はじめに
本書『Observability Engineering』は、複雑化の一途をたどる現代のソフトウェアシステムに立ち向かうための、強力な武器となる一冊であり本稿はその読書感想文です。Observability Engineering を今から知りたい方はもちろん、Observability Engineering の基礎を改めて学びたい方もぜひお読みください。この記事もかなりの長さになるので普通に書籍を読んだほうがいいかもです
「Observability:可観測性」という言葉は、近年ソフトウェアエンジニアリングの世界で大きな注目を集めています。しかし、その概念の本質を理解し、実践に移すことは容易ではありません。
本書は、そのオブザーバビリティについて、その基本的な考え方から、具体的な実装方法、そして組織への適用まで、幅広くかつ深く解説しています。著者らは、Honeycombというオブザーバビリティプラットフォームの開発に携わった経験から、その知見を余すところなく共有しています。
")
私自身、2022年に本書を読んだ際には、その内容を理解したつもりになっていました。しかし、色んな経験や話を聞いた今になって再読してみると、当時の理解は表面的なものに過ぎなかったことに気づかされます。人間や組織の話もめちゃくちゃにぶつかったのでその内容がドンピシャでもあった。
自分が何を大事にしているのかを見失わないためには、新しい書籍や新しい資料を読むよりも、一度立ち止まって原書を振り返るのも良いかもしれません。再読は、わからなさという困難を洗練させ、既知と未知のネットワークを創造的に発展させる知的技術であり、自分自身と向き合い、本の内容を理解するための行為なのです。

現在、様々なシステムではマイクロサービスアーキテクチャを採用し、その規模と複雑さを増す一方です。その中で、システムの動作を把握し、問題の原因を特定することがいかに難しいかを日々実感しているかと思います。本書で説かれているオブザーバビリティの考え方は、まさにその難題に対する答えとも言えるものでした。
本書を通じて、オブザーバビリティとは単なるツールの問題ではなく、システムと向き合うための思想そのものだと理解できました。そして、その理解は私たちのチームの実装にも反映され、システムの可視性と理解度は格段に向上しています。
また、本書はオブザーバビリティがもたらす組織文化の変革についても示唆に富んでいます。部署間のサイロを打ち破り、エンジニア全員がシステムの全体像を共有する。そのような文化があってこそ、真のオブザーバビリティが実現できるのだと納得させられました。
本書は、現代のソフトウェア開発に携わる全てのエンジニアにとって、必読の一冊だと言えます。システムの複雑さに悩まされている方、モニタリングの限界を感じている方、チームのコミュニケーションを改善したい方。本書はそのような様々な課題を抱えるエンジニアに、明確な指針を与えてくれるはずです。また、翻訳版もあります。ありがたいので両方読みましょう。

オブザーバビリティについて何も分からない場合には、まずは、本ブログを読む前にkatzchangさんの発表をご覧になることをお勧めします。この発表では、オブザーバビリティの概念や重要性、実践的な手法などが丁寧に解説されています。発表内容を理解することで、オブザーバビリティに関する基礎知識を身につけることができると思います。
タイトルは株式会社Topotalの高村さんと菱田さんが行っている。もう一度読むSREを参考にさせていただきました。 っていうタイトルを使わせてもらおうと連絡したところ元ネタを教えていただいた。もう一つ好きになった。

『Observability Engineering』の内容紹介
本書は、オブザーバビリティの概念から実践までを網羅的に解説しており、現代のソフトウェア開発・運用に携わるエンジニアや管理職にとって必読の一冊と言えるでしょう。システムの安定稼働とパフォーマンス向上を目指す上で、オブザーバビリティは欠かせない要素であり、本書はその導入と実践に向けた最初の一歩を提供してくれます。
Part Iでは、オブザーバビリティの定義と、なぜ現代のシステムにおいてオブザーバビリティが重要であるかを解説しています。オブザーバビリティとモニタリングの違いについても言及し、システムの複雑さや規模が増大する中で、オブザーバビリティという新しいアプローチの必要性を訴えています。
Part IIは、オブザーバビリティの技術的な側面に焦点を当てています。構造化イベントの重要性や、分散トレーシングの役割、OpenTelemetryを用いた計装方法などが解説されています。また、オブザーバビリティとモニタリングの使い分けについても言及しています。
Part IIIでは、チームや組織にオブザーバビリティを導入するための方法論が紹介されています。具体的には、オブザーバビリティ駆動開発、SLO(サービスレベル目標)との連携、ソフトウェアサプライチェーンへのオブザーバビリティの適用などが取り上げられています。
Part IVは、大規模システムにおけるオブザーバビリティの実践について述べています。オブザーバビリティツールの選定基準や、データストアの設計、サンプリング戦略、テレメトリーパイプラインの構築などが解説されています。
Part Vでは、組織全体でオブザーバビリティ文化を醸成するための方法が紹介されています。オブザーバビリティ投資の対効果や、ステークホルダーとの連携、オブザーバビリティ成熟度モデルなどが説明されています。
本書を再読することで、オブザーバビリティに関する知識が深まり、既知の部分と未知の部分がつながって新しい理解が生まれました。この創発的な経験は、今後のオブザーバビリティの実践に役立つことでしょう。
")
書籍のRepository
以下のリポジトリには関連書籍のサンプルコードが収録されています。Go言語が苦も無く読める場合には学びになるのでここをまず見るのもありだと思う。
目次
- はじめに
- Part I. The Path to Observability
- Part II. Fundamentals of Observability
- Part III. Observability for Teams
- Part IV. Observability at Scale
- Part V. Spreading Observability Culture
- さいごに
- 参考資料
Part I. The Path to Observability
本書の第一部では本書の残りの部分で参照される概念を定義します。オブザーバビリティとは何か、オブザーバブルなシステムを特定する方法、およびオブザーバビリティベースのデバッグ技術が、モニタリングベースのデバッグ技術よりもモダンなソフトウェアシステムの管理に適している理由を言及してくれています。オブザーバビリティに関する別のオススメの書籍として、『Distributed Systems Observability』1を紹介しておきます。この書籍では、分散システムにおけるオブザーバビリティの重要性と、その実現方法について詳細に解説されています。
Chapter 1. What Is Observability?
オブザーバビリティの概念とその重要性
「Chapter 1. What Is Observability?」は、オブザーバビリティの概念とその適用方法について非常に詳細かつ体系的に解説した章です。本書は、オブザーバビリティの数学的起源から始まり、ソフトウェア工学への適用、そしてモダンなシステムにおける必要性まで、丁寧に説明しています。
本書によると、ソフトウェアシステムの文脈では、オブザーバビリティは以下の要件を満たすことを意味します。
- アプリケーションの内部動作を理解できる
- アプリケーションが取りうる任意の状態を理解できる
- 外部ツールを用いて内部動作と状態を理解できる
- 新しいコードをデプロイせずに内部状態を理解できる
つまり、オブザーバビリティとは、システムの内部動作と状態を外部から観測し、理解できることを指します。 これにより、エンジニアはシステムの動作を深く理解し、問題の根本原因を特定することができるのです。
この章で特に印象的だったのは、本書が従来のモニタリングアプローチとオブザーバビリティの違いを明確に示したことです。モニタリングは長年にわたってシステムを理解するための主要な手段でしたが、本書は、モニタリングには本質的な限界があると指摘しています。
モニタリングは、予測可能な障害モードを検出するのには役立ちますが、予測不可能な障害モードに対応するのが難しいのです。 これは、モニタリングが事前に定義されたメトリクスとしきい値に依存しているためです。エンジニアは、想定される障害モードを予測し、それに応じてダッシュボードを設定する必要があります。しかし、モダンなシステムが複雑で動的であるため、すべての障害モードを事前に予測することは不可能です。
これに対して、オブザーバビリティは、システムの内部状態を理解するための新しいアプローチを提供します。オブザーバビリティツールは、高カーディナリティ(一意性)と高次元のデータを収集し、問題の根本原因を特定するための柔軟なクエリを可能にします。 これにより、エンジニアは予測不可能な障害モードを見つけ出し、迅速に対応することができるのです。
本書は、オブザーバビリティの重要な概念として「探索可能性(explorability)」を紹介しています。これは、システムに対して任意の質問をし、その内部状態を検査できる程度を表します。つまり、事前に予測することなく、システムが取りうる任意の状態を反復的に調査し、理解できるということです。 この概念は、モニタリングとは根本的に異なります。モニタリングでは、事前に定義されたメトリクスとしきい値に基づいてシステムを監視しますが、オブザーバビリティでは、データを柔軟に探索し、新しい洞察を得ることができるのです。

