うことの重要性が強調されている点に共感しました。私自身の経験からも、一貫性のある自動化された変更プロセスは、システムの安定性と信頼性を大きく向上させると確信しています。また、この章で提案されている様々なパターン、特に「継続的な設定同期」と「不変のサーバー」というパターンは、サーバー運用の効率を高める上で非常に有効です。サーバーの設定を定期的に同期することで、予期せぬ変更や誤差を早期に検出し、対処することが可能になります。また、不変のサーバーの概念は、変更によるリスクを減らす効果的な手法として、私のプロジェクトでも積極的に採用しています。サーバー設定コードをどのように適用するかに関しても、プッシュとプルの2つのパターンを詳しく説明しています。これらのパターンの選択は、サーバーのライフサイクルイベントに合わせて行う必要があり、特定の状況や要件に基づいて適切なアプローチを選択することが重要です。サーバーの他のライフサイクルイベント、例えばサーバーインスタンスの停止、再起動、置換、失敗したサーバーの回復などについても、有益な洞察を提供しています。特に、サーバーの回復プロセスは、クラウドインフラストラクチャの信頼性の限界に対処するために不可欠です。総じて、サーバーのライフサイクル管理における現代的なアプローチを包括的に提示しており、サーバーの設定と変更プロセスを最適化するための貴重なリソースとなっています。
Change Management Patterns: When to Apply Changes
サーバーの変更管理パターンは、変更を適用するタイミングを決定するための重要なガイドラインを提供します。変更が必要となった場合にそれを例外的なイベントとして扱うのではなく、ルーチンとして組み込むことで、システムの一貫性とポリシーへの準拠を確保できます。これは、私が経験したシステムの自動化における重要な一歩です。
Antipattern: Apply On Change
このアンチパターンは、特定の変更を適用するためにのみ設定コードを使用することを示しています。変更を例外として扱うことは、システムの不整合とエラーの原因となることが多いです。これは、私の経験でも、効率的なシステム管理において避けるべき方法です。
Pattern: Continuous Configuration Synchronization
継続的な設定同期は、変更があるかどうかに関わらず、定期的に設定コードを適用することを意味します。これにより、サーバーの設定の一貫性が保たれ、予期せぬ違いを早期に検出できます。これは、私のSREとしての実践において、サーバー運用の効率を大幅に向上させた方法です。
Pattern: Immutable Server
不変のサーバーとは、設定が変更されないサーバーインスタンスを意味します。変更を配信するために、変更された設定で新しいサーバーインスタンスを作成し、既存のサーバーを置き換えます。これは、特に安定性と整合性が重要な環境で有効な手法です。
How to Apply Server Configuration Code
サーバー設定コードの適用方法に関するこのセクションは、サーバーに変更を適用するためのパターンを検討します。サーバーの新規構築、既存インスタンスの更新、サーバーイメージの構築において、これらのパターンは不可欠です。
Pattern: Push Server Configuration
プッシュサーバー設定パターンでは、新しいサーバーインスタンスの外部からサーバーに接続してコードを実行し、適用します。これは、サーバーインスタンスへのタイムリーな設定更新が必要な場合に特に有効です。
Pattern: Pull Server Configuration
プルサーバー設定パターンでは、サーバーインスタンス自体で実行されるプロセスが設定コードをダウンロードして適用します。これは、サーバーインスタンスが入ってくる接続を受け入れる必要がないため、攻撃面を減らすのに役立ちます。
Other Server Life Cycle Events
サーバーの他のライフサイクルイベントに関するこのセクションでは、サーバーインスタンスの停止、再起動、置換、失敗したサーバーの回復などを検討します。これらは、サーバーの管理と運用において、特に重要なフェーズです。
Stopping and Restarting a Server Instance