また、本書は、カーディナリティと次元の役割について詳しく説明しています。カーディナリティは、データセット内の一意の値を表し、次元はそのデータ内のキーの数を表します。オブザーバビリティツールは、高カーディナリティと高次元のデータを処理するように設計されており、これによりエンジニアは問題のあらゆる側面を調査することができるのです。 一方、モニタリングツールは、低カーディナリティのデータを処理するように設計されており、データの探索力に限界があります。
オブザーバビリティとモニタリングの違い
さらに、本書は、オブザーバビリティとモニタリングの目的の違いについても言及しています。モニタリングの主な目的は、システムの稼働時間を最大化し、障害を防ぐことです。一方、オブザーバビリティの目的は、システムの動作を深く理解し、パフォーマンスを最適化することです。オブザーバビリティは、障害を防ぐだけでなく、システムの継続的な改善を可能にするのです。
本書は、オブザーバビリティがモダンなシステム、特に疎結合で動的かつ推論が難しい分散システムにとって不可欠であると強調しています。これらのシステムでは、予測不可能な障害モードが頻繁に発生するため、従来のモニタリングアプローチでは対応が難しいのです。オブザーバビリティは、これらの課題を克服し、システムの信頼性と性能を向上させるための強力な手段なのです。
オブザーバビリティの必要性とその将来
要約すると、「Chapter 1. What Is Observability?」は、オブザーバビリティとモニタリングの違いを明確に示し、オブザーバビリティの重要性を説得力のある形で伝えています。 本書は、モニタリングの限界を指摘し、オブザーバビリティがそれを克服するための鍵であることを論じています。また、探索可能性、カーディナリティ、次元といった重要な概念を導入し、オブザーバビリティを実現するための具体的な要件を示しています。
この章は、モダンなシステムを管理するすべてのソフトウェアエンジニアにとって必読の内容です。 オブザーバビリティは、システムの信頼性と性能を向上させるための不可欠なツールであり、エンジニアはこの概念を深く理解する必要があります。また、この章は、オブザーバビリティとモニタリングの違いを明確に示しており、エンジニアがシステム管理のアプローチを選択する際の指針となるでしょう。
Chapter 2. How Debugging Practices Differ Between Observability and Monitoring
「Chapter 2. How Debugging Practices Differ Between Observability and Monitoring」は、モニタリングとオブザーバビリティを用いたデバッグ手法の違いについて、非常に詳細かつ具体的に解説した章です。本書は、従来のモニタリングに基づくデバッグ手法の限界を多角的に分析し、オブザーバビリティがそれらの限界をどのように克服するのかを、説得力のある事例を交えて明確に示しています。
モニタリングを用いたデバッグの限界
本書は、モニタリングを用いたデバッグ手法の特徴と限界について、詳細な説明を提供しています。モニタリングは、システムの状態を事前に定義された閾値と比較することで、異常を検知するための手法です。エンジニアは、メトリクスとダッシュボードを使って、システムのパフォーマンスを監視し、問題が発生したときに通知を受け取ります。
この手法は、既知の障害モードを検出するのには非常に有効です。 エンジニアは、過去の経験に基づいて、どのようなメトリクスが問題を示唆するのかを理解しており、それらのメトリクスに基づいてアラートを設定することができます。しかし、本書は、この手法には重大な限界があると指摘しています。
まず、モニタリングは、予測不可能な障害モードに対応するのが難しいという点です。モニタリングでは、事前に定義された閾値に基づいてアラートが発生するため、閾値が設定されていない問題を見落とす可能性があります。また、閾値を超えても、必ずしも問題があるとは限りません。誤検知が多発すると、アラート疲れを引き起こし、重大な問題を見落とすリスクがあるのです。
次に、モニタリングは、問題の根本原因を特定するのが難しいという点です。モニタリングツールは、メトリクスを収集し、集約することで、システムの全体的なパフォーマンスを可視化します。しかし、集約されたメトリクスでは、問題の根本原因を特定するのに十分な情報が得られないことがあります。エンジニアは、ダッシュボードを見ながら、自分の経験と直感に頼って、問題の原因を推測しなければなりません。
さらに、モニタリングツールは、データの探索性に乏しいという点も問題です。多くのモニタリングツールでは、ダッシュボードが事前に定義された条件に基づいて構築されるため、エンジニアは、ダッシュボードに表示されている情報だけを頼りに問題を調査しなければなりません。新しい問題が発生した場合、ダッシュボードを修正するまで、その問題を発見することは困難なのです。
本書は、これらの限界により、モニタリングに基づくデバッグ手法は本質的に受動的であると述べています。エンジニアは、既知の問題を検出することはできますが、新しい問題を発見し、その根本原因を特定することは困難です。このような受動的なアプローチでは、問題が発生してから対応するのではなく、問題を予防することは難しいのです。
オブザーバビリティがもたらすデバッグの改善
本書は、オブザーバビリティがデバッグ手法に革新をもたらすと主張しています。オブザーバビリティは、システムの内部状態を外部から観測し、理解するための仕組みです。オブザーバビリティツールは、高カーディナリティ(一意性)と高次元のデータを収集し、柔軟なクエリを可能にすることで、エンジニアがシステムの動作を詳細に理解できるようにします。
オブザーバビリティの最大の強みは、データの探索性にあります。 オブザーバビリティツールは、収集したデータに対して、自由にクエリを実行し、絞り込みを行うことができます。これにより、エンジニアは、システムの動作を多角的に分析し、問題の根本原因を特定することができるのです。
本書は、オブザーバビリティがもたらす具体的な改善点として、以下の3つを挙げています。
制度的知識への依存の減少:モニタリングに基づくデバッグ手法では、システムに関する深い知識と経験が求められます。そのため、ベテランのエンジニアに依存することが多く、ナレッジの共有が難しいという問題がありました。オブザーバビリティツールを使えば、経験の浅いエンジニアでも、システムを自由に探索し、問題を診断することができます。 これにより、チーム全体のデバッグ能力が向上し、ナレッジの共有が促進されるのです。
隠れた問題の発見:モニタリングでは、事前に定義された閾値に基づいてアラートが発生するため、閾値が設定されていない問題を見落とす可能性があります。オブザーバビリティは、予測不可能な障害モードを発見し、その根本原因を特定するための強力な手段となります。 高カーディナリティと高次元のデータを収集することで、システムの動作を詳細に分析できるため、これまで見落とされていた問題を発見できる可能性が高まるのです。
問題診断に対する自信の向上:モニタリングツールでは、複数のデータソースを行き来しながら、問題を診断しなければなりません。このため、エンジニアは、自分の経験と直感に頼らざるを得ず、問題の診断に自信を持てないことがあります。オブザーバビリティツールは、複数のデータソースを統合し、一貫したコンテキストを提供します。 これにより、エンジニアは、システムの動作を詳細に理解し、問題を自信を持って診断できるようになるのです。
本書は、これらの改善点を、モニタリングとオブザーバビリティの違いを浮き彫りにする具体的な例を交えて説明しています。例えば、あるエンジニアがデータベースにインデックスを追加した場合、モニタリングツールでは、インデックスの効果を確認するのが難しいかもしれません。しかし、オブザーバビリティツールを使えば、クエリのパフォーマンスを詳細に分析し、インデックスの効果を確認できるのです。
また、本書は、オブザーバビリティがシステムの予防保全にも役立つと述べています。オブザーバビリティツールを使えば、システムの動作を常に監視し、問題の兆候を早期に発見することができます。これにより、問題が発生する前に対策を打つことができ、システムの可用性と信頼性が向上するのです。
オブザーバビリティの重要性
従来のモニタリングに基づくデバッグ手法は、システムの複雑化に伴って限界に直面しています。モニタリングは、既知の問題を検出するのには有効ですが、予測不可能な問題に対応するのが難しいのです。また、モニタリングでは、問題の根本原因を特定するのが難しく、エンジニアは自分の経験と直感に頼らざるを得ません。
一方、オブザーバビリティは、これらの限界を克服するための強力な手段を提供します。 オブザーバビリティツールは、高カーディナリティと高次元のデータを収集し、柔軟なクエリを可能にすることで、エンジニアがシステムの動作を詳細に理解できるようにします。これにより、エンジニアは、予測不可能な問題を発見し、その根本原因を特定することができるのです。
また、オブザーバビリティは、エンジニアリングチームのデバッグ能力を大幅に向上させます。オブザーバビリティツールを使えば、経験の浅いエンジニアでも、複雑なシステムの問題を自信を持って診断できるようになります。これにより、チーム全体のデバッグ能力が向上し、ナレッジの共有が促進されるのです。
さらに、オブザーバビリティは、システムの予防保全にも役立ちます。オブザーバビリティツールを使えば、システムの動作を常に監視し、問題の兆候を早期に発見することができます。これにより、問題が発生する前に対策を打つことができ、システムの可用性と信頼性が向上するのです。
本章は、モニタリングとオブザーバビリティという2つのデバッグ手法の違いを明確に示し、オブザーバビリティの重要性を説得力のある形で伝えています。 本書は、モニタリングの限界を詳細に分析し、オブザーバビリティがそれらの限界を克服するための強力な手段であることを、具体的な事例を交えて論証しています。
Chapter 3. Lessons from Scaling Without Observability
「Chapter 3. Lessons from Scaling Without Observability」は、著者の一人であるCharity MajorsがParseでの経験を通して、オブザーバビリティなしでスケーリングすることの難しさと、そこから学んだ教訓について語った章です。モダンな分散システムを従来のモニタリングツールで管理することの限界と、オブザーバビリティの必要性が具体的な事例を通して説明されています。
Parseにおけるスケーリングの課題
Parseは、モバイルアプリ開発者にバックエンドサービスを提供するプラットフォームでした。著者がParseに参加した当初、同社はまだベータ版のサービスを提供している段階で、Amazon CloudWatchを使用していました。本書は、Icinga/NagiosとGangliaに切り替えましたが、これらのツールはParseのニーズに十分に対応できませんでした。
Parseは、マイクロサービスアーキテクチャを早期に採用し、MongoDBをデータストアとして使用していました。Ruby on Railsで開発を行い、複数のデータベースシャードをサポートするためにRailsにモンキーパッチを当てる必要がありました。Parseは、開発スピードを最優先に考えていましたが、これは正しい判断でした。 早期の技術選択は後に修正が必要になりましたが、顧客を満足させ、市場でニーズを見出すことができたからです。
しかし、Parseが成長するにつれて、選択したアーキテクチャとツールの限界が明らかになってきました。あるノルウェーのデスメタルバンドのアプリがiTunesストアで上位にランクインした際、Parseはわずか数秒でダウンしてしまいました。これは、同社のスケーリングの問題を浮き彫りにしました。
モダンシステムへの進化
本書は、Parseが直面した課題を、ソフトウェア業界全体の変化と関連づけて説明しています。かつては、「アプリ」と「データベース」という単純な構成が主流でしたが、現在では、モノリシックなアプリケーションからマイクロサービスへの移行、多様なデータストアの採用、コンテナやサーバーレスなどのインフラストラクチャの活用など、大きな変化が起こっています。
これらの技術的な変化は、組織や文化にも大きな影響を与えています。かつては、開発チームと運用チームの間に高い障壁があり、コードのデプロイが不安定さを引き起こすことが多かったため、運用チームは変更を嫌がる傾向にありました。しかし、モダンなシステムでは、マイクロサービスの採用により、サービスの段階的なロールアウトやフィーチャーフラグの活用が可能になり、デプロイのリスクが軽減されています。
モダンな実践へのシフト
本書は、これらの技術的な変化に伴い、エンジニアリングチームの実践もシフトする必要があると主張しています。
ステージング環境は、モノリシックなシステムでは有用でしたが、分散システムでは、本番環境を完全に再現することが難しいため、その価値は低下しています。このため、デバッグや検査は本番環境で行う必要があります。
また、ユーザーエクスペリエンスは、すべてのユーザーに対して一般化できなくなりました。サービスの異なるユーザーが、異なるコンポーネントを使って異なる経路をたどる可能性があるためです。
モニタリングにおいても、既知の閾値を超えるエッジケースを探すアラートは、多くの誤検知を生み出します。アラートは、ユーザーエクスペリエンスに直接影響を与える症状にのみ焦点を当てるべきです。
これらの変化は、本番環境に精通することの重要性を高めています。かつては、本番環境への変更を恐れ、問題が発生したらすぐにロールバックする傾向がありましたが、モダンなシステムでは、エンジニアが本番環境を深く理解し、問題に対して細やかな調整を行えるようになる必要があるのです。
Parseにおける実践のシフト
Parseでは、従来のアプローチでは対応できない新しい問題が次々と発生し、ヒーロー文化の限界が明らかになりました。かつては、最も経験豊富なエンジニアが最高のデバッガーでしたが、これはスケールしません。
Facebookに買収された後、著者はScubaというデータ管理システムに出会いました。Scubaは、リアルタイムでデータを細かくスライスアンドダイスできる機能を提供し、新しい問題の原因をわずか数分で特定できるようになりました。
この経験から、本書では、問題を新しいものとしてアプローチし、データに基づいて真の原因を特定することの重要性を学びました。オブザーバビリティにより、マイクロサービス、ポリグロットストレージシステム、マルチテナンシーなど、従来のアプローチでは扱いが難しかった問題を、迅速かつ効果的に診断できるようになったのです。
様々な経験を経たオブザーバビリティの重要性
著者の経験は、従来のモニタリングアプローチから、モダンな分散システムとオブザーバビリティへの移行の必要性を示しています。
オブザーバビリティは、モダンなシステムのスケーリングに伴う問題を解決するための鍵です。 アプリケーションのテレメトリーを適切な抽象度で収集し、ユーザーエクスペリエンスを中心に集約し、リアルタイムで分析できるようにすることで、システムの内部動作を深く理解できるようになります。
オブザーバビリティにより、エンジニアリングチームは、システムの問題を迅速に特定し、根本原因を突き止められるようになります。 これにより、ヒーロー文化から脱却し、チーム全体でナレッジを共有し、効果的なデバッグを行えるようになるのです。
著者の経験は、多くの組織がモダンな分散システムを採用するにつれて、ますます一般的になっています。オブザーバビリティは、これらのシステムのスケーリングに不可欠なものとなっているのです。
Chapter 4. How Observability Relates to DevOps, SRE, and Cloud Native
「Chapter 4. How Observability Relates to DevOps, SRE, and Cloud Native」は、オブザーバビリティがDevOps、SRE、クラウドネイティブの実践とどのように関係しているかを解説した章です。本書は、これらの動きがオブザーバビリティの必要性を高めると同時に、オブザーバビリティがこれらの実践を強化していると主張しています。CNCFのドキュメントにも記載がありますがめちゃくちゃに簡潔です。
オブザーバビリティに関する包括的な解説書として、「Cloud Observability in Action」が挙げられます。この書籍では、クラウドネイティブシステムにおけるオブザーバビリティの適用方法、様々なオブザーバビリティシグナル(ログ、メトリクス、トレースなど)の特徴と費用対効果、適切なインストルメンテーションとシグナル収集の手法、大規模なダッシュボーディング、アラート、SLO/SLIの提供、役割やタスクに応じた適切なシグナルタイプの選択、目的に応じた最適なオブザーバビリティツールの選び方、経営陣へのオブザーバビリティの効果のコミュニケーション方法などが解説されています。
適切に設計されたオブザーバビリティシステムは、クラウドネイティブアプリケーションのバグやパフォーマンス問題に関する洞察を提供します。開発チームがコード変更の影響を理解し、最適化を測定し、ユーザーエクスペリエンスを追跡するのに役立ちます。さらに、オブザーバビリティによってエラー処理を自動化し、マシンユーザーが自身で修正を適用できるようになるため、深夜の緊急障害発生による呼び出しも不要になります。
クラウドネイティブ、DevOps、SREの概要
本書は、モノリシックなアーキテクチャとウォーターフォール開発から、クラウドネイティブとアジャイル手法への移行が進んでいると指摘しています。クラウドネイティブは、スケーラビリティと開発速度の向上を目指していますが、同時に管理コストの増加という課題も抱えています。クラウドネイティブシステムを実現するには、継続的デリバリーやオブザーバビリティなどの高度な社会技術的実践が不可欠なのです。
また、DevOpsとSREは、フィードバックループを短縮し、運用の負担を軽減することを目指しています。DevOpsは、開発と運用の協調を通じて価値の提供を加速し、SREはソフトウェアエンジニアリングのスキルを活用して複雑な運用問題を解決します。クラウドネイティブ技術、DevOpsとSRE手法、オブザーバビリティの組み合わせは、それぞれの個別の要素よりも強力なのです。
※こちら、SREがもう少し気になる方向け syu-m-5151.hatenablog.com
オブザーバビリティ:昔と今のデバッグ
オブザーバビリティの目的は、システムの内部状態を理解するための内省を提供することです。モノリシックなシステムでは、詳細なアプリケーションログやシステムレベルのメトリクスを使用して、潜在的な障害箇所を予測し、デバッグすることができました。しかし、これらのレガシーツールと直感的なテクニックは、クラウドネイティブシステムの管理課題には対応できなくなっています。
クラウドネイティブ技術は、コンポーネント間の依存関係による認知的複雑さ、コンテナ再起動後に失われる一時的な状態、個別にリリースされるコンポーネント間のバージョン不整合など、新しい問題を引き起こします。分散トレーシングなどのツールを使用して、特定のイベントが発生したときのシステム内部の状態を捕捉することで、これらの問題をデバッグできるようになります。
オブザーバビリティがDevOpsとSREの実践を強化する
DevOpsとSREチームの仕事は、本番システムを理解し、複雑さを制御することです。したがって、彼らがシステムのオブザーバビリティに関心を持つのは自然なことです。SREはSLOとエラーバジェットに基づいてサービスを管理し、DevOpsは開発者が本番環境でコードに責任を持つ、クロスファンクショナルな実践を通じてサービスを管理します。
成熟したDevOpsとSREチームは、ユーザーに影響を与える症状を測定し、オブザーバビリティツールを使用して障害の理解を深めます。 これにより、チームは実際のシステム障害に対する仮説を体系的に絞り込み、緩和策を考案することに集中できるようになります。
さらに、先進的なDevOpsとSREチームは、フィーチャーフラグ、継続的検証、インシデント分析などのエンジニアリング手法を使用しています。オブザーバビリティは、これらのユースケースを効果的に実践するために必要なデータを提供することで、これらのユースケースを強化します。
- カオスエンジニアリングと継続的検証では、システムの基準状態を理解し、期待される動作を予測し、期待される動作からの逸脱を説明するためにオブザーバビリティが必要です。
- フィーチャーフラグでは、ユーザーごとにフィーチャーフラグの個別の影響と集合的な影響を理解するためにオブザーバビリティが必要です。
- カナリアリリースやブルー/グリーンデプロイメントなどの段階的リリースパターンでは、リリースを停止するタイミングを知り、システムの期待値からの逸脱がリリースに起因するかどうかを分析するためにオブザーバビリティが必要です。
- インシデント分析と非難のない事後検証では、技術システムの内部で何が起こっていたかだけでなく、インシデント中にオペレーターが何を信じていたかを明確にモデル化する必要があります。オブザーバビリティツールは、事後の記録を提供し、回顧録の作成者に詳細な手がかりを与えることで、優れた振り返りを行うことを可能にします。
再三だがオブザーバビリティの重要性
本章の結論として、DevOps、SRE、クラウドネイティブの実践が進化し、プラットフォームエンジニアリングが包括的な規律として成長するにつれ、より革新的なエンジニアリング実践がツールチェーンに現れるだろうと述べています。しかし、これらのイノベーションはすべて、現代の複雑なシステムを理解するための中核的な感覚としてオブザーバビリティを必要とするでしょう。
DevOps、SRE、クラウドネイティブの実践への移行は、オブザーバビリティのようなソリューションの必要性を生み出しました。一方、オブザーバビリティは、その実践を採用したチームの能力を飛躍的に高めてきました。
オブザーバビリティは、モダンなソフトウェア開発と運用に不可欠な要素となっています。 それは、複雑なシステムを理解し、問題を迅速に特定し、根本原因を突き止めるための強力なツールを提供します。また、オブザーバビリティは、DevOpsとSREの実践を強化し、カオスエンジニアリング、フィーチャーフラグ、段階的リリース、インシデント分析などのエンジニアリング手法を効果的に実践するためのデータを提供します。
クラウドネイティブ、DevOps、SREの動きは、オブザーバビリティの必要性を高めると同時に、オブザーバビリティがこれらの実践を強化しているのです。オブザーバビリティは、モダンなソフトウェアエンジニアリングにおいて不可欠な要素であり、その重要性はますます高まっていくでしょう。
Part II. Fundamentals of Observability
本書の第2部では、オブザーバビリティの技術的な側面について深く掘り下げ、オブザーバブルなシステムにおいて特定の要件が必要とされる理由を詳しく説明します。
Chapter 5. Structured Events Are the Building Blocks of Observability
「Chapter 5. Structured Events Are the Building Blocks of Observability」は、オブザーバビリティの基本的な構成要素である構造化イベントについて詳しく解説した章です。本書はオブザーバビリティを実現するために、任意の幅を持つ構造化イベントが不可欠であると主張し、構造化イベントの概念、利点、オブザーバビリティにおける役割について深く掘り下げています。構造化イベントの背景を理解するには、マイクロサービスアーキテクチャの知識が役立ちます。「Monolith to Microservices」は、従来のモノリシックなアーキテクチャからマイクロサービスへの移行プロセスを詳しく解説しており、様々な具体例、洞察に富んだ移行パターン、実務的なアドバイスが満載です。初期計画からアプリケーション・データベースの分解に至るまで、移行の様々なシナリオやストラテジーが網羅されており、既存アーキテクチャの移行に役立つ試行済みのパターン・テクニックを学ぶことができます。マイクロサービスへの移行を検討する組織にとって理想的な一冊であり、移行の是非、タイミング、開始地点の判断を支援するだけでなく、レガシーシステム移行、マイグレーションパターン、データベース移行例、同期戦略、アプリケーション分解、データベース分解の詳細などについても掘り下げられています。
オブザーバビリティと構造化イベント
オブザーバビリティとは、システムが取りうる任意の状態を理解し、説明できる程度を表します。そのためには、事前に予測することなく、あらゆる質問に答えられるようにしなければなりません。これを可能にするのが、構造化イベントなのです。
構造化イベントとは、1つのリクエストがサービスと相互作用している間に発生したすべてのことを記録したものです。リクエストの入力時に既知のデータを事前に入力し、実行中に発見された有用な情報を追加し、リクエストの出力時やエラー時にパフォーマンスに関するデータを記録します。
例えば、あるウェブサーバーへのリクエストでは、リクエストに含まれる各パラメータ(ユーザーIDなど)、意図したサブドメイン(www、docs、support、shopなど)、合計処理時間、依存する子リクエスト、それらの子リクエストを満たすために関与する様々なサービス(web、database、auth、billingなど)、各子リクエストの処理時間などを記録することができます。
このように、構造化イベントには、リクエストの実行に関するコンテキストを表すデータが豊富に含まれています。 成熟した計装では、イベントごとに300〜400のディメンションが含まれることが一般的だそうです。
構造化イベントを使ってサービスの動作を理解する際には、後でデバッグに関連する可能性のあるものを何でも記録するというモデルを覚えておく必要があります。これには、リクエストパラメータ、環境情報、ランタイムの内部情報、ホストやコンテナの統計情報などが含まれます。
メトリクスの限界
本書は、メトリクスの限界についても詳しく説明しています。メトリクスに関しては改定した『Prometheus: Up & Running, 2nd Edition』も紹介しておきます。
メトリクスとは、事前に定義された期間にわたってシステムの状態を表す数値を収集し、必要に応じてタグを付けてグループ化や検索を可能にしたものです。メトリクスは、従来のソフトウェアシステムの監視の中核をなすものです。
しかし、メトリクスの根本的な限界は、それが事前に集約された測定値だということです。メトリクスによって生成される数値は、事前に定義された期間におけるシステム状態の集約レポートを反映しています。この事前集約された測定値は、システム状態を調べるための最小の粒度となり、多くの潜在的な問題を覆い隠してしまうのです。
例えば、page_load_timeというメトリクスは、直近の5秒間にすべてのアクティブページの読み込みにかかった平均時間を調べるかもしれません。requests_per_secondというメトリクスは、直近の1秒間にあるサービスがオープンしていたHTTP接続の数を調べるかもしれません。
メトリクスは、特定の期間に測定されたプロパティの数値で表現されるシステムの状態を反映しています。 その期間中にアクティブだったすべてのリクエストの動作は、1つの数値に集約されます。この例では、そのシステムを流れる特定のリクエストの存続期間中に何が起こったかを調査することは、これらのメトリクスにつながる一連の痕跡を提供することになります。しかし、さらに掘り下げるために必要な粒度のレベルは利用できません。
このように、メトリクスは、1つのシステムプロパティの1つの狭いビューとしてのみ機能します。粒度が大きすぎ、システムの状態を別のビューで表示する能力が硬直していて、1つのサービスリクエストの作業単位を表すために組み合わせるには限界があります。
非構造化ログの限界
本書は、非構造化ログの限界についても言及しています。
ログファイルは、本質的に大きな非構造化テキストの塊であり、人間が読めるように設計されていますが、機械で処理するのは難しいです。これらのファイルは、アプリケーションや様々な基盤システムによって生成される文書で、設定ファイルで定義された、注目に値するすべてのイベントの記録が含まれています。
従来のログは、人間が読みやすいように設計されているため、非構造化になっています。残念ながら、人間が読みやすくするために、ログではしばしば、1つのイベントの生々しい詳細が複数行のテキストに分割されてしまいます。
例えば、以下のようなログがあるとします。
6:01:00 accepted connection on port 80 from 10.0.0.3:63349 6:01:03 basic authentication accepted for user foo 6:01:15 processing request for /super/slow/server 6:01:18 request succeeded, sent response code 200 6:01:19 closed connection to 10.0.0.3:63349
このような物語形式の構造は、開発段階でサービスの詳細を学ぶ際には役立ちますが、大量のノイズデータを生成し、本番環境では遅くて扱いにくくなります。
非構造化ログは人間が読めますが、計算的に使用するのは難しいのです。 一方、構造化ログは機械で解析可能です。上の例は、構造化ログに書き換えると以下のようになります。
time="6:01:00" msg="accepted connection" port="80" authority="10.0.0.3:63349" time="6:01:03" msg="basic authentication accepted" user="foo" time="6:01:15" msg="processing request" path="/super/slow/server" time="6:01:18" msg="sent response code" status="200" time="6:01:19" msg="closed connection" authority="10.0.0.3:63349"
さらに、これらのログ行を1つのイベントにまとめると、以下のようになります。
{ "authority":"10.0.0.3:63349", "duration_ms":123, "level":"info", "msg":"Served HTTP request", "path":"/super/slow/server", "port":80, "service_name":"slowsvc", "status":200, "time":"2019-08-22T11:57:03-07:00", "trace.trace_id":"eafdf3123", "user":"foo" }
このように、構造化ログは、構造化イベントに似るように再設計されていれば、オブザーバビリティの目的に役立ちます。
デバッグに役立つイベントのプロパティ
新しい問題をデバッグするには、通常、外れ値の条件を持つイベントを検索し、パターンを見つけたり、それらを関連付けたりすることで、以前は知られていなかった障害モードを発見することを意味します。
そのような相関関係を見つけるには、オブザーバビリティソリューションが高カーディナリティのフィールドを処理できる必要があります。カーディナリティとは、セット内の一意の要素の数を指します。一意の識別子を含むディメンションは、可能な限り最高のカーディナリティを持ちます。
例えば、ある問題の原因を突き止めるために、「先週の火曜日にアプリをインストールした、ファームウェアバージョン1.4.101を実行している、写真をus-west-1のshard3に保存しているフランス語パックを使用しているiOS11バージョン11.0.4を実行しているすべてのカナダのユーザー」を見つけ出すクエリを作成する必要があるかもしれません。これらの制約のひとつひとつが、高カーディナリティのディメンションなのです。
オブザーバビリティツールは、調査員に役立つためには、高カーディナリティのクエリをサポートできる必要があります。 現代のシステムでは、新しい問題をデバッグするのに最も役立つディメンションの多くは、カーディナリティが高くなっています。
また、調査では、これらの高カーディナリティのディメンションを組み合わせる(つまり、高次元)ことで、深く隠れた問題を見つけ出すことがよくあります。高カーディナリティと高次元は、複雑な分散システムの干し草の山から、非常に細かい針を見つけ出すための機能なのです。
オブザーバビリティの基盤としての構造化イベント
本章の結論として、オブザーバビリティの基本的な構成要素は、任意の幅を持つ構造化イベントであると強調しています。
オブザーバビリティには、デバッグプロセスを反復的に進める際に、あらゆる質問に答えるために、任意の数のディメンションに沿ってデータをスライスアンドダイスする能力が必要です。 構造化イベントは、システムが1つの作業単位を達成したときに何が起こっていたかを理解するのに十分なデータを含んでいる必要があるため、任意の幅でなければなりません。
分散サービスの場合、これは通常、1つの個別のサービスリクエストの存続期間中に発生したすべてのことの記録として、イベントのスコープを設定することを意味します。
メトリクスは、システムの状態を表す1つの狭いビューとしてのみ機能します。粒度が大きすぎ、システムの状態を別のビューで表示する能力が硬直していて、オブザーバビリティの基本的な構成要素としては限界があります。
非構造化ログは人間が読めますが、計算的に使用するのは難しいです。構造化ログは機械で解析可能であり、構造化イベントに似るように再設計されていれば、オブザーバビリティの目的に役立ちます。
オブザーバビリティを実現するには、構造化イベントという形でテレメトリを収集し、高カーディナリティと高次元のデータを分析できる機能が不可欠なのです。
Chapter 6. Stitching Events into Traces
分散トレーシングの重要性
「Chapter 6. Stitching Events into Traces」は、構造化イベントをトレースに組み立てる方法と、その重要性について詳しく解説した章です。本書は、分散トレーシングが今日において重要である理由を詳細に説明しています。現代のソフトウェアシステムは、多数のサービスが連携して機能するマイクロサービスアーキテクチャが主流となっています。このような環境では、あるリクエストを処理するために、複数のサービスを横断する必要があります。
分散トレーシングは、そのリクエストがどのようにサービス間を移動し、処理されているかを追跡するための方法です。これにより、障害が発生した場所を特定し、パフォーマンスのボトルネックとなっている要因を特定することができます。マイクロサービスアーキテクチャの普及に伴い、このようなデバッグ手法の需要が高まっているのです。
また、分散システムでは、サービス間の依存関係が複雑になるため、問題の原因を特定することが非常に難しくなります。例えば、あるサービスがデータベースの応答を待っている間にレイテンシが累積し、上流のサービスに伝播していくことがあります。分散トレーシングは、このようなサービス間の関係を明確に示すことができるため、問題の根本原因を突き止めるために非常に有効なのです。
本書は、分散トレーシングが最初に注目を集めるようになったのは、2010年にGoogleがDapper論文を発表して以降だと述べています。Dapperは、Googleが社内で使用している分散トレーシングシステムで、大規模な分散システムのパフォーマンスを理解し、障害を特定するために開発されました。
Dapper論文の発表後、TwitterがZipkinを、UberがJaegerというオープンソースのトレーシングプロジェクトを立ち上げました。これらのプロジェクトは、Dapperの概念を基に、より一般的な用途に適したトレーシングシステムを提供しています。また、Honeycomb や Lightstep などの商用ソリューションも登場しています。
このように、分散トレーシングは、現代のソフトウェアシステムにおいて不可欠なツールとなっており、その重要性は日に日に高まっているのです。
トレーシングのコンポーネント
本書は、トレースを構成するコンポーネントについて、非常に詳細に説明しています。
トレースは、1つのリクエストに関連する一連のイベントを表します。これらのイベントは、トレーススパンと呼ばれる個々のチャンクで構成されています。各スパンは、リクエストの処理中に発生した作業の一部を表しており、その作業が行われたサービスや、作業の開始時刻と期間などの情報を含んでいます。

トレース内の各スパンは、ルートスパンと呼ばれるトップレベルのスパンの中にネストされています。ルートスパン自体は親を持ちませんが、その下のスパンは親子関係を持ちます。例えば、サービスAがサービスBを呼び出し、サービスBがサービスCを呼び出す場合、スパンAはスパンBの親であり、スパンBはスパンCの親であるという関係になります。

本書は、トレースを構築するために必要な5つのデータについても詳しく説明しています。
- トレースID:トレース全体を通して一意な識別子。ルートスパンによって作成され、リクエストの処理中に伝播される。
- スパンID:各スパンを一意に識別するための識別子。
- 親ID:スパンのネストの関係を定義するために使用されるフィールド。ルートスパンには存在しない。
- タイムスタンプ:スパンの作業が開始された時刻を示す。
- 期間:作業が完了するまでにかかった時間を記録する。
これらのフィールドは、トレースの構造を組み立てるために絶対に必要です。さらに、サービス名やスパン名などの追加のフィールドを含めることで、スパンを特定したり、システムとの関係を理解したりするのに役立ちます。
本書は、これらのコンポーネントがどのように機能するかを理解することが、分散トレーシングを効果的に活用するために重要だと強調しています。
トレースの手動インストルメンテーション
本書は、トレースのコアコンポーネントがどのように機能するかを理解するために、単純なトレーシングシステムを手動で実装する例を提示しています。
この例では、Goを使用して、3つのスパンを持つウェブエンドポイントを実装しています。
コードの例では、以下のステップでトレースを生成しています。
- ルートスパンでトレースIDとスパンIDを生成する。
- リクエストの開始時と終了時のタイムスタンプを取得し、その差分からスパンの期間を計算する。
- サービス名とスパン名を追加する。
- アウトバウンドのHTTPリクエストにトレースIDと親スパンIDを伝播させる。
さらに、デバッグに役立つ追加のフィールド(ホスト名、ユーザー名など)をスパンに追加する方法も示されています。

本書は、これらのコードの例が、トレーシングの概念を理解するために役立つものの、実際のアプリケーションでは、ボイラープレートコードを自分で書く必要はないと述べています。通常、トレーシングシステムには、これらの設定作業の大部分を行うためのライブラリが用意されています。
ただし、これらのライブラリは、特定のトレーシングソリューションに固有のものであることが多く、別のソリューションを試すためにはコードを再インストルメント化する必要があります。次章では、オープンソースでベンダーに依存しないOpenTelemetryプロジェクトについて説明します。
トレースへのイベントの組み込み
本書は、前章で説明した構造化イベントをトレースに組み込む方法についても言及しています。
イベントは、オブザーバビリティの構成要素であり、1つのリクエストがサービスとやり取りしている間に発生したすべてのことの記録です。リクエストの実行中に発生した興味深い詳細(変数の値、渡されたパラメータ、返された結果、関連するコンテキストなど)はすべてイベントに追加されるべきです。
コードの例では、リモートサービスの呼び出しレベルでインストルメンテーションを行っていますが、オブザーバブルなシステムでは、同じアプローチを使って、異なるソースからの任意の数の相関イベントを結びつけることができます。
例えば、現在の単一行のロギングソリューションから、より統合されたビューへの移行の第一歩として、構造化ログにトレースの概念を適用することができます。また、分散型ではないが、独自のスパンに分割したいような作業のチャンク(JSONのアンマーシャリングなどのCPU集約型の操作など)にも、同じ手法を使うことができます。
オブザーバブルなシステムでは、任意の一連のイベントをトレースに組み込むことができます。 トレーシングは、サービス間の呼び出しに限定される必要はありません。同じバッチジョブから作成されたすべての個別のファイルアップロードなど、システム内の相互に関連する離散的なイベントにも適用できます。
トレーシングの重要性とオープンソースフレームワークの活用
本章の結論として、イベントがオブザーバビリティの構成要素であり、トレースは単に相互に関連するイベントの系列であると強調しています。
スパンを結合してトレースを作成するために使用される概念は、サービス間の通信の設定に非常に役立ちます。 これらの概念を理解することは、分散システムの動作を理解し、問題の根本原因を特定するために不可欠です。
また、オブザーバブルなシステムでは、これらの同じ概念を、remote procedure call(RPC)を行うことを超えて、相互に関連するシステム内の離散的なイベントに適用することもできます。 これにより、システムの動作をより詳細に理解し、問題の原因を特定することができるようになります。
本章ではトレースを手動でインストルメント化する方法を示しましたが、より実用的な方法は、インストルメンテーションフレームワークを使用することだと述べています。次章では、オープンソースでベンダーに依存しないOpenTelemetryプロジェクトと、それを使って本番アプリケーションをインストルメント化する方法と理由について説明します。
分散トレーシングは、現代のソフトウェアシステムにとって不可欠なツールであり、オブザーバビリティを実現するための重要な要素です。 構造化イベントをトレースに組み立てることで、分散システムの動作を詳細に理解し、問題の根本原因を特定することができるようになります。
また、OpenTelemetryのようなオープンソースのインストルメンテーションフレームワークを活用することで、ベンダーロックインを避け、様々なトレーシングソリューションを柔軟に試すことができます。これにより、システムの可観測性を継続的に向上させ、より信頼性の高いサービスを提供することができるのです。
Chapter 7. Instrumentation with OpenTelemetry
「Chapter 7. Instrumentation with OpenTelemetry」は、オープンソースのインストルメンテーションフレームワークであるOpenTelemetryについて詳しく解説し、それを使って本番アプリケーションをインストルメント化する方法と理由を説明した章です。本書は、ベンダーに依存しない計装の重要性を強調し、OpenTelemetryの機能と利点を具体的に示しています。私も『Learning Opentelemetry』という書籍の読書感想文のブログを書いたので合わせてぜひ読んでみてください。
OpenTelemetryの概要と重要性
本書は、まずOpenTelemetryプロジェクトの概要を説明しています。OpenTelemetryは、CloudBeesとGoogleが主導するオープンソースプロジェクトで、ベンダーに依存しない一貫した方法でテレメトリデータを収集するための単一の標準を作ることを目的としています。
OpenTelemetryの主な目標は、アプリケーションの計装を簡素化し、ベンダーロックインを回避することです。 開発者は、OpenTelemetryのSDKとAPIを使って一度アプリケーションを計装するだけで、バックエンドのテレメトリシステムを柔軟に変更できます。これは、特定のベンダーのライブラリを使う場合と対照的です。
また、OpenTelemetryは、分散トレーシング、メトリクス、ロギングの3つの主要なテレメトリ信号をサポートしています。これにより、エンドツーエンドの可観測性を実現し、アプリケーションの動作を包括的に理解することができます。
本書は、OpenTelemetryを使う主な理由として、次の3つを挙げています。
- ベンダーロックインの回避
- テレメトリデータ収集の標準化
- 複数のテレメトリ信号のサポート
OpenTelemetryの主要コンポーネント
次に、著者はOpenTelemetryの主要コンポーネントについて説明しています。OpenTelemetryは、以下の3つの主要コンポーネントで構成されています。
- OpenTelemetry API:計装コードを書くためのプログラミング言語固有のインターフェイス。
- OpenTelemetry SDK:APIの実装を提供し、テレメトリデータの収集、処理、エクスポートを行う。
- OpenTelemetry Collector:複数のソースからテレメトリデータを受信し、処理し、様々なバックエンドシステムにエクスポートするためのスタンドアロンサービス。
OpenTelemetry APIは、ベンダーに依存しない一貫した方法でテレメトリデータを生成するためのプログラミング言語固有のインターフェイスを提供します。これにより、開発者は計装コードを一度書くだけで、バックエンドのテレメトリシステムを変更する際に、そのコードを変更する必要がなくなります。
OpenTelemetry SDKは、APIの具体的な実装を提供し、OpenTelemetry Collectorなどのエクスポートサービスにデータを送信します。SDKは、サンプリング、フィルタリング、エンリッチメントなどの機能も提供します。
OpenTelemetry Collectorは、複数のソースからテレメトリデータを収集し、それを処理して、様々なバックエンドシステムにエクスポートするためのスタンドアロンサービスです。Collectorは、OpenTelemetryの中心的なコンポーネントであり、データの収集、処理、エクスポートを分離することで、システムの柔軟性と拡張性を高めています。
OpenTelemetryを使った計装の例
本書は、OpenTelemetryを使ってGoアプリケーションを計装する具体的な例を示しています。
まず、OpenTelemetry APIとSDKをインポートし、トレーサープロバイダを初期化します。次に、スパンを作成し、そこにアプリケーション固有の情報を追加していきます。スパンの作成と管理は、OpenTelemetry APIが提供するTracerオブジェクトを通して行います。
コードの例では、HTTPハンドラ内でスパンを作成し、リクエストの属性をスパンに追加しています。また、別の関数を呼び出す際には、contextパッケージを使ってスパンのコンテキストを伝播させています。
func handler(w http.ResponseWriter, r *http.Request) { // リクエストからコンテキストを取得 ctx := r.Context() // 新しいスパンを開始 ctx, span := tracer.Start(ctx, "hello") defer span.End() // リクエストの属性をスパンに追加 span.SetAttributes( semconv.HTTPMethodKey.String(r.Method), semconv.HTTPTargetKey.String(r.URL.Path), ) // 別の関数を呼び出す際に、スパンのコンテキストを渡す helloHandler(ctx) }
この例では、OpenTelemetryが提供するセマンティック規則に従って、HTTPリクエストの属性をスパンに追加しています。これにより、システム間で一貫性のあるテレメトリデータを収集することができます。
本書は、OpenTelemetryが提供する自動計装の機能についても触れています。自動計装機能を使えば、アプリケーションコードを変更することなく、一般的なライブラリやフレームワークからテレメトリデータを収集することができます。 これにより、計装の手間を大幅に減らすことができます。再三の紹介ではあるがCloud Observability in Actionを読んでいただければ嬉しいです。
テレメトリデータの可視化
最後に、著者は収集したテレメトリデータを可視化する方法について説明しています。
OpenTelemetryは、様々なバックエンドシステムにデータをエクスポートすることができます。本書は、Jaegarを使ってトレースデータを可視化する例を示しています。JaegarはOpenTelemetryに対応したオープンソースのトレーシングバックエンドで、トレース データを収集、保存、可視化するための機能を提供しています。
Jaegarの Web UIを使えば、収集したトレースデータをさまざまな角度から探索することができます。例えば、特定のスパンを選択して、その詳細情報を表示したり、関連するスパンをハイライトしたりすることができます。また、トレースのパフォーマンスを分析するためのツールも提供されています。
本書は、OpenTelemetryとJaegarを組み合わせることで、アプリケーションの動作を詳細に理解し、パフォーマンスのボトルネックを特定できると述べています。
OpenTelemetryの重要性と今後の展望
本章の結論として、OpenTelemetryがアプリケーションの計装において重要な役割を果たすと強調しています。
OpenTelemetryは、ベンダーロックインを回避し、テレメトリデータ収集を標準化するためのオープンソースのインストルメンテーションフレームワークです。 それは、分散トレーシング、メトリクス、ロギングという3つの主要なテレメトリ信号をサポートし、エンドツーエンドの可観測性を実現します。
OpenTelemetryの主要コンポーネントであるAPI、SDK、Collectorは、テレメトリデータの生成、収集、処理、エクスポートを柔軟かつ拡張可能な方法で行うための基盤を提供します。特に、Collectorは OpenTelemetryアーキテクチャの中心的な存在であり、様々なデータソースからのテレメトリデータを統合し、複数のバックエンドシステムにエクスポートすることを可能にします。
本書は、OpenTelemetryを使った計装の具体的な例を示し、それがいかにアプリケーションの動作を理解するのに役立つかを説明しました。OpenTelemetryのAPIとSDKを使えば、アプリケーションに一貫した方法で計装を行うことができ、バックエンドのテレメトリシステムを柔軟に変更することができます。また、自動計装機能を使えば、アプリケーションコードに変更を加えることなく、一般的なライブラリやフレームワークからテレメトリデータを収集することができます。
収集したテレメトリデータは、Jaegarなどのバックエンドシステムを使って可視化し、分析することができます。これにより、アプリケーションのパフォーマンスを詳細に理解し、ボトルネックを特定することができます。
OpenTelemetryは、現代のクラウドネイティブアプリケーションにとって不可欠のツールになりつつあります。 それは、複雑で動的なマイクロサービスアーキテクチャを観測し、トラブルシューティングするためのデファクトスタンダードになる可能性を秘めています。OpenTelemetryの採用が進むことで、アプリケーションの可観測性が向上し、より信頼性の高いシステムを構築することができるでしょう。しかし、まだまだ自分で超えなきゃいけない山もいくつかあるのかぁって思っています。
Chapter 8. Analyzing Events to Achieve Observability
「Chapter 8. Analyzing Events to Achieve Observability」は、オブザーバビリティを実現するためのイベント分析の方法と、従来のデバッグ手法との違いについて詳しく解説した章です。本書は、第一原理に基づいて客観的にシステムを理解することの重要性を強調し、コア分析ループを使ってイベントデータを効果的に分析する方法を提示しています。
既知の条件からのデバッグ
本書は、オブザーバビリティが登場する以前のデバッグ手法の特徴として、システムに関する知識に基づいて問題を特定していたことを指摘しています。熟練したエンジニアは、長年の経験で培った直感を頼りに、どこを見れば問題が見つかるかを知っています。しかし、これはシステムに対する深い理解があってこそ可能な手法であり、新しいメンバーがチームに加わったり、システムが大規模化・複雑化したりすると、すぐに限界に達してしまいます。
インフラエンジニアとして、私自身もこのような状況を数多く経験してきました。新しいサービスのリリースや、システムの大規模な変更の際には、必ず予期せぬ問題が発生するものです。そのたびに、ログやメトリクスを頼りに、問題の原因を探り当てようと奮闘したことを思い出します。
特に、マイクロサービスアーキテクチャの普及に伴い、システムの複雑性が飛躍的に高まった昨今では、単純なログの監視やダッシュボードの確認だけでは、問題の全容を掴むことが難しくなってきています。サービス間の依存関係が複雑に絡み合い、一つの障害が連鎖的に他のサービスに影響を及ぼすことも珍しくありません。
著者も指摘しているように、ランブックの作成やダッシュボードのカスタマイズに多くの時間を費やすことは、もはや効率的とは言えません。モダンなシステムでは、同じ障害が二度と発生しないことが多いため、これらの努力は無駄になってしまうのです。 むしろ、そうした手作業の時間を、より本質的な問題の解決に充てるべきでしょう。
第一原理に基づくデバッグ
本書は、オブザーバビリティを実現するためには、イベントとして収集したテレメトリデータを第一原理に基づいて分析することが重要だと述べています。第一原理とは、他の仮定から演繹されていない基本的な仮定のことを指します。
第一原理に基づいてデバッグするということは、システムを科学的に理解するための方法論に従うということです。 それは、何も仮定せず、何が確かに正しいのかを問い直すことから始まります。そして、その原理に基づいて仮説を立て、システムに関する観察によってその仮説を検証していくのです。
これは、インフラエンジニアにとって非常に重要な考え方だと思います。私たちは、日々、複雑で予測不可能なシステムと向き合っています。その中で問題を解決するためには、因習や思い込みにとらわれることなく、常に原理原則に立ち返って考える姿勢が求められます。
本書は、第一原理に基づくデバッグがオブザーバビリティの中核的な機能であると強調しています。システムの複雑さが増すにつれ、経験や直感に頼ったデバッグは非現実的になります。第一原理に基づくデバッグは、システムに精通していなくても問題を特定できる、体系的で再現性のある方法なのです。
これは、チームの属人性を減らし、誰もが同じ品質でデバッグできるようにするためにも重要です。ベテランエンジニアの「勘」に頼るのではなく、誰もが同じプロセスを踏めば同じ結果が得られるようにしておくことが、チームの生産性と品質の向上につながります。
コア分析ループの活用
本書は、第一原理に基づくデバッグの具体的な方法として、コア分析ループを紹介しています。コア分析ループは、テレメトリデータから仮説を立て、データによってその仮説を検証するプロセスを繰り返すことで、複雑な問題の答えを体系的に導き出す方法です。