サーバーインスタンスの停止と再起動に関するこのセクションは、特定の目的のためにサーバーを一時的に停止または再起動する方法を示しています。これは、コスト削減やメンテナンスのために、しばしば実践されます。
 Figure 12-1. Server life cycle—stopping and restarting より引用
Figure 12-1. Server life cycle—stopping and restarting より引用
Replacing a Server Instance
サーバーインスタンスの置換に関するこの部分は、新しいサーバーインスタンスを作成し、古いインスタンスと交換するプロセスを説明しています。これは、特に自動スケーリングや自動回復を利用する環境で役立つアプローチです。
Recovering a Failed Server
失敗したサーバーの回復についてのこのセクションでは、サーバーインスタンスが失敗した場合の回復プロセスについて説明しています。これは、クラウドインフラストラクチャの信頼性が常に保証されるわけではないため、特に重要です。
この章は、サーバーのライフサイクルにおける核心的なイベントを網羅しています。サーバーの作成と変更に関するアプローチの多くは、サーバーイメージをカスタマイズし、それを使用して複数のサーバーインスタンスを作成または更新することに依存しています。
13. Server Images As Code (サーバーイメージをコードとして扱う)
サーバーイメージの自動化された構築と維持に関する包括的なガイドを提供しています。この章を読む中で、サーバーイメージの構築と管理を自動化することの重要性が強調されてました。特に、サーバーイメージのライフサイクルを通じて、一貫性と品質の確保に焦点を当てることが重要であると感じました。サーバーイメージの構築プロセスは、オンラインとオフラインの二つのアプローチが存在し、各々の利点と制約について詳しく解説されています。私の経験上、オフラインのイメージ構築は迅速で、特定のシナリオでは非常に有効ですが、より複雑な設定を必要とすることがあります。また、サーバーイメージの異なる起源、例えばベンダー提供のストックイメージやゼロからの構築、そしてそのコンテンツの出所に関する議論は、セキュリティとパフォーマンスのバランスを取る上で非常に有益です。セキュリティに関する考慮事項は、特に重要であり、サーバーイメージの構築プロセスにおいて常に優先されるべきです。サーバーイメージのバージョニングと更新の管理は、章の中でも特に興味深い部分でした。これにより、サーバーイメージが最新のセキュリティパッチや設定で常に最新の状態を保つための効率的な方法が提供されます。私の経験では、サーバーイメージの定期的な更新は、インフラの安定性と運用の効率を大幅に向上させることができます。さらに、サーバーイメージをパイプラインを通じてテストおよび配信することに関するセクションは、インフラストラクチャの自動化とCI/CDの実践において非常に重要な概念を提供します。パイプラインを使用することで、サーバーイメージの構築、テスト、配布が容易かつ効率的になります。この章全体を通して、サーバーイメージを効率的に管理し、継続的に改善するための強固な基盤が提示されています。これは、現代のインフラストラクチャ管理において不可欠なリソースであり、その実践は技術的な洞察とともに、ビジネスの効率性とセキュリティを高める重要な手段となります。
 Figure 13-1. Server image life cycle より引用
Figure 13-1. Server image life cycle より引用
Building a Server Image
サーバーイメージの構築に関するセクションでは、カスタムサーバーイメージの作成プロセスの重要性とその利点について深く掘り下げられています。このプロセスを通じて、組織固有の要件やセキュリティ基準に合致したイメージを作成することの価値が明らかにされました。このセクションは、自動化されたイメージ作成のアプローチが、サーバーのデプロイメントをより迅速かつ安全にする方法を示しています。実際に、カスタマイズされたイメージを使用することで、セキュリティやパフォーマンスの最適化が可能になると私は経験しています。
Why Build a Server Image?