コア分析ループは以下の4つのステップで構成されています。
- 調査のきっかけとなった全体像から始める。
- これまでに分かっていることが正しいかを検証する。
- パフォーマンスの変化を引き起こしている可能性のあるディメンションを探す。
- 何が起こっているのかを十分に理解できたかを判断し、できていなければ、次の出発点として現在のビューを絞り込み、ステップ3に戻る。
これは、第一原理に基づくデバッグの基本であり、インフラエンジニアにとっても非常に有用な手法だと思います。利用可能なすべてのディメンションを繰り返し調べることで、システムに関する事前の知識がなくても、問題の原因となっているディメンションを特定することができます。
実際、私自身もこの手法を用いて、複雑な障害の原因を突き止めたことがあります。あるとき、あるマイクロサービスのレスポンスタイムが突然悪化し、原因が全くわからないという事態に陥りました。そこで、コア分析ループを使って、関連するすべてのメトリクスを洗い出し、一つ一つ仮説を立てて検証していきました。
結果として、原因はデータベースへの接続数の上限に達していたことだとわかりました。その問題自体は設定変更で簡単に解決できたのですが、重要なのは、事前にその可能性を予測していなかったにもかかわらず、コア分析ループを使って問題を特定できたことです。
ただし、著者も指摘するように、この作業を人間だけで行うのは非常に時間がかかります。システムが大規模で複雑になればなるほど、調べるべきディメンションの数は膨大になります。オブザーバビリティツールは、このブルートフォース分析をできる限り自動化する必要があるのです。
コア分析ループのブルートフォース部分の自動化
コア分析ループは、大量のシステムノイズの中から重要なシグナルを客観的に見つけ出すための方法です。この作業を迅速に行うためには、マシンの計算能力を活用することが不可欠です。
本書は、Honeycombの BubbleUp機能を例に、コア分析ループの自動化について説明しています。BubbleUpは、注目すべきパフォーマンスの領域を選択すると、その領域内外のすべてのディメンションの値を計算し、差分の割合で並べ替えて表示します。これにより、どのディメンションがパフォーマンスの異常に関与しているかが一目でわかるようになっています。ちなみに他の監視基盤でも同様にできるはずです。
こうした自動化は、インフラエンジニアやSREの負担を大幅に軽減してくれます。私たちは、データの中から重要なパターンを見つけ出すことに集中でき、膨大な生データを手作業で処理する必要がなくなるのです。
また、著者が指摘するように、この自動化には、オブザーバビリティの基本的な構成要素である、任意の幅を持つ構造化イベントが不可欠です。従来のメトリクスやログでは、データの粒度が粗すぎたり、コンテキストが不足していたりするため、自由自在な分析ができないのです。
私自身、以前はメトリクスベースの監視ツールを使っていましたが、ある問題をきっかけにオブザーバビリティツールの導入を決めました。それは、あるマイクロサービスの障害が、別のサービスに連鎖的に影響を及ぼすという事案でした。メトリクスだけでは、どのサービスが原因で、どの順序で障害が伝播したのかを追跡することができませんでした。
そこで、OpenTelemetryを使って各サービスをインストルメント化し、Jaegerでトレースデータを収集・可視化する環境を構築しました。すると、サービス間の呼び出し関係が一目瞭然になり、障害の原因を瞬時に特定できるようになったのです。まさに、オブザーバビリティの威力を実感した瞬間でした。
AIOpsの誤ったアレ
本書は、AIOps(運用のための人工知能)の過度な期待について警鐘を鳴らしています。AIOpsは、異常検知やアラートノイズの削減などの分野でオブザーバビリティと交差しますが、万能な解決策ではありません。
AIによる異常検知は、「正常」なベースラインイベントと「異常」なイベントを比較するという概念に基づいています。しかし、頻繁にシステムの動作が変化するような環境では、AIが正しいベースラインを選択するのは非常に難しいのです。AIは、完全に正常な動作を異常と見なしたり、異常を正常と誤認したりする可能性があります。
これは、インフラエンジニアとして痛感している問題です。私たちは、常に変化し続けるシステムを扱っています。新機能のリリースや設定変更など、日々のオペレーションが常に「異常」を生み出しているのです。そのような環境で、AIだけに頼って異常を検知することは現実的ではありません。
むしろ、著者が述べているように、人間の知性とコンテキストの理解が不可欠だと思います。コンピューターにはデータを大量に処理して興味深いパターンを見つけ出すことを任せ、そのパターンが本当に問題を示しているのかを判断するのは人間の役割なのです。 これこそが、オブザーバビリティとコア分析ループの自動化において、人間とマシンの知性を融合させる最良の方法だと私も考えます。
実際、私たちのチームでも、オブザーバビリティツールが検出した異常を、エンジニアが一つ一つ確認するプロセスを設けています。既存のAIと呼ばれる機構だけでなく、生成AIモデルによる分析結果も同様に、人間による検証が欠かせません。某かが問題と判断した事象の多くは、実は仕様変更や一時的なスパイクだったりするのです。そうした「偽陽性」を排除し、本当に対処が必要な問題にフォーカスするには、人間の判断が欠かせません。
オブザーバビリティ実現のためのイベント分析
本章の結論として、適切なテレメトリデータを収集することは、オブザーバビリティへの第一歩に過ぎないと強調しています。
そのデータを第一原理に基づいて分析することで、複雑な環境におけるアプリケーションの問題を客観的かつ正確に特定することができるのです。 コア分析ループは、障害箇所を迅速に特定するための効果的な手法ですが、システムが複雑になるほど、人間が系統的に分析するのは時間がかかります。
そこで、異常の原因を探る際には、非常に大きなデータセットから興味深いパターンを迅速に見つけ出すために、計算リソースを活用することができます。そのパターンを人間のオペレーターに提示し、必要なコンテキストに置いて調査の方向性を further示してもらうことで、マシンと人間の強みを最大限に活用し、システムのデバッグを迅速に進められるのです。
オブザーバビリティシステムは、前章で学んだイベントデータに対してこの種の分析パターンを適用するように構築されています。 適切なデータと、そのデータを分析して迅速に答えを得るための手法の両方を理解することで、オブザーバビリティの真価を発揮することができるのです。
インフラエンジニアとして、私はこの章で紹介されたコンセプトの多くを実践してきました。コア分析ループは、複雑な障害の原因を突き止めるための強力な武器であり、オブザーバビリティツールの自動化機能と組み合わせることで、その威力はさらに増します。
また、人間とマシンの知性を適切に組み合わせることの重要性も、身をもって体験しています。AIには膨大なデータを高速に処理する能力がありますが、そこから意味のある洞察を引き出すには、人間の専門知識と判断力が必要不可欠なのです。
私たちインフラエンジニアやSREは、システムの安定運用という重大な責務を負っています。そのためには、単に技術的なスキルだけでなく、システムを俯瞰的に捉え、本質的な問題を見抜く力が求められます。オブザーバビリティは、そのための強力な武器になると確信しています。
本章で紹介された手法を実践することで、私たちは、システムの動作を深く理解し、問題の予兆を早期に検知し、障害の影響を最小限に抑えることができるようになるでしょう。それは、ユーザーに価値を届け続けるために、そして自らの成長のためにも、私たちに課せられた使命だと思うのです。
Chapter 9. How Observability and Monitoring Come Together
「Chapter 9. How Observability and Monitoring Come Together」は、オブザーバビリティとモニタリングの違いを明確にし、それぞれの適切な適用範囲と、両者が補完的に機能する方法について解説した章です。本書は、組織のニーズに応じて、オブザーバビリティとモニタリングを適切に組み合わせることの重要性を強調しています。
モニタリングの適用範囲
本書は、まずモニタリングの適用範囲について詳細に説明しています。モニタリングは、システムの状態を理解するための成熟した手法であり、何十年にもわたって洗練されてきました。当初の単純なメトリクスとRRD(Round-Robin Database)から、TSDB(Time Series Database)と精巧なタグ付けシステムへと進化を遂げてきたのです。
モニタリングのベストプラクティスは広く知られており、特定のツールに特化したコミュニティを超えて理解されています。例えば、「人間がグラフを1日中見ている必要はなく、何か問題があればシステムが自動的に通知すべき」というのは、モニタリングの中核をなす広く受け入れられている考え方です。
この意味で、モニタリングシステムは本質的にリアクティブです。既知の障害状態に反応して、人間に問題の発生を警告するのです。つまり、モニタリングは、既知の未知(known-unknowns)を検出するように最適化されているのです。
この特性から、モニタリングは、アプリケーションコードよりも変更頻度が低く、予測可能なシステムの状態を理解するのに最適だと言えます。本書は、ここでいうシステムとは、ソフトウェアを実行するために必要な基盤、つまりインフラストラクチャやランタイムを指していると説明しています。
オブザーバビリティの適用範囲
一方、オブザーバビリティは、より能動的なアプローチを取ります。本書は、オブザーバビリティの実践では、エンジニアは常に本番環境のコードを監視し、異常や興味深い兆候を探るべきだと述べています。
第8章で説明されているように、コア分析ループは、第一原理に基づくデバッグを可能にし、未知の未知(unknown-unknowns)を発見するように設計されています。つまり、オブザーバビリティは、システムよりも頻繁に、そしてより予測不可能な方法で変化する、開発中のソフトウェアの状態を理解するのに最適化されているのです。
モニタリングとオブザーバビリティのツールには、異なるベストプラクティスと実装があり、異なる目的に役立ちます。
システムとソフトウェアの違い
本書は、システムとソフトウェアの違いについても詳しく説明しています。より伝統的な環境では、システムとソフトウェアの区別は明確でした。ベアメタルのインフラストラクチャがシステムであり、その上で動作するすべてがソフトウェアでした。しかし、モダンなシステムとその多くの高次の抽象化により、その区別はやや不明確になっています。
ここでの定義に従えば、ソフトウェアとは、顧客に価値を提供する本番サービスを運用するために、アクティブに開発されているコードのことです。ソフトウェアは、ビジネスが市場の問題を解決するために実行したいものです。
一方、システムとは、そのサービスを運用するために必要な、基盤となるインフラストラクチャとランタイムに関するすべてを包括する用語です。システムは、ビジネスがソフトウェアを実行するために必要なものです。この定義では、データベース(MySQLやMongoDBなど)、コンピュートとストレージ(コンテナや仮想マシンなど)、その他、ソフトウェアをデプロイして実行する前にプロビジョニングして設定する必要があるすべてのものが、システム(またはインフラストラクチャ)に含まれます。
クラウドコンピューティングの世界では、これらの定義を明確にするのがやや難しくなっています。例えば、ソフトウェアを実行するために、Apache Kafkaのような基盤コンポーネントが必要だとします。もしそれらのコンポーネントへのアクセスをサービスとして購入するのであれば、それはインフラストラクチャとはみなされません。本質的に、他の誰かにそれを運用してもらうためにお金を払っているのです。しかし、自分たちでインストール、設定、時々のアップグレード、パフォーマンスのトラブルシューティングを行う必要があるのであれば、それは気にかける必要のあるインフラストラクチャなのです。
ソフトウェアに比べて、システム層のすべては、変更頻度が低く、異なるユーザーセットに焦点を当て、異なる価値を提供するコモディティです。ソフトウェア、つまり顧客が使用するために書かれたコードは、ビジネスの中核を差別化するものです。それは、今日の企業が存在する理由そのものです。したがって、ソフトウェアには、管理方法に関する異なる考慮事項があります。
以下は、システムとソフトウェアの間で異なる要因を比較しています。
- 変更の頻度:システムではパッケージの更新が月単位であるのに対し、ソフトウェアではリポジトリへのコミットが日単位で行われます。
- 予測可能性:システムは高い(安定している)のに対し、ソフトウェアは低い(多くの新機能がある)。
- ビジネスへの価値:システムは低い(コストセンター)のに対し、ソフトウェアは高い(収益の源泉)。
- ユーザー数:システムは少ない(内部チーム)のに対し、ソフトウェアは多い(顧客)。
- 中核となる関心事:システムではシステムやサービスが健全かどうかであるのに対し、ソフトウェアでは各リクエストが適時かつ確実にエンドツーエンドの実行に必要なリソースを獲得できるかどうか。
- 評価の視点:システムではシステム自体であるのに対し、ソフトウェアでは顧客。
- 評価基準:システムでは低レベルのカーネルとハードウェアデバイスドライバであるのに対し、ソフトウェアでは変数とAPIエンドポイント。
- 機能的責任:システムではインフラストラクチャの運用であるのに対し、ソフトウェアではソフトウェアの開発。
- 理解の方法:システムではモニタリングであるのに対し、ソフトウェアではオブザーバビリティ。
インフラストラクチャに関しては、管理チームの視点のみが重要です。インフラストラクチャについて問うべき重要な質問は、それが提供するサービスが本質的に健全かどうかということです。そうでない場合、そのチームは迅速に行動を起こし、インフラストラクチャを健全な状態に戻す必要があります。
インフラストラクチャの健全性に影響を与える条件は、変化が少なく、比較的予測が容易です。実際、これらの問題を予測し(例:キャパシティプランニング)、自動的に修復する(例:オートスケーリング)ためのプラクティスはよく確立されています。その比較的予測可能でゆっくりと変化する性質のため、集約されたメトリクスは、システムレベルの問題の監視とアラートには完全に適しているのです。
一方、アプリケーションコードでは、最も重要なのは顧客の視点です。基盤となるシステムは本質的に健全かもしれませんが、ユーザーリクエストはさまざまな理由で失敗する可能性があります。先行する章で説明したように、分散システムはこの種の問題の検出と理解を難しくしています。突然、高カーディナリティのフィールド(ユーザーID、ショッピングカートIDなど)を使って、特定の顧客の体験を観察する能力が重要になってきます。特に、継続的デリバリーのモダンな世界では、新しいバージョンのコードが常にデプロイされているため、ソフトウェアの関心事は常にシフトし、変化しています。オブザーバビリティは、これらの関心事に対処するための適切な質問をリアルタイムで行う方法を提供します。
これら2つのアプローチは相互に排他的ではありません。すべての組織には、どちらかのカテゴリに当てはまる考慮事項があるでしょう。次に、組織のニーズに応じて、この2つのアプローチが共存する方法を見ていきます。
組織のニーズの評価
本書は、オブザーバビリティとモニタリングの適切なバランスを見出すには、組織のニーズを評価することが重要だと述べています。
モニタリングは、システムレベルの関心事を理解するのに最適です。オブザーバビリティは、アプリケーションレベルの関心事を理解するのに最適です。どの関心事がビジネスにとって最も重要かを理解することが、組織自身のニーズを評価することなのです。
オブザーバビリティは、自社で開発・出荷するソフトウェアが、顧客にサービスを提供する際にどのように機能しているかを深く理解するのに役立ちます。全体的に許容できるパフォーマンスを提供することに加えて、特定の注目すべき顧客セグメントに優れたサービスを提供することがビジネス戦略の中核である場合、オブザーバビリティの必要性は特に強調されます。
一方、モニタリングは、そのソフトウェアをサポートするために運用しているシステムが、どの程度その役割を果たしているかを理解するのに役立ちます。メトリクスベースのモニタリングツールとそれに関連するアラートは、基盤となるシステムの容量限界や既知のエラー状態に達したことを知らせてくれます。
IaaSプロバイダーのように、インフラストラクチャ自体を顧客に提供することがビジネスの中核である場合、DNSカウンター、ディスク統計など、相当量のモニタリングが必要になります。基盤となるシステムは、このような組織にとってビジネス上重要であり、顧客に公開するこれらの低レベルのシステムに精通している必要があるのです。
しかし、インフラストラクチャの提供がビジネスの中核的な差別化要因ではない場合、モニタリングの重要性は相対的に低くなります。その場合、高レベルのサービスとエンドツーエンドのチェックのみを監視する必要があるかもしれません。ビジネスに必要なモニタリングの量を正確に判断するには、いくつかの考慮事項があります。
自社のインフラストラクチャの大部分を運用している企業は、より多くのモニタリングを必要とします。オンプレミスでシステムを運用するか、クラウドプロバイダーを使用するかに関わらず、この考慮事項は、インフラストラクチャがどこにあるかというよりも、運用上の責任に関するものです。クラウドで仮想マシンをプロビジョニングするにしろ、オンプレミスでデータベースを管理するにしろ、重要な要因は、インフラストラクチャの可用性とパフォーマンスを保証する責任を自社のチームが負うかどうかなのです。
ベアメタルシステムの運用責任を負う組織は、低レベルのハードウェアパフォーマンスを調べるモニタリングを必要とします。イーサネットポートのカウンター、ハードドライブのパフォーマンス統計、システムファームウェアのバージョンなどを監視する必要があります。ハードウェアレベルの運用をIaaSプロバイダーにアウトソースしている組織は、そのレベルで機能するメトリクスと集計を必要としないでしょう。
そして、これはスタックのさらに上のレベルでも同様です。運用責任がサードパーティに移行されるにつれ、インフラストラクチャの監視の関心事も移行されていきます。
ほとんどのインフラストラクチャを高レベルのPaaS(Platform-as-a-Service)プロバイダーにアウトソースしている企業は、従来のモニタリングソリューションをほとんど、あるいはまったく必要としないかもしれません。Heroku、AWS Lambdaなどは、本質的に、ビジネスが実行したいソフトウェアをサポートするために必要なインフラストラクチャの可用性とパフォーマンスを保証する仕事を請け負うために、料金を支払うことを可能にしているのです。
今日、ユーザーのマイレージは、クラウドプロバイダーの堅牢性によって異なるかもしれません。おそらく、抽象化は十分にクリーンで高レベルなので、インフラストラクチャの監視への依存を取り除くという経験は、それほどフラストレーションを感じるものではないでしょう。しかし、理論的には、すべてのプロバイダーがそのシフトを可能にするモデルに移行しつつあります。
例外として無視できないインフラストラクチャの監視
システムのモニタリングとソフトウェアのオブザーバビリティのこの明確な区分には、いくつかの例外があります。先に述べたように、ソフトウェアのパフォーマンスを評価するための視点は、顧客体験です。ソフトウェアのパフォーマンスが遅い場合、顧客はそれを悪い体験と捉えます。したがって、顧客体験を評価する上での主要な関心事は、パフォーマンスのボトルネックを引き起こす可能性のあるものを理解することです。この明確な区分の例外は、ソフトウェアがその基盤となるインフラストラクチャとどのように相互作用しているかを直接示すメトリクスです。
ソフトウェアの観点からは、一般的なモニタリングツールによって/procファイルシステムで発見された変数の何千ものグラフを見ることはほとんど、あるいはまったく価値がありません。電源管理やカーネルドライバに関するメトリクスは、低レベルのインフラストラクチャの詳細を理解するのに役立つかもしれませんが、ソフトウェアのパフォーマンスへの影響についてはほとんど有用な情報を示さないため、ソフトウェア開発者は日常的に無視します(そうあるべきです)。
しかし、CPU使用率、メモリ消費量、ディスクアクティビティなどの高次のインフラストラクチャメトリクスは、物理的なパフォーマンスの制限を示します。ソフトウェアエンジニアとして、これらの指標を注意深く観察する必要があります。なぜなら、これらはコードによってトリガーされる問題の早期警戒シグナルになる可能性があるからです。例えば、新しいデプロイによって、数分以内にレジデントメモリの使用量が3倍になったことを知りたいはずです。新機能の導入直後にCPU消費量が2倍になったり、ディスク書き込みアクティビティが急増したりするのを見ることで、問題のあるコードの変更にすぐに気づくことができます。
高次のインフラストラクチャメトリクスは、基盤となるインフラストラクチャがどの程度抽象化されているかによって、利用できる場合とできない場合があります。しかし、利用できる場合は、オブザーバビリティへのアプローチの一部としてそれらをキャプチャすることを強くお勧めします。
ここでのモニタリングとオブザーバビリティの関係は、相関関係になります。パフォーマンスの問題が発生した場合、モニタリングを使用してシステムレベルの問題を素早く除外または確認することができます。したがって、システムレベルのメトリクスデータをアプリケーションレベルのオブザーバビリティデータと並べて表示することは有益です。一部のオブザーバビリティツール(HoneycombやLightstepなど)は、そのデータを共有のコンテキストで提示しますが、他のツールでは、その相関関係を確認するために別のツールやビューを使用する必要があるかもしれません。
実際の適用例
本書は、モニタリングとオブザーバビリティの共存パターンのいくつかの実例を紹介しています。
ある企業では、オブザーバビリティへの移行により、Prometheus、Jaeger、従来のAPMツールの3つのシステムを、モニタリングシステムとオブザーバビリティシステムの2つに集約することができました。ソフトウェアエンジニアリングチームは主にオブザーバビリティを使用し、中央の運用チームはPrometheusを使ってインフラを監視しています。ソフトウェアエンジニアは、コードのリソース使用量の影響について質問がある場合、Prometheusを参照することができます。しかし、この必要性は頻繁ではなく、アプリケーションのボトルネックのトラブルシューティングにPrometheusを使用する必要はほとんどないと報告しています。
別の企業は、比較的新しい会社で、グリーンフィールドのアプリケーションスタックを構築することができました。彼らのプロダクションサービスは、サーバーレス機能とSaaSプラットフォームを主に利用しており、独自のインフラはほとんど運用していません。最初から本当のインフラを持っていなかったため、モニタリングソリューションを自分の環境に適合させようとする道を歩み始めることはありませんでした。彼らは、アプリケーションのインストルメンテーションとオブザーバビリティに依存して、本番環境でのソフトウェアを理解しデバッグしています。また、そのデータの一部を長期的な集計とウェアハウジングのためにエクスポートしています。
最後の例は、デジタルトランスフォーメーションを進める成熟した金融サービス企業です。彼らは、レガシーインフラとグリーンフィールドアプリケーションが混在する、大規模な異種混合環境を持っています。多くの古いアプリケーションはまだ運用されていますが、それらを最初に構築し、維持していたチームは、とっくに解散するか、会社の他の部署に再編成されています。多くのアプリケーションは、メトリクスベースのモニタリングとダッシュボード機能(オールインワンの商用ベンダーが提供)の組み合わせ、および非構造化ログを検索するためのさまざまなロギングツールを使って管理されています。
安定して機能しているサービスのモニタリングアプローチを取り除き、再設計し、置き換えることで、ビジネスにはほとんど、あるいはまったく価値がもたらされないでしょう。その代わりに、グリーンフィールドアプリケーションは、モニタリング、ダッシュボード、ロギングの組み合わせを必要とする以前のアプローチではなく、オブザーバビリティのために開発されています。新しいアプリケーションが企業のインフラストラクチャを使用する場合、ソフトウェアエンジニアリングチームは、リソースの使用状況の影響を監視するためのインフラストラクチャメトリクスにもアクセスできます。しかし、一部のソフトウェアエンジニアリングチームは、リソース使用量とアプリケーションの問題を関連付けるために別のシステムを使用する必要性を減らすために、インフラストラクチャメトリクスをイベントにキャプチャし始めています。
組織の責任に基づくオブザーバビリティとモニタリングのバランス
本章の結論として、オブザーバビリティとモニタリングの共存バランスは、組織内で採用されているソフトウェアとインフラストラクチャの責任に基づいて決定されるべきだと強調しています。
モニタリングは、システムの健全性を評価するのに最適であり、オブザーバビリティは、ソフトウェアの健全性を評価するのに最適です。 各ソリューションの必要性は、基盤となるインフラストラクチャの管理をどの程度サードパーティプロバイダーにアウトソースしているかによって異なります。
ただし、CPU、メモリ、ディスクなど、ソフトウェアのパフォーマンスに直接影響を与える高次のインフラストラクチャメトリクスは例外です。これらのメトリクスは、オブザーバビリティアプローチの一部として取り込むべきです。
本章では、モニタリングとオブザーバビリティを補完的に活用するいくつかの一般的なアプローチを示しました。 これらの考慮事項は、異なるチームによってどのように実装されているかを示す実世界の例だと言えます。
オブザーバビリティの基礎を深く理解したところで、次のパートでは、オブザーバビリティの実践を成功裏に採用し、チーム全体でその採用を推進するために必要な文化的変化についても探ります。
私自身、SREとしてモニタリングとオブザーバビリティの両方を活用した経験があります。従来のモニタリングツールは、インフラストラクチャの健全性を確保するために欠かせませんが、アプリケーションレベルの問題を理解し、デバッグするには不十分でした。オブザーバビリティの導入により、コードの動作を深く理解し、問題の根本原因をより迅速に特定できるようになりました。
特に、CPUやメモリの使用率など、インフラメトリクスとアプリケーションの問題を関連付けることの重要性は、自身の経験からも強く実感しています。これらのメトリクスをオブザーバビリティイベントに取り込むことで、問題の全容をより素早く把握することができるようになりました。
皆さんは、ご自身の組織において、オブザーバビリティとモニタリングをどのように組み合わせていますか?また、両者のバランスを取る上で、どのような課題に直面していますか?ぜひ、経験を共有しましょう。
Part III. Observability for Teams
本書の第3部では、異なるチーム間で観測可能性の採用を促進するのに役立つ、社会的・文化的慣行の変化についてを詳しく説明してくれています。
Chapter 10. Applying Observability Practices in Your Team
「Chapter 10. Applying Observability Practices in Your Team」は、オブザーバビリティの実践を自分のチームで始めるにあたって役立つヒントを提供する章です。万能のレシピは存在しないことを前提としつつ、これまでの経験から得られた有用なパターンやアプローチが複数紹介されています。具体的には、チームやプロジェクトの現状を正しく把握し、オブザーバビリティ導入の必要性と期待される効果を明確化することから始め、実装に向けては小さなスコープから着手し、限られた領域に集中して成功事例を積み重ねながら徐々に範囲を広げていくアプローチが提案されています。また、この章ではオブザーバビリティ実践の障壁となる潜在的な課題とその対処方法についても言及され、技術的な側面に加え、組織文化の変革や関係者間のコミュニケーション、教育の重要性が強調されています。読み進めるうちに、オブザーバビリティの導入は単なるツールの導入以上の作業であり、チーム全体で取り組む価値があるプロセスであることが明らかになり、この章を読めば、自分のチームに最適なオブザーバビリティ実践の方法を見出すための手がかりが得られます。この辺からというかPart III以降では一度目とは違う読書体験となり、オブザーバビリティ実践の奥深さを実感することができました。
コミュニティグループへの参加
本書は、オブザーバビリティの実践を始めるにあたって、コミュニティグループに参加することを勧めています。オブザーバビリティは新しい分野であり、同じような課題に取り組む人々とつながることで、多くを学び、自らの実践を改善することができます。
Slackグループなどのコミュニティに参加することで、様々なバックグラウンドを持つ人々と出会い、他のチームがどのように課題に取り組んでいるかを知ることができます。こうした共有された経験は、自分自身の実験を始める前に、解決策やアプローチの背景を理解するのに役立ちます。
また、コミュニティへの参加は、自分が見落としていた進展に気づくきっかけにもなります。オブザーバビリティツールのプロバイダーは、ユーザーの課題を理解し、フィードバックを得るために、様々なコミュニティに参加しています。日本にも独自のコミュニティグループがあるのですがベンダーもしくはツール毎のイベント以外は単発系が多い気がしているのでその都度調べてください。
Observability Conference 2022 by CloudNative Days とOpenTelemetry の会は良い発表も多いので紹介しておきます。
最も大きな痛みのポイントから始める
新しい技術の導入は、小さくて目立たないサービスから始めるのが一般的ですが、本書は、オブザーバビリティの場合、これが大きな間違いだと指摘しています。オブザーバビリティツールは、捉えどころのない問題をすばやく見つけるのに役立ちますが、すでにうまく機能しているサービスから始めては、その価値を証明することはできません。
オブザーバビリティの導入は、難しい問題や捉えどころのない問題を解決することから始めるべきです。 例えば、何週間も人々を悩ませているが、誰も正しい修正方法がわからないようなサービスや、原因不明のデータベースの混雑、正体不明のユーザーによって生成される説明不能な負荷に悩まされているサービスなどが、最適な出発点となります。
こうした難しい問題をすばやく解決することで、反対意見を抱く人々を説得し、追加のサポートを得て、オブザーバビリティの採用をさらに促進することができるのです。しかし、痛みが大きい分期待値も高いので注意が必要。
既存の取り組みを活用する機会を探る
新しい技術を採用する際の最大の障壁の一つが、「埋没コストの誤謬」です。これは、すでに投資した時間、お金、努力のために、その行動や試みを続けてしまうことを指します。
根本的な変化に抵抗するのは、資源の無駄という認識が入り込むからです。 古いソリューションを理解し、そのためにインストルメンテーションを行うのに何年も投資してきたことを考えると、感情的には理解できます。しかし、これではオブザーバビリティの導入が止まってしまいます。
そこで、既存の取り組みをオブザーバビリティのイニシアチブに活用できる機会を常に探し、飛びつくことが重要です。例えば、既存のデータストリームを二次的な宛先に送ったり、別の方法で重要なデータを見たりできるなら、そのデータをオブザーバビリティソリューションに送り込むチャンスです。
既存のツールとの親和性を高めることで、採用へのハードルを下げることができるのです。新しいソリューションの中に現在の世界がどのようにマッピングされるかを人々に理解してもらう必要があります。
最後の難関に備える
本書は、オブザーバビリティの実装における最も難しい部分の一つが、ゴールまで到達することだと指摘しています。
チームの規模やスコープにもよりますが、オンコールアプローチの一環として反復的に新しいインストルメンテーションを展開していくことで、意図するスタックのすべての部分にオブザーバビリティを導入するために必要な作業の半分から3分の2程度は、ほとんどのチームで達成できるでしょう。しかし、スタックの中には、他の部分ほど活発に開発されていない部分があることに気づくはずです。そういった部分については、完了プランが必要不可欠です。
オブザーバビリティの完全な実装の目標は、問題が発生したときにいつでも本番アプリケーションの状態を完全に理解するために使える、信頼できるデバッグソリューションを構築することです。 その状態に到達するまでは、異なる問題の解決に最適な様々なツールがある状態が続くでしょう。実装フェーズでは、それでも許容できるかもしれませんが、長期的には、実装を完了しないと、チームの時間、認知能力、注意力を浪費することになります。
そこで、残りを迅速に処理するためのタイムラインを作成する必要があります。ターゲットマイルストーンは、チームがオブザーバビリティツールを本番でのデバッグの第一選択肢として使えるようにするために必要な残りのインストルメンテーション作業を達成することです。
オブザーバビリティ実践の導入ヒント
本章の結論として、オブザーバビリティの導入方法は、チームの状況に応じて異なると強調しています。
オブザーバビリティの導入を始めるにあたって、同業者のコミュニティに積極的に参加することは非常に価値があります。 導入を始める際は、すでにうまく機能している部分ではなく、最も大きな痛みのポイントを解決することに注力すべきです。
また、導入のプロセス全体を通して、素早く動き、高い価値とROIを示し、反復的に作業に取り組む姿勢を忘れないようにしましょう。 組織のあらゆる部分を巻き込む機会を見つけ、最後の大きなプッシュで導入プロジェクトをゴールまで持っていくことを忘れてはいけません。
本章のヒントは、オブザーバビリティの導入に必要な作業を完了させるのに役立ちます。その作業が完了すれば、オブザーバビリティを日常的に使用することで、新しい働き方を実現できるようになります。
私自身、SREとしてオブザーバビリティの導入に携わった経験から、著者の提言の多くに共感しました。特に、最も大きな痛みのポイントから始めることの重要性は、身をもって実感しています。モニタリングでは捉えきれなかった複雑な問題を、オブザーバビリティを用いて解決できた時の喜びは忘れられません。
また、既存の取り組みを活用することも、チームのオブザーバビリティ採用を促進する上で非常に有効でした。馴染みのあるダッシュボードをオブザーバビリティツールで再現したり、既存のログデータをトレースイベントとして送信したりすることで、エンジニアはオブザーバビリティの価値をより早く実感できるようになりました。
一方で、著者が指摘するように、実装を最後までやり遂げることの難しさも痛感しました。日々の運用に追われる中で、インストルメンテーションを完成させる作業は後回しになりがちです。そこで、私たちは定期的な「オブザーバビリティ・ハッカソン」を開催し、全エンジニアでインストルメンテーションの完成度を高める取り組みを行いました。これにより、オブザーバビリティが私たちのデバッグの第一選択肢になったのです。
Chapter 11. Observability-Driven Development
「Chapter 11. Observability-Driven Development」は、オブザーバビリティの実践をソフトウェア開発のライフサイクルの早い段階から取り入れることの重要性を説いた章です。本書は、テスト駆動開発(TDD)の限界を指摘し、オブザーバビリティ駆動開発がいかにソフトウェアの品質と開発速度の向上に寄与するかを詳細に解説しています。
テスト駆動開発とその限界
本書は、まずTDDの特徴と限界について説明しています。TDDは、ソフトウェアを本番環境にリリースする前にテストするための、業界のゴールドスタンダードです。TDDは、アプリケーションを決定論的な一連の反復可能なテストで定義することで、ソフトウェアの操作性について明確に考える方法を提供します。
しかし、本書は、TDDの一貫性と孤立性が、本番環境でのソフトウェアの振る舞いについての洞察を制限してしまうと指摘しています。 孤立したテストに合格することは、顧客がそのサービスを良好に体験していることを意味するわけではありません。また、本番環境にコードを再リリースする前にエラーや回帰を迅速かつ直接的に特定し、修正できることを意味するわけでもありません。

開発サイクルにおけるオブザーバビリティ
本書は、オブザーバビリティがソフトウェア開発チームのバグ発見能力を高めることで、より良いコードの作成と出荷を可能にすると主張しています。バグを迅速に解決するためには、オリジナルの意図がまだ作者の頭にある間に問題を調査することが重要です。 バグが誤って出荷されてから、そのバグを含むコードが問題ないか調べるまでの時間が長ければ長いほど、多くの人の時間が無駄になってしまいます。
また、本書は、オブザーバビリティとコードのデバッグ場所の特定方法についても説明しています。オブザーバビリティは、コードそのものをデバッグするためのものではなく、デバッグすべきコードを見つけるためのシステム内の場所を特定するためのものです。 オブザーバビリティツールは、問題が発生している可能性のある場所をすばやく絞り込むのに役立ちます。
マイクロサービス時代のデバッグ
マイクロサービスの台頭は、オブザーバビリティの台頭と密接に関連しています。モノリスがマイクロサービスに分解されると、デバッガーはネットワークをまたぐことができなくなるため、うまく機能しなくなります。
マイクロサービスでは、サービスリクエストがネットワークを横断して機能を実現するため、あらゆる種類の運用上、アーキテクチャ上、インフラストラクチャ上の複雑さが、意図せずに出荷したロジックのバグと不可分に絡み合うようになったのです。 オブザーバビリティがなければ、パフォーマンスグラフがすべて同時にスパイクしたりディップしたりしているだけで、問題の本質が見えなくなってしまいます。
インストルメンテーションがオブザーバビリティを促進する仕組み
本書は、オブザーバビリティを実現するための必要条件が、有用なインストルメンテーションの作成であると述べています。優れたインストルメンテーションは、オブザーバビリティを促進します。
具体的には、コードをデプロイしてエラーの結果を感じるまでのループを短くするような、強化メカニズムとフィードバックループを作成することを目標にすべきだと提案しています。例えば、コードをマージした人に、一定期間、本番環境でアラートが発生した場合にそのアラートを送るようにすることです。
エンジニアは、デプロイ後すぐに以下の質問に答えられるように、自分のコードをinstrument化することが求められます。
- コードは期待通りに動作しているか?
- 以前のバージョンと比べてどうか?
- ユーザーは積極的にコードを使用しているか?
- 異常な条件は発生していないか?
オブザーバビリティの左シフト
本書は、オブザーバビリティ駆動開発が、ソフトウェアが本番環境の乱雑な現実の中でどのように機能するかを保証すると述べています。
TDDが孤立した仕様への準拠を保証する一方で、オブザーバビリティ駆動開発は、変動するワークロードを経験し、特定のユーザーが予測不可能なことを行っている、ある時点での複雑なインフラストラクチャ上に分散されたソフトウェアが機能することを保証します。
開発ライフサイクルの早い段階でインストルメンテーションをソフトウェアに組み込むことで、エンジニアは小さな変更が本番環境で実際にどのような影響を与えるかをより容易に考慮し、より迅速に確認できるようになります。
従来のモニタリングアプローチでは、複雑なモダンなソフトウェアシステムで何が起こっているのかを正確に推論する能力がほとんどありません。その結果、チームは本番環境をガラスの城のように扱い、その城を乱すことを恐れるようになってしまうのです。
オブザーバビリティ駆動開発により、エンジニアリングチームはガラスの城を対話型の遊び場に変えることができます。 ソフトウェアエンジニアは、オブザーバビリティを自らの開発プラクティスに取り入れ、本番環境への変更を恐れるサイクルを解きほぐす必要があります。
オブザーバビリティを用いたソフトウェア開発の高速化
本書は、ソフトウェアエンジニアが新機能と一緒にテレメトリを束ねることで、コミットからエンドユーザーへの機能リリースまでの時間を短縮できると述べています。
ソフトウェア業界では、速度と品質の間にはトレードオフがあるという認識が一般的ですが、著書「Accelerate」では、このような逆の関係は神話であることが明らかにされました。エリートパフォーマーにとって、速度と品質は連動して向上し、互いに強化し合うのです。
エンジニアリングチームの健全性と有効性を示す重要な指標は、コードが書かれてから本番環境に導入されるまでの経過時間で捉えられます。 すべてのチームがこの指標を追跡し、改善に努めるべきです。
オブザーバビリティ駆動開発は、機能フラグと段階的デリバリーパターンと組み合わせることで、エンジニアリングチームに、新機能のリリース中に問題が発生した際に本当に何が起きているのかを調査するためのツールを提供できます。
オブザーバビリティ駆動開発の重要性
本章の結論として、オブザーバビリティがソフトウェア開発ライフサイクルの早い段階で使用されるべきであると強調しています。
テスト駆動開発は、コードが定義された仕様に対してどのように動作するかを検証するのに役立ちますが、オブザーバビリティ駆動開発は、コードが本番環境の混沌とした世界でどのように振る舞うかを検証するのに役立ちます。
ソフトウェアエンジニアにとって、本番環境の実際の動作を理解できないことは、本番環境をガラスの城のように扱う考え方を生んできました。新機能がリリースされる際の振る舞いを適切に観察することで、本番環境をエンドユーザーがソフトウェアを体験する対話型の遊び場へと変えることができるのです。
オブザーバビリティ駆動開発は、高いパフォーマンスを発揮するソフトウェアエンジニアリングチームを実現するために不可欠です。 オブザーバビリティをSREやインフラエンジニア、運用チームだけのものと考えるのではなく、すべてのソフトウェアエンジニアが自らのプラクティスの重要な部分としてオブザーバビリティを取り入れるべきなのです。
本章を読んで、私はオブザーバビリティ駆動開発の重要性を再認識しました。特に、本番環境の振る舞いを適切に観察することで、ソフトウェアエンジニアのマインドセットを変革できるという点に共感しました。
Chapter 12. Using Service-Level Objectives for Reliability
「Chapter 12. Using Service-Level Objectives for Reliability」は、サービスレベル目標(SLO)を用いたアラート戦略が、従来の閾値ベースのモニタリングアプローチよりも効果的であることを示した章です。本章は、SLOとオブザーバビリティを組み合わせることで、システムの信頼性を向上させる方法を提案しています。
従来のモニタリングアプローチがもたらすアラート疲労
本書は、まず従来のモニタリングアプローチの問題点を指摘しています。従来のアプローチでは、測定が容易なシステムの状態を単純なメトリクスで追跡し、それに基づいてアラートを発生させます。しかし、これらのアラートは、false positiveを大量に生み出し、意味のある行動につながりません。
その結果、エンジニアリングチームは、信頼性の低いアラートを無視したり、抑制したりするようになります。 これは「逸脱の正常化(normalization of deviance)」と呼ばれる危険な状態です。アラートが「正常」とみなされ、無視されるようになると、重大な見落としにつながる可能性があるのです。
また、従来のモニタリングアプローチは、既知の障害モードにのみ対応できます(known-unknowns)。しかし、分散システムでは、予測不可能な障害モードが発生し、ユーザーエクスペリエンスに影響を与える可能性があります。従来のシステムメトリクスでは、このような予期せぬ障害モードを見逃してしまうのです。
ユーザーエクスペリエンスを指標とする
本書は、アラートの設定において、ユーザーエクスペリエンスに焦点を当てることの重要性を説いています。従来のアプローチでは、システムエンジニアが任意の定数を選択し、ユーザーエクスペリエンスが悪化する時点を予測する必要がありました。しかし、システムのパフォーマンスは、ユーザーの行動によって大きく変動するため、静的な閾値では対応できません。
信頼性の高いアラートには、より細かい粒度と信頼性が必要です。 そこで役立つのがSLOです。SLOは、システムメトリクスではなく、重要なユーザージャーニーに基づいてサービスの可用性の目標値を定量化します。この目標値は、サービスレベルインジケーター(SLI)を使って測定されます。
サービスレベル目標とは何か?
本書は、SLOの概要を説明し、その重要性を強調しています。SLOは、サービスの健全性を測定するための内部目標です。SLOは、サービスプロバイダーと顧客の間のサービスレベルアグリーメントの重要な部分であり、外部に向けた可用性のコミットメントよりも厳しい基準を設定します。
SLOは、ユーザーエクスペリエンスに影響を与える症状にのみ焦点を当てることで、アラートの範囲を狭めます。何かがユーザーの体験に影響を与えている場合、アラートが発生し、誰かがなぜそうなっているのかを調査する必要があります。 しかし、SLOベースのアラートは、サービスがどのように低下しているかを示すものではありません。単に何かがおかしいことを知らせるだけなのです。
SLOベースのアラートへの文化の変革:ケーススタディ
本書は、Honeycombでの実際の事例を紹介し、SLOベースのアラートへの文化の変革について説明しています。
Honeycombでは当初、SLOを実装していたものの、チームはまだ完全には信頼していませんでした。SLOアラートは低優先度の受信箱に送られ、チームは従来のモニタリングアラートに依存し続けていたのです。
しかし、あるインシデントで、SLOベースのアラートが従来のアラートよりもはるかに早く問題を検出したことで、状況は変わりました。メモリリークによるクラッシュが発生していましたが、従来のモニタリングでは検出されませんでした。 一方、SLOは嘘をつきませんでした。SLOエラーバジェットはインシデントの開始時からほぼ完全に消費され、ユーザーへの影響が明らかになったようでした。
このインシデントがチームの文化を変えました。 SLOベースのアラートの価値が証明されたことで、エンジニアリングチームはSLOベースのアラートを従来のアラートと同等に尊重するようになりました。しばらくしてSLOベースのアラートに頼るようになると、チームはSLOデータのみに基づいてアラートを出すことに徐々に慣れていったのです。
SLOとオブザーバビリティによる信頼性の向上
本章の結論として、SLOが従来の閾値ベースのモニタリングよりも効果的なアラート戦略であることを強調しています。
アラート疲労は、従来のモニタリングソリューションが取る潜在的な原因ベースのアプローチによって引き起こされています。 アラート疲労は、役立つアラートのみを作成することで解決できます。役立つアラートとは、サービスのユーザーエクスペリエンスが低下した状態にあることを確実に示し、かつ実行可能でなければなりません。
SLOは、インシデントアラートの背後にある「何が」と「なぜ」を切り離します。 痛みの症状ベースのアラートに焦点を当てることで、SLOは顧客体験の信頼できる指標となります。SLOがイベントベースの指標に基づいている場合、誤検知と見逃しが大幅に減少します。したがって、SLOベースのアラートは、アラートをより実行可能で、タイムリーなものにする生産的な方法となるのです。
しかし、SLOベースのアラートだけでは、痛みがあることは分かっても、なぜそうなっているのかは分かりません。SLOベースのアラートを実行可能なものにするには、本番システムが十分にデバッグ可能でなければなりません。 システムにオブザーバビリティを持たせることが、SLOを使う上で非常に重要なのです。
Chapter 13. Acting on and Debugging SLO-Based Alerts
「Chapter 13. Acting on and Debugging SLO-Based Alerts」は、SLOベースのアラートを使用する際のエラーバジェットの役割と、アラートをトリガーするためのメカニズムについて詳細に解説した章です。本書は、エラーバジェットの枯渇を予測するための様々な予測手法を紹介し、組織のニーズに最適な手法を選択するための考慮事項を示しています。また、サービスレベル目標(SLO)の実装について解説した「Implementing Service Level Objectives」も参考になります。この書籍は、SLOベースのアプローチによる信頼性を実現するための文化とツールを構築する際の入門書およびデイリーリファレンスとして役立ちます。高度なSLOおよびサービスレベル指標(SLI)の技術について詳細な分析を提供し、数学的モデルと統計学の知識を武器に、ユーザーの視点から信頼性を意味のある形でSLIとして測定可能なシステムを構築する方法を学ぶことができます。
エラーバジェットが空になる前にアラートする
本章は、まずエラーバジェットの概念について説明しています。エラーバジェットは、ビジネスが許容できるシステムの最大の利用不可時間を表します。例えば、SLOが99.9%の成功率を確保することであれば、1年間で8時間45分57秒(または1ヶ月で43分50秒)以上のダウンタイムは許容されません。
SLOに違反する前にアプリケーションやシステムの問題を認識し、解決するためには、エラーバジェットが完全に消費される前に予測的なバーンアラートが必要です。バーンアラートは、現在のバーン率が継続した場合にエラーバジェットが枯渇する時期を予測し、早期警告を提供します。
時間をスライディングウィンドウとして捉える
本書は、SLOの分析にあたって、固定ウィンドウとスライディングウィンドウのどちらを使用するかを選択する必要があると述べています。固定ウィンドウは、例えば月の1日から30日までのように、カレンダーに従います。一方、スライディングウィンドウは、直近の30日間のように、移動する期間を見ます。