サーバーイメージを構築する理由についてのセクションは、特に啓発的でした。組織のガバナンス、セキュリティの強化、パフォーマンスの最適化など、カスタムイメージを構築するための具体的な理由が挙げられています。これらの要因は、私が直面する日常の課題と密接に関連しており、カスタムサーバーイメージを活用することの価値を再確認させてくれました。
How to Build a Server Image
サーバーイメージの構築方法に関する部分は、理論的かつ実践的なアプローチを提供しており、非常に役立ちました。オンラインとオフラインの両方のイメージ構築方法が詳細に説明されており、これは技術的な選択肢を検討する際に重要なガイドラインとなります。
Tools for Building Server Images
このセクションでは、サーバーイメージを構築するためのツールとサービスが詳述されています。Packerのようなツールの利用が、イメージ構築プロセスを効率化する上でいかに重要かが強調されているのを見て、私の現在のワークフローに対する洞察を得ることができました。
Online Image Building Process
オンラインでのイメージ構築プロセスについてのセクションは、イメージを作成する実際の手順を明確に説明しています。このプロセスに関する詳細な説明は、実務での応用を容易にし、サーバーイメージの構築方法の理解を深めました。
Offline Image Building Process
オフラインイメージ構築プロセスに関する説明は、オンラインプロセスとの比較を通じて、異なるアプローチの利点と制約を理解するのに役立ちました。オフラインでのイメージ構築方法は、特定の状況下での効率性を考慮する上で重要です。
Origin Content for a Server Image
サーバーイメージの起源コンテンツに関するセクションは、イメージ構築の基礎となる要素についての理解を深めるのに役立ちました。ストックイメージからの構築、スクラッチからの構築、そしてサーバーイメージとそのコンテンツの由来に関する議論は、イメージ構築プロセスの基礎を形成します。
Building from a Stock Server Image
ストックサーバーイメージからの構築に関するセクションは、既存のイメージをカスタマイズする方法とその利点を解説しています。このアプローチは、特にセキュリティやパフォーマンスの最適化を目指す際に重要です。
Building a Server Image from Scratch
ゼロからサーバーイメージを構築するプロセスに関する詳細は、完全にカスタマイズされたイメージを作成するための重要なガイドラインを提供しています。これは、特定の高度な要件を持つ組織にとって特に有益です。
Provenance of a Server Image and its Content
サーバーイメージとそのコンテンツの出所に関するセクションは、セキュリティと信頼性の側面を考慮する上で特に重要です。サードパーティからのコンテンツを使用する際の潜在的なリスクを理解し、適切なチェックを実施することが強調されています。
Changing a Server Image
サーバーイメージの変更に関するセクションは、イメージの維持と更新のプロセスに光を当てています。定期的なリフレッシュとバージョニングの重要性に関する洞察は、効率的で安全なインフラストラクチャ管理のために不可欠です。
Reheating or Baking a Fresh Image
イメージの再加熱または新たなイメージの焼き直しに関するセクションは、サーバーイメージの更新方法に関する具体的な選択肢を提示しています。どちらのアプローチもそれぞれのメリットがあり、状況に応じて適切な方法を選択することが重要です。
Versioning a Server Image
サーバーイメージのバージョニングに関する議論は、イメージの追跡と管理の重要性を強調しています。バージョニングは、イメージの透明性と一貫性を保つ上で不可欠な要素です。
Updating Server Instances When an Image Changes
イメージが変更された場合のサーバーインスタンスの更新についてのセクションは、イメージを基に作成されたインスタンスの一貫
Updating Server Instances When an Image Changes
「イメージが変更されたときのサーバーインスタンスの更新」に関するセクションは、サーバーイメージの更新とサーバーインスタンスの同期に関する洞察を提供しました。この部分では、新しいサーバーイメージを作成した後のサーバーインスタンスの管理方法について考察しています。サーバーインスタンスを即座に更新するか、自然に時間が経過するまで待つかという選択は、システムの整合性と運用の効率の両方に影響を及ぼします。私の経験では、定期的なサーバーインスタンスの更新は、セキュリティとパフォーマンスの観点から重要です。また、適切なバージョン管理と更新ポリシーは、サーバー環境の一貫性を保ち、予期せぬ問題を回避するために不可欠です。
Providing and Using a Server Image Across Teams
「チーム間でのサーバーイメージの提供と使用」は、サーバーイメージを異なるチーム間で共有する際のベストプラクティスに焦点を当てています。このセクションは、サーバーイメージを中央チームが作成し、他のチームが使用する場合のダイナミクスを明確に説明しています。イメージのバージョン管理と共有に関する洞察は、大規模な組織における効果的なインフラ管理に特に関連しています。私が以前関わったプロジェクトでは、チーム間でサーバーイメージを共有することで、作業の重複を防ぎ、一貫性を保つことができました。
Handling Major Changes to an Image