本書は、ほとんどのSLOにとって、30日のスライディングウィンドウが最も実用的な期間だと述べています。固定ウィンドウは顧客の期待に合わないため、より滑らかな体験を提供するスライディングウィンドウを使用すべきだと主張しています。
予測的バーンアラートを作成するための予測
本書は、予測的バーンアラートをトリガーするための2つのモデルを紹介しています。1つ目は、ゼロ以外の閾値を選択し、残りのエラーバジェットがその閾値を下回ったときにアラートをトリガーする方法です。
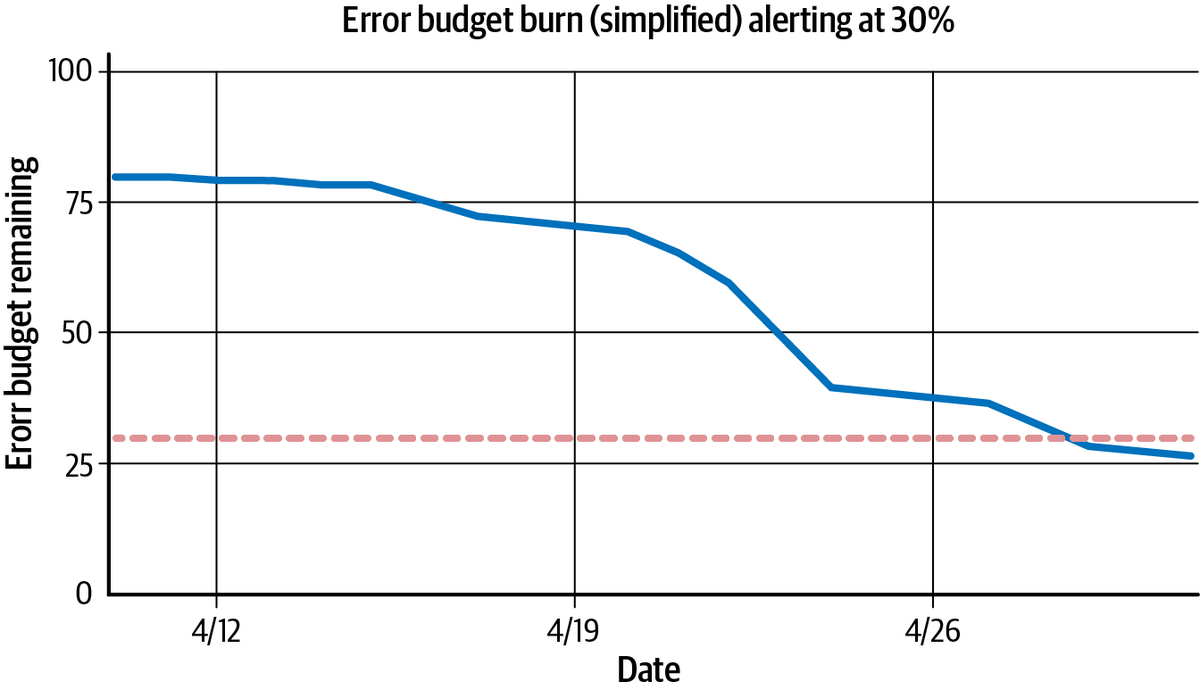
2つ目は、現在の状態がエラーバジェット全体を消費する結果になるかどうかを予測する方法です。この方法では、基準ウィンドウ(ベースラインウィンドウ)と、予測が及ぶ将来の時点を決定する先読みウィンドウ(ルックアヘッドウィンドウ)の2つを考慮する必要があります。

本書は、基準ウィンドウとして、先読みウィンドウの4分の1の期間を使用することを推奨しています。つまり、4時間後に予算を使い果たすかどうかを予測するには、過去1時間のパフォーマンスデータを使用するのです。
バーン率を予測するために、著者は2つのアプローチを紹介しています。短期バーンアラートは、最近の期間の基準データのみを使用して軌跡を外挿します。コンテキスト対応バーンアラートは、過去のパフォーマンスを考慮し、SLOの全体のウィンドウにおける成功イベントと失敗イベントの総数を使用して計算を行います。
SLOバーンアラートへの対応
本書は、バーンアラートがトリガーされたときの対応についても説明しています。新しい予期せぬ種類のバーンが発生しているのか、それとも緩やかで予想されるバーンなのかを診断する必要があります。
本書は、バーンアラートがバースト状態の一部なのか、エラーバジェットのかなりの部分を一度に消費してしまうようなインシデントなのかを評価すべきだと述べています。現在の状況を過去の率と比較することで、その重要性をトリアージするための有益なコンテキストが得られます。
SLOのためのオブザーバビリティデータと時系列データ
本書は、SLOに時系列データを使用することで、いくつかの複雑さが生じると指摘しています。時系列データの問題は、99.99%以上の可用性目標を持つ厳格なSLOの場合に特に顕著です。このようなSLOでは、エラーバジェットが数分または数秒で枯渇する可能性があります。
一方、SLOの計算にイベントデータを使用すると、システムの健全性を評価するためのリクエストレベルの粒度が得られます。モダンな分散システムでは、100%の全体的な障害よりも、部分的な障害の方が一般的です。そのため、イベントベースの計算の方がはるかに有用なのです。
本書は、サービスの実際のユーザーエクスペリエンスを追跡するオブザーバビリティデータは、粗く集約された時系列データよりも、システムの状態をより正確に表現していると述べています。アクション可能なアラートのためにどのデータを使用するかを決定する際、オブザーバビリティデータを使用することで、ビジネスが気にかけている全体的な顧客体験に非常に近い条件に焦点を当てることができるのです。
SLOとオブザーバビリティデータの組み合わせ
本章の結論として、SLOとオブザーバビリティデータを組み合わせることの重要性を強調しています。
SLOは、ノイズの多いモニタリングの問題を解決するモダンな形式のモニタリングです。オブザーバビリティに特化しているのは、イベントデータがSLOモデルに追加する力です。 エラーバジェットのバーン率を計算する際、イベントは本番サービスの実際の状態をより正確に評価します。
また、SLOが違反の危険にあることを知るだけでは、どのユーザーが影響を受けているのか、どの依存サービスが影響を受けているのか、どのようなユーザー行動の組み合わせがサービスでエラーを引き起こしているのかを判断するための洞察が必ずしも得られるとは限りません。SLOにオブザーバビリティデータを組み合わせることで、バーンバジェットアラートがトリガーされた後、障害がいつ、どこで発生したかを把握できるようになります。
オブザーバビリティデータを使用したSLOは、SREアプローチとオブザーバビリティ駆動型開発アプローチの両方の重要なコンポーネントです。失敗したイベントを分析することで、何がうまくいっていないのか、なぜうまくいっていないのかについての豊富で詳細な情報が得られます。それはシステム的な問題と時折の散発的な障害を区別するのに役立ちます。
本章を読んで、私はSLOとオブザーバビリティデータの組み合わせの重要性を再認識しました。エラーバジェットのバーン率を予測し、早期にアラートを発するための様々な手法は、SREにとって非常に有益です。
また、イベントベースの測定値が、システムの実際の状態をより正確に表現しているという点にも納得しました。私たちのチームでも、SLOの計算にオブザーバビリティデータを活用することで、顧客体験に直結する問題により迅速に対応できるようになりました。
皆さんは、SLOとオブザーバビリティをどのように組み合わせていますか?また、エラーバジェットのバーン率を予測するために、どのような手法を用いていますか?ぜひ、経験や考えを共有してください。
Chapter 14. Observability and the Software Supply Chain
「Chapter 14. Observability and the Software Supply Chain」は、モダンなソフトウェア開発において、オブザーバビリティがいかに重要であるかを示す非常に示唆に富んだ一章でした。著者のFrank Chenは、Slackにおける実際の事例を通して、CI/CDパイプラインにオブザーバビリティを適用することの価値を明確に示しています。ソフトウェアサプライチェーンのセキュリティも重要なトピックであり、「Software Supply Chain Security」(Cassie Crossley著)ではこの分野を包括的に取り上げています。本書は、セキュリティリスクを見渡し、エンドツーエンドのソフトウェアサプライチェーンに組み込む必要のある実践的なコントロールを特定しています。組織がソフトウェア、ファームウェア、ハードウェアのセキュリティ体制を改善するには、サプライチェーンに関わるすべての人が参加する必要があることを実証しており、サプライチェーンの各部分のサイバーセキュリティリスクを特定し、関連する役割を特定し、既存のフレームワークを使ったイニシアティブとコントロールの設計、セキュアな開発ライフサイクルの実践、第三者リスクの評価などについて学ぶことができます。
オブザーバビリティがソフトウェアサプライチェーンに不可欠な理由
本章の冒頭で、Chenは「ソフトウェアサプライチェーン」という概念について説明しています。それは、「開発から、CI/CDパイプラインを通って、本番環境にデプロイされるまでの、ソフトウェアに影響を与えるすべてのもの」を指します。つまり、コードが書かれてから実際にユーザーに届けられるまでの一連のプロセスを指すのです。

Slackでは、早い段階からCIの開発とCDの実践に投資してきました。しかし、急速な成長に伴い、システムの複雑性が増し、境界があいまいになり、限界に達しつつあることに気づきました。テストスイートの実行回数は、一日あたり数千回から数十万回へと爆発的に増加したのです。 この規模になると、適応型キャパシティや、オーバーサブスクリプションなどの戦略でコストとコンピューティングリソースを管理する必要があります。
その結果、開発環境でコードをテストしてデプロイするワークフローは、一部の本番サービスよりも複雑になることがありました。インフラストラクチャの種類やランタイムのバージョンの依存関係が予期せず変更され、意図しない障害が発生する可能性があったのです。
共有ライブラリとディメンション
Slackのオブザーバビリティ導入における主な課題は、複雑さでした。エンドツーエンドテストの失敗は、コードベースの変更、インフラストラクチャの変更、プラットフォームのランタイムなど、複数のコードベースが相互作用した結果である可能性があります。
この問題を解決するために、SlackはCI/CDシステムに分散トレーシングを適用しました。トレーシングを多段構成のビルドシステムに適用することで、わずか数時間のうちに複数の課題を解決できたのです。
オブザーバビリティを実現するには、有用なインストルメンテーションを作成することが必要条件です。優れたインストルメンテーションは、オブザーバビリティを促進します。具体的には、コードをデプロイしてエラーの結果を感じるまでのループを短くするような、強化メカニズムとフィードバックループを作成することを目標にすべきです。
エンジニアは、デプロイ後すぐに以下の質問に答えられるように、自分のコードをインストルメント化することが求められます。
- コードは期待通りに動作しているか?
- 以前のバージョンと比べてどうか?
- ユーザーは積極的にコードを使用しているか?
- 異常な条件は発生していないか?
サプライチェーンの運用化:ケーススタディ
Chenは、Slackがどのようにトレーシングツールとクエリを使ってソフトウェアサプライチェーンを理解し、アラートにつなげているかを具体的な事例で示しています。
コンテキストの理解
最初の事例は、フレーキーなテストの問題に対処するために、Slackのチームがどのように協力したかを示しています。2020年、Slackのエンジニアはエンドツーエンドテストのフレーキーさにフラストレーションを感じていました。多くのエンドツーエンドテストスイートでは、平均15%近くのフレーキーさがありました。
オブザーバビリティチームとオートメーションチームが協力し、Cypressにいくつかのランタイムパラメータとスパンのトレーシングを追加しました。わずか数日で、フレーキーさと強く相関するディメンションが明らかになったのです。エンジニアはこのデータを使って実験を行い、プラットフォームのデフォルトを改善し、フレーキーな設定に対するガードレールを設置しました。その結果、多くのユーザーでテストスイートのフレーキーさが大幅に減少しました。
アクショナブルなアラートの組み込み
次の事例では、Slackがどのようにアラートをエンジニアのワークフローに組み込んでいるかを示しています。オブザーバビリティはSlackのメッセージやダッシュボードを通じて、エンジニアが問題をトリアージするのを助けます。
例えば、あるテストスイートの実行時間が増加したことを示すアラートがトリガーされたとします。アラートのリンクをクリックすると、CIサービストレースダッシュボードが表示されます。ここから、問題のあるテストスイートのトレースを確認できます。
エンジニアは、レート、エラー、デュレーションを可視化したクエリを使って、Checkpoint内のサービス間の個々のメソッドをグループ化し、問題の原因を特定します。
何が変更されたかの理解
最後の事例は、2021年8月のインシデントについてです。複数のユーザーがバックエンドのユニットテストとインテグレーションテストでメモリ不足エラー(OOM)によるテスト失敗を報告しました。
レスポンダーは、前日のフレーキーさの増加を示すアノマリを発見しました。これをヒントに、過去のテストケーストレースを調べ、メモリ使用量の急増を特定しました。
いくつかの疑わしいコミットが特定され、それらを次々とリバートしていきました。専門家は、オブザーバビリティを使ってリアルタイムにシステムの健全性を検証しました。
単なるツールではなく、文化でもある
本章は、ソフトウェアサプライチェーンにおけるオブザーバビリティの有用性を示しています。Chenは、SlackがCI/CDパイプラインにインストルメンテーションを行い、分散システムのデバッグに役立てた事例を紹介しました。
適切なツールとディメンションを用いることで、Slackのエンジニアは、以前は見えなかったCI/CDワークフローの複雑な問題を解決することができました。 アプリケーションが遅い、CIテストがフレーキーだという不満をデバッグする際も、オブザーバビリティは、高度に相互作用する複雑なシステムの問題の相関関係を見つけるのに役立つのです。
ソフトウェアが本番環境でどのように動作するかを理解することは、アプリケーション開発者にとって最優先事項です。しかし、本番環境に至る前に、同様に複雑で理解やデバッグが難しい分散システムが存在することを忘れてはいけません。ソフトウェアサプライチェーンにオブザーバビリティを組み込むことは、Slackだけでなく、あらゆるビジネスにとって競争上の優位性となるのです。
本章から私が学んだ最も重要な教訓は、オブザーバビリティがソフトウェア開発のあらゆる段階で不可欠だということです。本番環境だけでなく、ソフトウェアがビルド、テスト、デプロイされるプロセス全体を通して、オブザーバビリティを適用することで、より高品質で信頼性の高いソフトウェアを提供できるようになります。
また、オブザーバビリティは単なるツールではなく、文化でもあるということを再認識しました。チーム全体で問題の可視性を高め、データに基づいて意思決定を行う文化を育むことが、本当の意味でのオブザーバビリティの実現につながるのです。
Part IV. Observability at Scale
この部ではオブザバビリティが大規模に実践されたときに何が起こるかを検討します。
Chapter 15. Build Versus Buy and Return on Investment
「Chapter 15. Build Versus Buy and Return on Investment」は、オブザーバビリティソリューションを自社で構築するか、ベンダーから購入するかという選択について、深い洞察を提供してくれる一章でした。本書は、この二者択一の問題を、機会費用や総所有コスト(TCO)など、多角的な視点から分析し、それぞれのアプローチのメリットとデメリットを明らかにしています。
オブザーバビリティのROI分析
本書は、自社でオブザーバビリティソリューションを構築する際の真のコストについて警鐘を鳴らしています。一見、オープンソースのコンポーネントを使えば、ほとんど費用がかからないように思えるかもしれません。 しかし、実際には、メンテナンスのためのコンテキストスイッチングや、コアビジネスに直接つながらない領域にエンジニアリングリソースを割くことによる機会損失など、目に見えないコストが膨大にかかっているのです。コストについてはこちらがめちゃくちゃに組織毎に正解が違うと思ったのですが良い考察だと思いました
一方、ベンダーソリューションを購入する場合、コストは明確です。請求書に明記されているからです。しかし、ここでも落とし穴があります。シートごと、ホストごと、サービスごと、クエリごとなど、予測不可能な指標に基づく価格設定は、将来的なコストを見積もるのが非常に難しいのです。オブザーバビリティツールを本来の目的で使用すると、使用量が爆発的に増加し、生み出す収益に見合わないほどの費用がかかってしまう可能性があります。
自社構築のメリットとリスク
自社構築の最大のメリットは、組織のニーズに合わせてカスタマイズできることです。長年かけて、自社のシステムに深く根ざした、独自の文化を活かしたソリューションを開発できるのです。
しかし、そこにはリスクもあります。本当に自社でベンダーよりも優れたソリューションを開発できるのでしょうか? UIやワークフローの柔軟性、パフォーマンスなど、組織全体での採用を促すために必要な機能を提供できるでしょうか。もしできなければ、多くの時間と費用、そしてビジネスチャンスを失ったあげく、ごく一部のユーザーしか使わないシステムを構築することになりかねません。
購入のメリットとリスク
購入の最大のメリットは、迅速に価値を得られることです。数分から数時間で始められ、すぐにオブザーバビリティの恩恵を受けられます。
しかし、ベンダーロックインのリスクがあります。一度ある商用ソリューションを選択すると、他のソリューションへの移行に多大な時間と労力がかかるのです。 オープンソースのOpenTelemetryを活用することで、このリスクを軽減できます。
また、オブザーバビリティの専門知識を社内で育成できないリスクもあります。単に既製のソリューションを利用するだけでは、自社特有のニーズにオブザーバビリティをどう適用すべきか、深く理解できないかもしれません。
二者択一ではない
本書は、「構築か購入か」は二者択一ではないと強調しています。自社のオブザーバビリティチームが、ベンダーソリューションの上に独自のレイヤーを構築する、という第三の選択肢があるのです。
オブザーバビリティチームは、ベンダーと自社のエンジニアリング組織をつなぐ役割を果たします。ライブラリや抽象化を提供し、命名規則を標準化し、コードのインストルメンテーションについてアドバイスします。コアビジネスの価値提供から逸れることなく、独自のニーズを満たすソリューションを構築できるのです。
タダより高いものはない
オブザーバビリティソリューションの選択において、Total Cost of Ownership(TCO)を十分に考慮すべきです。「タダより高いものはない」という言葉がありますが、オープンソースを使った自社構築には、導入・運用のためのリソース確保、セキュリティ対策、パフォーマンスチューニングなどの見えないコストが付随します。一方、ベンダーソリューションには、ライセンス料の値上げやベンダーロックインによる代替手段の制約など、将来的なコスト高騰のリスクがあります。そこで、オープンソースとベンダーソリューションのハイブリッド活用が有力な選択肢となります。「Observability with Grafana」では、一部有償サービスを提供しつつも、Grafanaをはじめとするオープンソースツールを中核に据えることで、オープンソースのメリットを最大限に活かしながら、ベンダーによるサポートやサービスを組み合わせることができます。Loki, Grafana, Tempo, and Mimir からなるLGTMスタックを学習することができる。
しかし、自社構築と購入を組み合わせることで、両者のメリットを享受できます。 拡張性の高いベンダーソリューションの上に、自社のオブザーバビリティチームが独自のレイヤーを構築する。それが、多くの組織にとって最適なアプローチなのです。
私自身、SREとしてオブザーバビリティソリューションの選定に関わった経験から、著者の主張に強く共感しました。当初は、オープンソースを組み合わせた自社構築を志向していましたが、メンテナンスの負荷やスケーラビリティの課題に直面し、方針を転換しました。現在は、商用ソリューションをベースに、我々のチームが独自の機能を開発しています。これにより、オブザーバビリティという強力な武器を手に入れつつ、自社のニーズにもきめ細かく対応できるようになったのです。
Chapter 16. Efficient Data Storage
「Chapter 16. Efficient Data Storage」は、オブザーバビリティデータを効果的に保存・取得するための課題と、その解決策について深く掘り下げた章でした。本書は、オブザーバビリティに必要な機能要件を満たすために、データ層でどのようなトレードオフが必要なのかを丁寧に解説しています。
オブザーバビリティのための機能要件
本章の冒頭で、著者はオブザーバビリティのための機能要件について説明しています。本番環境で障害が発生したとき、オブザーバビリティデータに対するクエリはできるだけ迅速に結果を返さなければなりません。 数秒以内に結果が返ってこなければ、生産性のあるデバッグ作業はできません。
また、イベントは高カーディナリティで高次元のデータを分析できるようにする必要があります。イベントやトレーススパン内のどのフィールドもクエリ可能でなければならず、事前に集計することはできません。 さらに、データの取得パフォーマンスを特定のディメンションに依存させてはいけません。
加えて、オブザーバビリティデータは耐久性と信頼性も求められます。クリティカルな調査に必要なデータを失ったり、データストアのコンポーネントの障害によって調査が遅れたりすることは許されないのです。
これらの要件は、従来のデータストレージソリューションでは満たすのが難しいものばかりです。特に、大規模なシステムになればなるほど、これらの問題はより顕著になります。
時系列データベースの限界
本書は、これらの要件を満たすために、時系列データベース(TSDB)が不十分であると指摘しています。TSDBは、同じタグの組み合わせが頻繁に再利用され、新しい組み合わせが稀な場合に、追加のトラフィックのコストを償却することを目的としています。
しかし、オブザーバビリティの要件である高カーディナリティと高次元のデータを扱おうとすると、タグの一意な組み合わせごとに新しい時系列が作成され、カーディナリティの爆発を引き起こしてしまうのです。 これは、TSDBの設計思想と根本的に相容れないものなのです。

TSDBは、システムのパフォーマンスを単純な指標に集約することで、送信されるデータ量を削減し、クエリのパフォーマンスを向上させます。しかし、これは後でそのデータから導き出せる答えの数を制限してしまうのです。オブザーバビリティワークロードでは、イベントの事前集約は許容されません。 TSDBは、オブザーバビリティの基本的な構成要素としては限界があるのです。
列指向ストレージ
そこで本書は、行指向ストレージと列指向ストレージのハイブリッドアプローチを提案しています。データをタイムスタンプでパーティショニングし、各セグメント内でデータを列ごとに保存する。 これにより、任意の行と列の部分スキャンを効率的に実行できるようになります。
具体的には、Honeycombの独自データストアであるRetrieverの実装を例に、この手法を詳しく解説しています。
Retrieverでは、特定のテナントの新しく到着したトレーススパンを、そのテナントの現在アクティブなストレージファイルセット(セグメント)の末尾に挿入します。読み取り時に適切なセグメントをクエリするために、現在のセグメントの最も古いイベントタイムスタンプと最新のイベントタイムスタンプを追跡しているのです。

このセグメントパーティショニングによるタイムスタンプの利点は、個々のイベントを厳密な順序に並べ替える必要がないこと、そして各セグメントの内容が追記専用のアーティファクトになることです。 これにより、書き込み時のオーバーヘッドを大幅に削減できます。
各セグメント内では、イベントをフィールドごとに分解し、複数のイベントにまたがる同じフィールドの内容を一緒に保存します。これにより、クエリ時に関連する列のみにアクセスすることができるのです。
列指向ストレージは、行指向ストレージと比べて、必要なサブセットのデータのみを素早く調べることができます。一方で、1つの行のデータにアクセスするには、任意の量のデータ(最大でテーブル全体)をスキャンする必要があるかもしれません。
Retrieverは、この両者のトレードオフに対処するために、テーブルを手動で粗くシャーディングし、クエリ時にユーザーが適切なシャードを特定して結合する という手法を採用しています。これにより、行と列の両方の部分スキャンを効率的に実行できるようになっているのです。
クエリワークロード
本書は、列指向ストレージを使ってクエリワークロードを実行する方法についても説明しています。クエリの時間範囲と重なるセグメントを特定し、各セグメントでフィルタや出力に使用される列を独立にスキャンする。 その後、セグメント内およびセグメント間で集約を行い、最終的な結果を返します。
この手法により、高カーディナリティと高次元のデータを効率的に扱うことができます。タイムスタンプ以外のディメンションに特権はなく、任意の複雑な組み合わせでフィルタリングできるのです。 事前集約や、データの複雑さに対する人為的な制限も必要ありません。トレーススパン上のどのフィールドもクエリ可能なのです。
Retrieverでは、オープンな列ファイルが常にクエリ可能であり、クエリプロセスが部分ファイルの読み取りのためのフラッシュを強制できるようにしています。これにより、セグメントが確定し、圧縮されるのを待つことなく、リアルタイムでデータにアクセスできるようになっているのです。
また、Retrieverは、データの取り込みとシリアライズの関心事をデータのクエリの関心事から分離しています。これにより、シリアライズプロセスに問題が発生しても、古いデータのクエリを妨げることはありません。 クエリエンジンへのスパイクがデータの取り込みとシリアライズを妨げないという副次的なメリットもあります。
スケーラビリティと耐久性
大規模なデータセットでは、水平方向のスケールアウトと、データ損失やノードの一時的な利用不可に対する耐久性が求められます。Retrieverでは、スケーラビリティと耐久性のためにストリーミングデータパターンを使用しています。 Apache Kafkaを活用し、プロデューサーやコンシューマー、ブローカーの再起動に対して弾力性のある、順序付けられた永続的なデータバッファを維持しているのです。
受信プロセスとストレージプロセスの関心事を分離することで、受信ワーカーまたはストレージワーカーを自由に再起動でき、データのドロップや破損を避けることができます。 Kafkaクラスタは、災害復旧シナリオでの再生に必要な最大期間だけデータを保持すればよいのです。
スケーラビリティを確保するために、書き込みワークロードに必要な数のKafkaパーティションを作成します。各パーティションは、各データセットに対して独自のセグメントセットを生成します。 クエリ時には、パーティションに関係なく、時間とデータセットに一致するすべてのセグメントをクエリする必要があります。
冗長性を確保するために、複数の取り込みワーカーが任意のKafkaパーティションから消費できます。Kafkaは一貫した順序付けを保証し、取り込みプロセスは決定論的なので、単一のパーティションを消費する並列の取り込みワーカーは、同一の出力を生成する必要があります。
この方法で、高カーディナリティと高次元の任意の組み合わせに対して、高速で耐久性のあるクエリを実現できるのです。
オブザーバビリティデータ管理の新しいアプローチ
本章から学んだ最も重要な教訓は、オブザーバビリティワークロードには独自のパフォーマンス特性が必要だということです。従来のストレージシステムでは、リアルタイムのデバッグワークフローをサポートするのに十分なパフォーマンスを発揮できません。
Retrieverの実装は、これらの課題に対する一つの解決策を提示しています。タイムスタンプによるセグメントパーティショニングと、セグメント内の列指向ストレージを組み合わせることで、高速性、コスト効率、信頼性という、オブザーバビリティに不可欠な要件を満たしているのです。
もちろん、これが唯一の解決策というわけではありません。Google Cloud BigQuery、ClickHouse、Druidなども、オブザーバビリティワークロードを適切に処理できる可能性があります。ただし、これらのデータストアは、オブザーバビリティ固有のワークロードに対する運用テストがまだ十分ではなく、必要な自動シャーディングをサポートするためにカスタム作業が必要になるかもしれません。
本章で紹介された手法は、現代のオブザーバビリティバックエンドのアーキテクチャを理解するのに非常に役立ちます。 また、自社でオブザーバビリティソリューションを構築する必要がある場合にも、貴重な教訓となるでしょう。
ElasticsearchやCassandraなど、この目的にはあまり適さないデータストアを維持するのに苦労するよりも、専用の列指向ストアを採用することを強くお勧めします。 それが、オブザーバビリティデータを管理するための新しいアプローチなのです。
私自身、SREとして大規模なオブザーバビリティシステムの構築に携わった経験から、著者の指摘に強く共感しました。当初は、一般的なNoSQLデータベースを使っていましたが、クエリのパフォーマンスとコストの問題に直面しました。列指向ストレージに移行したことで、高カーディナリティと高次元のデータを、低コストかつ高速に扱えるようになったのです。
また、データの取り込みとクエリを分離することの重要性も実感しました。片方のプロセスで問題が発生しても、もう片方に影響を与えないようにすることが、システム全体の安定性につながります。 Kafkaなどのストリーミングプラットフォームを活用することで、この分離をスマートに実現できるのです。
Chapter 17. Cheap and Accurate Enough: Sampling
「Chapter 17. Cheap and Accurate Enough: Sampling」は、オブザーバビリティデータのサンプリングについて、その戦略と実装方法を詳細に解説した章でした。本書は、サンプリングがリソース制約に対処しつつ、データの忠実性を維持するための有効な手段であることを明確に示しています。
サンプリングによるデータ収集の最適化
本書は、ある規模を超えると、すべてのイベントを収集・処理・保存するためのコストが、そのメリットを大幅に上回ってしまうと指摘しています。オブザーバビリティイベントが膨大なデータの洪水になると、データ量を減らすことと、エンジニアリングチームが必要とする重要な情報を失うことのバランスが問題になるのです。
しかし、多くのアプリケーションでは、イベントの大半がほぼ同一で成功しています。デバッグの核心は、新たなパターンを検出したり、障害時の失敗イベントを調べたりすることです。その観点からすると、すべてのイベントをバックエンドに送信するのは無駄なのです。 代表的なイベントを選択し、実際に発生したことを再構成するために必要なメタデータとともに送信することで、オーバーヘッドを削減しつつ、データの元の形状を忠実に復元できるのです。
サンプリング戦略の違い
本書は、サンプリングの様々な戦略について説明しています。最もシンプルなのは、一定の確率でデータを保持する「一定確率サンプリング」です。しかし、これは、エラーケースを重視する場合や、トラフィック量が大きく異なる顧客がいる場合には効果的ではありません。
より洗練された手法としては、最近のトラフィック量に基づいてサンプリング率を動的に調整する「最近のトラフィック量サンプリング」や、イベントのペイロードに基づいてサンプリング率を調整する「イベントコンテンツ(キー)サンプリング」などがあります。

さらに、これらの手法を組み合わせ、各キーの最近のトラフィック量に基づいてサンプリング率を動的に調整することもできます。適切なサンプリング戦略は、サービスを流れるトラフィックの特性や、そのサービスにヒットするクエリの多様性によって異なります。
トレースイベントのサンプリング
トレースイベントの場合、サンプリングの決定を行うタイミングも重要になります。トレーススパンは複数のサービスにまたがって収集されるため、すべてのスパンが選択される確率は比較的低くなります。
すべてのスパンを確実にキャプチャするには、サンプリングの決定をいつ行うかに応じて、特別な配慮が必要です。イベントの開始時に決定を行う「ヘッドベースサンプリング」と、イベントの実行完了後に決定を行う「テールベースサンプリング」の2つのアプローチがあります。
コードによるサンプリング戦略の実装
本書は、これらのサンプリング戦略をGoのコード例で示しています。一定確率サンプリングから始まり、サンプリング率の記録、一貫性のあるサンプリング、ターゲットレートサンプリング、複数の静的サンプリングレート、キーとターゲットレートによるサンプリング、任意の数のキーでの動的レートサンプリングと、徐々に概念を発展させていきます。
最終的には、ヘッドベースサンプリングとテールベースサンプリングを組み合わせ、下流のサービスにトレースのサンプリングを要求できるようにしています。これは、デバッグに必要なすべてのコンテキストをキャプチャするための柔軟性を提供する強力な例です。

大切なのは状況に応じた賢明なサンプリング
本章から学んだ最も重要な教訓は、サンプリングがオブザーバビリティデータを洗練するための有用なテクニックだということです。サンプリングは大規模な環境では必須ですが、小規模な環境でも様々な状況で有用です。
コードベースの例は、様々なサンプリング戦略がどのように実装されるかを示しています。OpenTelemetryのようなオープンソースのインストルメンテーションライブラリがこの種のサンプリングロジックを実装するようになってきているため、自分のコードでこれらのサンプリング戦略を再実装する必要性は低くなっています。
しかし、サードパーティのライブラリに依存する場合でも、サンプリングがどのように実装されているかを理解することは不可欠です。 それにより、自分の状況に合った方法を選択できるようになるからです。
何を、いつ、どのようにサンプリングするかは、コードをどのようにインストルメント化するかを決める際と同様に、組織のユニークなニーズによって定義されるのが最適です。イベントのどのフィールドがサンプリングに興味深いかは、環境の状態を理解し、ビジネス目標の達成に与える影響を判断するのにどれだけ役立つかに大きく依存します。
私自身、SREとして大規模なオブザーバビリティシステムの運用に携わった経験から、著者の主張に強く共感しました。当初は、すべてのイベントを収集していましたが、データ量の爆発的な増加に悩まされました。適切なサンプリング戦略を導入したことで、リソース消費を抑えつつ、デバッグに必要な情報を確実に取得できるようになったのです。
また、状況に応じてサンプリング戦略を使い分けることの重要性も実感しています。フロントエンドのアプリとバックエンドのサービスでは、最適なサンプリング方法が大きく異なります。 画一的なアプローチではなく、各システムの特性を考慮した柔軟なサンプリングが不可欠だと考えています。
Chapter 18. Telemetry Management with Pipelines
「Chapter 18. Telemetry Management with Pipelines」は、複雑化するアプリケーションインフラストラクチャにおいて、テレメトリデータを効果的に管理するためのパイプラインの役割について解説した章でした。著者のSuman KarumuriとRyan Katkovは、Slackでの実際の事例を通して、テレメトリパイプラインの設計と運用のベストプラクティスを共有しています。
テレメトリパイプラインの利点
本書は、テレメトリパイプラインを構築することで得られる様々なメリットを挙げています。まず、パイプラインによって、テレメトリデータをアプリケーションから異なるバックエンドにルーティングすることができます。 これにより、アプリケーションの変更なしに、データの流れを柔軟に制御できるようになるのです。
また、セキュリティ上の理由から、特定のチームのみがテレメトリデータにアクセスできるようにしたり、GDPR(一般データ保護規則)やFedRAMP(米連邦リスク・認証管理プログラム)などのコンプライアンス要件を満たすために、データの保存場所や保持期間を制限したりすることもできます。
ワークロードの分離も、テレメトリパイプラインの重要な機能です。 大量のログを生成するアプリケーションと低ボリュームのアプリケーションを分離することで、クラスタのパフォーマンスへの影響を最小限に抑えられます。
さらに、パイプラインは、オブザーバビリティバックエンドの停止時にデータを一時的にバッファリングする役割も果たします。これにより、テレメトリデータのギャップを防ぎ、サービスの可視性を維持することができるのです。
テレメトリパイプラインのアナトミー
本書は、機能的なテレメトリパイプラインの基本的なコンポーネントとアーキテクチャについても説明しています。
単純に言えば、テレメトリパイプラインは、レシーバー、バッファー、プロセッサー、エクスポーターが直列に連なったものです。レシーバーはソースからデータを収集し、バッファーはデータを一時的に保存します。プロセッサーはバッファーからデータを取得し、変換を適用してからバッファーに戻します。エクスポーターは、バッファーからデータを取り出し、テレメトリバックエンドに書き込みます。

より複雑な設定では、レシーバー→バッファー→レシーバー→バッファー→エクスポーターという一連のチェーンを形成することもあります。

パイプライン内のレシーバーやエクスポーターは、容量計画、ルーティング、データ変換など、可能な操作の1つのみを担当することが多いのです。
Slackでのテレメトリ管理の事例
本書は、Slackがどのようにテレメトリパイプラインを活用しているかを具体的に解説しています。
Slackでは、メトリクスの集約にPrometheusを使用しています。PHPやHackアプリケーションサーバーからメトリクスを収集するために、カスタムのPrometheusライブラリを使って、リクエストごとにメトリクスをローカルデーモンに送信しています。