「イメージの大きな変更を扱う」セクションは、サーバーイメージに対する大規模な変更を適切に管理する方法に関する重要な洞察を提供しています。このセクションでは、大きな変更をセマンティックバージョニングを使用して管理することの重要性が強調されています。私の経験では、サーバーイメージに大きな変更を加える際には、特に慎重なテストと段階的な導入が重要です。これにより、変更による影響を最小限に抑え、システムの安定性を保つことができます。
Using a Pipeline to Test and Deliver a Server Image
「サーバーイメージをテストおよび配信するためのパイプラインの使用」セクションは、サーバーイメージのライフサイクルを自動化し、品質を確保するための強力なアプローチを提供しています。パイプラインを通じてサーバーイメージを構築、テスト、配信することは、継続的な改善と効率化のための鍵です。私の経験では、CI/CDパイプラインを使用することで、サーバーイメージの作成と更新が格段に効率的になり、システムの全体的な信頼性が向上します。
Using Multiple Server Images
「複数のサーバーイメージの使用」セクションは、異なる環境や用途に合わせて複数のサーバーイメージを維持する必要性を説明しています。異なるプラットフォーム、オペレーティングシステム、ハードウェアアーキテクチャに対応するためのサーバーイメージの管理は、特に複雑なインフラストラクチャを持つ組織において重要です。私の経験では、特定の役割や要件に合わせてサーバーイメージを最適化することで、運用の効率を大幅に向上させることが可能です。
サーバーイメージの管理に関するこの章の総括として、サーバーイメージをコードとして扱うことの利点が明確に示されています。自動化されたプロセスを通じてサーバーイメージを維持し、定期的に更新することで、インフラストラクチャの効率性とセキュリティが大きく向上することが示されています。
14. Building Clusters As Code (クラスターをコードとして構築する)
この章は、クラスターをコードとして構築する方法について詳しく解説しています。ソフトウェアエンジニアリングの経験から、このアプローチの強みは、システムの柔軟性と再現性にあります。KubernetesやAWS ECSなどの例が挙げられ、クラスター管理の複雑さを隠蔽しながらも、コードを介して制御可能であることが強調されています。
 Figure 14-1. An application cluster creates a layer between infrastructure resources and the applications running on them より引用
Figure 14-1. An application cluster creates a layer between infrastructure resources and the applications running on them より引用
Application Cluster Solutions
アプリケーションクラスターのソリューションに関しては、クラウドベースのサービスとオンプレミスのソリューション間の選択肢を詳細に検討しています。私の経験では、クラウドサービスは迅速な展開と低い初期コストを提供しますが、長期的にはカスタマイズの柔軟性とコントロールの観点で限界があります。一方で、オンプレミスソリューションは初期設定が複雑であり、維持管理のコストが高くなる可能性がありますが、長期的にはより制御可能で安定しています。
Cluster as a Service
クラウドプラットフォームが提供するCluster as a Service は、設定や管理の簡素化を可能にします。しかし、クラウド固有のサービスに依存することのリスクも伴います。この点は、多くのプロジェクトで検討すべき重要なトレードオフです。
Packaged Cluster Distribution
パッケージ化されたクラスター配布は、よりカスタマイズ可能で、組織固有のニーズに合わせた設定が可能です。Kubernetesのようなオープンソースソリューションの利用は、柔軟性をもたらしますが、メンテナンスとサポートにおいて自組織のリソースを要求します。
Stack Topologies for Application Clusters
アプリケーションクラスターのスタックトポロジーについては、モノリシックなスタックと分散型スタックの両方が詳述されています。私の観点からは、モノリシックなアプローチは小規模なプロジェクトや初期段階でのプロトタイピングに適しています。しかし、規模が大きくなると、スタックを分割し、各機能を別々に管理することで、より効率的な運用と拡張性が得られます。特に大規模なシステムでは、分散型のアプローチがシステムの複雑さを管理しやすくします。
Monolithic Stack Using Cluster as a Service
モノリシック・スタックを使用する場合、初期段階では管理が簡単ですが、規模が大きくなるにつれて、複雑さとリスクが増大します。このアンチパターンは、特に大規模なシステムでの問題につながり得ます。
Monolithic Stack for a Packaged Cluster Solution
パッケージ化されたクラスター・ソリューションにおけるモノリシック・スタックは、より管理が複雑ですが、カスタマイズの自由度が高いです。インフラのスタックとアプリケーションのクラスターが別々に管理される点は、運用において重要な考慮事項です。
Pipeline for a Monolithic Application Cluster Stack
モノリシック・アプリケーション・クラスター・スタックのパイプラインは、インフラとアプリケーションの両方に影響を及ぼします。この一元管理は、変更の際に大きな影響を及ぼす可能性があります。
Example of Multiple Stacks for a Cluster
クラスターのための複数スタックの例は、変更の影響を局所化し、リスクを分散させるのに役立ちます。スタックを分割することで、より効率的かつ安全に変更を行うことができます。
Sharing Strategies for Application Clusters
アプリケーションクラスターの共有戦略に関するセクションは、特に多様な環境やニーズを持つ組織にとって重要です。一つの大きなクラスターをすべての用途に使用するのではなく、目的やチームごとにクラスターを分割することで、セキュリティ、パフォーマンス、および管理の観点から優れた結果を得ることができます。私の経験上、チームやプロジェクトごとに専用のクラスターを用意することは、リソースの効率的な利用とセキュリティリスクの軽減に繋がります。また、ガバナンスやコンプライアンスの要件に基づいてクラスターを分割することは、特に規制の厳しい業界での運用において重要です。
One Big Cluster for Everything
全てを一つの大きなクラスターで管理するアプローチは、シンプルさと効率の面で魅力的ですが、変更管理の複雑さやリスクの集中が懸念されます。
Separate Clusters for Delivery Stages
異なるデリバリー段階ごとに別々のクラスターを用意する戦略は、リスクの分散と環境間の独立性を提供します。これにより、特定の環境に特化した最適化が可能になります。
Clusters for Governance
ガバナンスのためのクラスターは、特定のコンプライアンス要件を持つアプリケーションに対して、より厳格な環境を提供することができます。これにより、セキュリティとパフォーマンスの向上が期待できます。
Clusters for Teams
チームごとのクラスターは、チームの特定のニーズに合わせたカスタマイズを可能にします。これは、チームの生産性を向上させると同時に、システムの全体的な効率を高めることができます。
Service Mesh
サービスメッシュは、アプリケーション間の通信を効率化し、複雑な分散システムにおける管理を容易にします。これにより、開発者はアプリケーションのロジックに集中でき、インフラストラクチャの詳細から解放されます。
Infrastructure for FaaS Serverless
FaaS Serverlessのインフラストラクチャは、従来のアプリケーション・ホスティングとは異なり、イベント駆動のコード実行をサポートします。これにより、負荷が不規則なワークロードに対して、高い効率性とスケーラビリティが得られます。
この章の総括として、クラスターをコードとして構築するアプローチは、アプリケーションをサポートするためのインフラストラクチャを効率的に管理するための強力な方法です。個々の技術や戦略の選択は、組織の特定のニーズに基づいて行われるべきです。
まとめ
サーバーとその他のアプリケーションランタイムプラットフォームの扱いに焦点を当てています。このセクションは、現代のインフラストラクチャ管理における重要なトピックを深く掘り下げており、Infrastructure as Code (IaC) の実践において不可欠な洞察を提供しています。特に、アプリケーションクラスターの構築、スタックトポロジーの設計、そしてクラスター共有戦略の選択に関する章は、システムのスケーラビリティと耐障害性を高める方法論を提示しています。これらの章では、クラウドサービスとオンプレミスソリューションの利点と欠点が比較され、プロジェクトの要件に応じた適切な選択を行うための洞察が提供されています。本書は、インフラストラクチャをコードとして扱うことの重要性を強調し、変更管理、セキュリティ、およびコンプライアンスを効率的に運用するための具体的な手法を提供しています。また、サービスメッシュやサーバーレスアーキテクチャなどの先進的なトピックにも言及し、読者がこれらの技術を理解し、適切に活用するためのガイダンスを提供しています。全体を通して、この部分は、インフラストラクチャの自動化とオーケストレーションに関する実用的なアプローチを強調しており、読者がより堅牢で効率的なシステムを構築するための知識を深めるのに役立ちます。結果として、サーバーとアプリケーションランタイムプラットフォームの管理において、より戦略的で洗練されたアプローチを採用するための基盤を築くことができます。
Infrastructure as Code, 2nd Editionの読書感想文
- Infrastructure as Code, 2nd Edition の I. Foundations 読書感想文 - じゃあ、おうちで学べる
- Infrastructure as Code, 2nd Edition のII. Working With Infrastructure Stacks 読書感想文 - じゃあ、おうちで学べる
- Infrastructure as Code, 2nd Edition の III. Working With Servers And Other Application Runtime Platforms 読書感想文 - じゃあ、おうちで学べる
- Infrastructure as Code, 2nd Edition のIV. Designing Infrastructure 読書感想文 - じゃあ、おうちで学べる
- Infrastructure as Code, 2nd Edition のV. Delivering Infrastructure 読書感想文 - じゃあ、おうちで学べる