ログとトレースイベントの管理には、社内で開発したMurronというGoアプリケーションを使用しています。Murronは、レシーバー、プロセッサー、エクスポーターの3種類のコンポーネントで構成されており、毎秒数百万のメッセージを処理しています。

Slackでは、トレースデータの構造を簡素化するために、SpanEventという新しいフォーマットを実装しています。これにより、エンジニアがトレースを簡単に生成・分析できるようになり、CI/CDシステムのインストルメンテーションなど、新しい可能性が開けるのです。

テレメトリパイプラインの重要性と選択
本章から学んだ最も重要な教訓は、テレメトリパイプラインが、オブザーバビリティデータを効果的に管理するために不可欠だということです。 パイプラインは、データのルーティング、セキュリティ、コンプライアンス、ワークロードの分離、バッファリングなど、様々な課題に対処するための強力なツールとなります。
本書は、オープンソースのツールを組み合わせることで、今日から簡単にテレメトリパイプラインを構築できると述べています。一方で、組織の成長に伴い、パイプラインの管理は複雑になり、多くの課題をもたらすことも指摘しています。
ビジネスの現在のニーズに合わせてパイプラインを構築し、将来のニーズを予測しつつも、過剰な実装は避けるべきだと著者は勧めています。 モジュール性を維持し、プロデューサー、バッファー、プロセッサー、エクスポーターのモデルに従うことで、オブザーバビリティ機能をスムーズに運用しながら、ビジネスに価値を提供できるようになるのです。
私自身、SREとして複雑なマイクロサービスアーキテクチャを管理した経験から、著者の主張に強く共感しました。サービス間の依存関係が複雑になるほど、各サービスが生成するテレメトリデータを適切に管理することが困難になります。テレメトリパイプラインを導入したことで、データの流れを一元的に制御し、必要な情報を適切なバックエンドに確実に届けられるようになったのです。
また、Slackの事例から、オープンソースツールと自社開発ツールを組み合わせて、自社のニーズに合ったパイプラインを構築することの重要性も学びました。すべてを一から開発するのではなく、既存のツールを活用しつつ、不足する機能を補うことが、効率的で柔軟性の高いパイプラインの実現につながるのだと思います。
Part V. Spreading Observability Culture
大規模に可観測性を実践する際の課題に対処することに焦点を当ててます
Chapter 19. The Business Case for Observability
「Chapter 19. The Business Case for Observability」は、オブザーバビリティの導入を組織全体に広めるために、様々なステークホルダーからの支持を得る方法について解説した章でした。本書は、オブザーバビリティの必要性を認識するアプローチとして、リアクティブとプロアクティブの2つの方法を示し、それぞれのメリットとデメリットを詳しく説明しています。
オブザーバビリティ導入へのリアクティブなアプローチ
本書は、まず組織がオブザーバビリティを導入する「リアクティブ」なアプローチについて述べています。多くの組織は、従来のアプローチでは対処できない深刻な課題に直面するまで、オブザーバビリティの必要性を認識しないと指摘しています。
例えば、重大なサービス障害が発生した場合、根本原因分析によって単一の理由が特定されると、経営陣はその理由を基に、問題が迅速に解決されたことを示すための単純化された是正措置を求めがちです。しかし、問題を素早く解決しようとするあまり、過度に単純化されたアプローチをとると、根本的な原因ではなく、最も明白な症状に対処するだけに終わってしまうのです。
また、従来のツールでは許容せざるを得なかった非効率性を認識できないことも、リアクティブなアプローチを招く原因です。オブザーバビリティがないチームは、同じような症状と根本原因を持つインシデントを追跡するために、多くの時間を浪費しています。 これは、エンジニアリングチームにアラート疲労を引き起こし、最終的には燃え尽き症候群につながります。
オブザーバビリティのROI
本書は、オブザーバビリティの導入が、ビジネスにもたらす4つの重要な影響について説明しています。
Forrester Researchが実施した調査では、これらのメリットが数値化されています。オブザーバビリティは、ビジネスの収益性と効率性に直接的かつ間接的に影響を与えるのです。
オブザーバビリティ導入へのプロアクティブなアプローチ
本書は、オブザーバビリティの必要性を予測し、従来のプラクティスを変革するための「プロアクティブ」なアプローチについても述べています。
オブザーバビリティの導入を正当化するためには、まず、TTD(発見までの時間)とTTR(解決までの時間)の改善効果を示すことが有効です。オブザーバビリティは、従来のモニタリングツールでは発見できなかった個々のユーザーの問題を特定し、コア分析ループの自動化によって問題の根本原因を迅速に特定できるようになります。
さらに、問題の検出と解決が迅速になることで、予期せぬ運用作業の量が減少し、オンコールのストレスが軽減されます。これにより、バグの蓄積が減り、新機能の開発に費やす時間が増えるのです。 また、個々のユーザーリクエストのパフォーマンスとボトルネックの原因を理解することで、サービスを迅速に最適化できるようになります。
このように、オブザーバビリティは、エンジニアリングと運用の間の障壁を取り除き、ソフトウェアの開発と運用により多くの責任を持たせることができるのです。
オブザーバビリティの実践
本書は、オブザーバビリティを継続的な実践として導入することの重要性を強調しています。オブザーバビリティは、セキュリティやテスト可能性と同様に、生産サービスの開発と運用に責任を持つ全員が共有すべき責任なのです。
効果的なオブザーバブルシステムを構築するには、技術的な能力だけでなく、心理的安全性を育む文化も必要です。ブレームレス文化は、実験を支援し、好奇心に満ちたコラボレーションを奨励する、心理的に安全な環境を育みます。 これは、従来のプラクティスを進化させるために不可欠なのです。
また、オブザーバビリティの実践では、エンジニアが生産環境の問題を検出し解決するだけでなく、ビジネスインテリジェンスの質問にリアルタイムで答えることも奨励されるべきです。オブザーバビリティは、ソフトウェア開発、運用、ビジネス成果の間の人為的な壁を取り除くのです。
適切なツールの選択
オブザーバビリティには、コードのインストルメンテーション、テレメトリデータの保存、そのデータの分析など、技術的な能力が必要です。そのためには、適切なツールを選択することが重要です。
インストルメンテーションには、OpenTelemetry(OTel)が新たな標準として登場しています。OTelを使えば、特定のベンダーのインストルメンテーションフレームワークにロックインされることなく、テレメトリデータを任意の分析ツールに送信できます。
データストレージと分析は、オープンソースと独自の選択肢があります。商用ベンダーは通常、ストレージと分析をバンドルしていますが、オープンソースソリューションでは、別々のアプローチが必要です。自前のデータストレージクラスタを運用する運用負荷を慎重に検討し、ビジネスニーズの中核となる差別化要因に貴重なエンジニアリングサイクルを投資することが肝要です。
十分なオブザーバビリティの判断
本書は、オブザーバビリティが「十分」であるかどうかを判断する方法についても説明しています。
オブザーバビリティを実践するチームは、新しいコードに適切なインストルメンテーションがバンドルされていることを習慣づける必要があります。コードレビューでは、新しいコードのインストルメンテーションが適切なオブザーバビリティ基準を満たしていることを確認すべきです。
オブザーバビリティが十分であるかどうかは、文化的な行動と主要な結果を見ることでわかります。オブザーバビリティのメリットを享受するチームは、生産環境を理解し運用する自信を高めるはずです。 未解決の「ミステリー」インシデントの割合は減少し、インシデントの検出と解決にかかる時間は組織全体で短縮されるでしょう。
オブザーバビリティ文化を組織全体に広めるために
本章から学んだ最も重要な教訓は、オブザーバビリティの導入には、組織全体の支持が不可欠だということです。 オブザーバビリティの必要性は、重大な障害への対応という形でリアクティブに認識されることもあれば、イノベーションを阻害する要因を取り除くためにプロアクティブに認識されることもあります。いずれにせよ、オブザーバビリティのイニシアチブを支援するためのビジネスケースを作成することが肝要なのです。
オブザーバビリティは、セキュリティやテスト可能性と同様に、継続的な実践としてアプローチする必要があります。オブザーバビリティを実践するチームは、コードの変更にテストと適切なインストルメンテーションを習慣づけなければなりません。 オブザーバビリティには継続的なケアとメンテナンスが必要ですが、本章で概説した文化的行動と主要な結果を探ることで、オブザーバビリティが十分に達成されたかどうかを知ることができるのです。
私自身、SREとしてオブザーバビリティの導入に携わった経験から、著者の主張に強く共感しました。当初は、オブザーバビリティの必要性を感じていたのは私たちのチームだけでしたが、インシデントの検出と解決にかかる時間が大幅に短縮されたことで、他のチームからも注目されるようになりました。 そこで、オブザーバビリティの実践をエンジニアリング組織全体に広げるために、経営陣への働きかけを始めたのです。
当初は難色を示していた幹部たちも、オブザーバビリティによるビジネスへの具体的なメリットを示すことで、徐々に理解を示してくれるようになりました。特に、MTTRの改善とそれによるエンジニアの生産性向上は、説得力のあるデータポイントでした。
結果として、オブザーバビリティはエンジニアリング組織全体に浸透し、今では私たちのカルチャーの中核をなしています。新入社員はコードとインストルメンテーションをセットで書くことを求められ、シニアエンジニアは率先してオブザーバビリティ駆動の開発を実践しています。
Chapter 20. Observability’s Stakeholders and Allies
「Chapter 20. Observability's Stakeholders and Allies」は、組織全体でオブザーバビリティの採用を広げるために、エンジニアリングチーム以外のステークホルダーとどう連携すべきかを解説した章でした。本書は、オブザーバビリティが様々なチームの目標達成に役立つことを示し、それらのチームをオブザーバビリティ採用の同盟者にする方法を詳しく説明しています。SREやアーキテクトの仕事でも似たような話があるのでめちゃくちゃに参考になりました。
エンジニアリング以外のオブザーバビリティニーズの認識
本書は、まずエンジニアリング以外のチームがオブザーバビリティを必要とするケースについて述べています。オブザーバビリティは、ソフトウェアが実際のユーザーの手にどのように動作しているかを理解するためのレンズです。 それは、ビジネスにとって非常に重要な情報なのです。
例えば、新機能の採用状況、新規顧客の製品利用傾向、サービスの可用性情報、信頼性のトレンド、インシデントの予防的解決、機能のリリーススピードなど、様々な側面でオブザーバビリティが役立ちます。顧客体験の理解と改善は、組織のあらゆるチームの仕事なのです。
本書は、オブザーバビリティデータの民主化を勧めています。誰もがソフトウェアの実際の動作を見られるようにすることで、各チームが独自の視点と質問を持ち込み、コミュニケーションのサイロを取り除くことができるのです。
実践におけるオブザーバビリティの同盟者の獲得
次に本書は、様々なステークホルダーにオブザーバビリティがビジネス課題の解決にどう役立つかを示し、オブザーバビリティ採用の同盟者にする方法を説明しています。
カスタマーサポートチーム
カスタマーサポートチームは、顧客から問題の報告を受ける最前線です。従来のモニタリングでは、問題の検出や対応に時間がかかり、その間に顧客からの問い合わせが山積みになってしまいます。
オブザーバビリティを使えば、サポートチームは顧客が報告した問題をデバッグし、既知の問題に関連しているかどうかを迅速に確認できます。 これにより、問題のトリアージを適切に行い、自動検知されない問題を特定することもできるのです。
カスタマーサクセスチームとプロダクトチーム
カスタマーサクセスチームは、顧客が製品を効果的に使えるよう支援する、より積極的なアプローチをとります。オブザーバビリティは、製品の使われ方を理解するのに非常に役立ちます。 これは、プロダクトチームにとっても有益な情報です。
例えば、新機能の採用が芳しくない場合、オブザーバビリティを使って、その機能がワークフローのどこで、どのように呼び出されているかを見ることができます。顧客の行動パターンを分析することで、機能の採用を促進する方法を見出すことができるのです。
営業チームとエグゼクティブチーム
営業チームは、売れる製品機能を理解し、サポートすることに関心があります。オブザーバビリティデータを使えば、どの顧客がどの機能をどのくらいの頻度で使っているかを把握できます。 これは、営業戦略の立案に役立つ定量的な分析です。
エグゼクティブは、ビジネスに最大のインパクトを与える戦略的投資の方向性を確実に理解したいと考えています。オブザーバビリティデータは、エンジニアリング投資とビジネス目標を結びつけるのに役立ちます。 それにより、組織全体でのアライメントを創出できるのです。
オブザーバビリティツールとBIツールの使い分け
本書は、オブザーバビリティツールとビジネスインテリジェンス(BI)ツールの違いについても説明しています。
オブザーバビリティツールは、コード、インフラ、ユーザー、時間の交差点を理解するために特化しています。それに対し、BIツールは非常に一般化されています。オブザーバビリティツールは、クエリの実行時間、精度、鮮度、構造、時間幅、一時性などの点で、BIツールとは異なるトレードオフを行っているのです。
また、BIツールはしばしば集計メトリクスにロックインされ、ビジネス全体の超ビッグピクチャーしか見えなくなります。一方、オブザーバビリティは、製品の使用状況やユーザーの行動について質問する際に、より詳細なレベルでのデータを提供できます。
オブザーバビリティツールを部門間で共有することは、共通言語を促進するための素晴らしい方法です。エンジニアはビジネス言語を使ってドメインモデルを記述することを奨励され、ビジネス側は実際のユーザーベースの多様性を理解できるようになるのです。
オブザーバビリティの採用を組織全体に広げるために
本章から学んだ最も重要な教訓は、オブザーバビリティが、組織内の様々なチームの目標達成に役立つ強力なツールだということです。 エンジニアリングチームだけでなく、プロダクト、サポート、カスタマーサクセス、営業、エグゼクティブなど、あらゆるチームがオブザーバビリティから恩恵を受けることができます。
これらのチームがオブザーバビリティを活用して目標を達成できるよう支援することで、オブザーバビリティ採用の強力な同盟者を獲得できるのです。彼らは、オブザーバビリティ採用の取り組みに優先順位を付け、後押ししてくれるでしょう。
著者が示した事例は決して網羅的ではありません。むしろ、どのようなビジネスチームがオブザーバビリティデータを活用して、より良い結果を達成できるかを考えるためのプライマーとして使えます。 他のビジネスチームの目標達成を支援することが、オブザーバビリティ採用の取り組みを推進するための鍵なのです。
私自身、SREとしてオブザーバビリティの導入に携わった経験から、著者の主張に強く共感しました。当初は、オブザーバビリティの価値をエンジニアリングチーム以外に伝えるのは難しいと感じていました。しかし、様々なチームにオブザーバビリティがどう役立つかを具体的に示すことで、次第に理解と協力を得られるようになったのです。
特に、カスタマーサポートチームとの連携は大きな転機となりました。オブザーバビリティを使ってお客様の問題をより迅速に解決できるようになったことで、サポートチームはオブザーバビリティの強力な支持者になってくれました。 彼らの後押しがあったからこそ、組織全体でのオブザーバビリティ採用が加速したのだと思います。
Chapter 21. An Observability Maturity Model
「Chapter 21. An Observability Maturity Model」は、組織がオブザーバビリティの採用を測定し、優先順位を付けるための指針となる「オブザーバビリティ成熟度モデル(OMM)」について解説した章でした。本書は、OMM が目標とする成果を明確にし、組織のオブザーバビリティ実践の成熟度を評価するための能力を特定しています。OMMについては監視からオブザーバビリティへ〜オブザーバビリティの成熟度/From Monitoring to Observability - Maturity of Observability が良かったのでオススメです。
オブザーバビリティ最前線 〜 事例LTから学ぶ、オブザーバビリティの成熟度〜という勉強会の動画もあるので追記しておきます。
成熟度モデルについての注意点
本書は、まず成熟度モデルの限界について述べています。成熟度モデルは、ソフトウェア工学チームのパフォーマンスレベルに上限がないことや、実践が絶えず進化し改善されていることを考慮していません。 また、モデルが作成された時点での理想的な未来のスナップショットに過ぎず、著者の偏見が多くの仮定に組み込まれている可能性があります。
したがって、成熟度モデルを見る際には、すべての組織に当てはまるワンサイズフィットオールのモデルは存在しないことを常に念頭に置く必要があります。成熟度モデルは、自社のニーズと望ましい成果を批判的かつ体系的に評価するための出発点として役立ちます。 また、長期的な取り組みを推進するのに役立つ、具体的で測定可能な目標を特定し、定量化するのにも役立ちます。
オブザーバビリティが成熟度モデルを必要とする理由
本書は、オブザーバビリティの実践を導入するチームに見られる定性的な傾向と、ソフトウェアエンジニアリングの専門家を対象とした調査から得られた定量的な分析を組み合わせて、OMMを構築したと説明しています。
オブザーバビリティを導入したチームは、導入していないチームに比べて、生産環境でのソフトウェアの品質を確保する能力に自信を持つ確率が3倍高いことがわかりました。 また、オブザーバビリティを導入していないチームは、作業時間の半分以上を、新しい製品機能のリリースにつながらない作業に費やしていました。
これらのパターンは、今日の複雑な社会技術システムから生まれた特性です。ソフトウェアの品質の確保や、機能のイノベーションに費やす時間などの能力を分析することで、グループ行動の病理とその解決策の両方が明らかになります。 オブザーバビリティの実践を採用することは、「よりよいコードを書く」や「よりよい仕事をする」といった個人の努力では解決できない問題の解決に役立つのです。
OMMが参照する能力
本書は、オブザーバビリティの実践の質に直接影響を与える5つの能力について詳しく説明しています。
- レジリエンスを持ってシステム障害に対応する
- 高品質のコードを提供する
- 複雑性と技術的負債を管理する
- 予測可能なペースでリリースする
- ユーザーの行動を理解する
これらの能力は、網羅的なリストではありませんが、潜在的なビジネスニーズの広さを表しています。重要なのは、これらの能力を構築することは「終わり」のない追求であり、常に継続的な改善の余地があるということです。
組織のためのOMMの活用
OMMは、オブザーバビリティを効果的に活用するための組織の能力を見直すのに役立つツールです。モデルは、チームの能力が欠けている点と優れている点を測定するための出発点を提供します。 オブザーバビリティの文化を採用し、広めるための計画を立てる際には、自社のビジネスのボトムラインに最も直接的に影響を与え、パフォーマンスを向上させる能力を優先することが有効です。
成熟したオブザーバビリティ実践を構築することは、直線的な進歩ではなく、これらの能力は真空の中に存在しないことを覚えておくことが重要です。オブザーバビリティはそれぞれの能力に絡み合っており、ある能力の向上が他の能力の結果に貢献することもあります。 そのプロセスの展開は、各組織のニーズに固有のものであり、どこから始めるかは現在の専門分野によって異なります。
各能力を見直し、優先順位を付ける際には、チーム内でこの変革を推進する明確な担当者を特定する必要があります。その取り組みをレビューし、自社に関連する明確な成果重視の指標を開発することが肝要です。 明確なオーナーシップ、説明責任、そして資金と時間の面でのスポンサーシップがなければ、進歩は難しいでしょう。
オブザーバビリティ成熟度モデルが示す道筋
本章から学んだ最も重要な教訓は、オブザーバビリティ成熟度モデルが、組織が望ましい成果を測定し、独自のカスタマイズされた採用パスを作成するための出発点を提供するということです。
オブザーバビリティの実践を成熟させた高パフォーマンスチームを牽引する重要な能力は、以下の軸に沿って測定されます。
- システム障害にレジリエンスを持って対応する方法
- 高品質のコードを容易に提供できる方法
- 複雑性と技術的負債を適切に管理する方法
- ソフトウェアのリリースペースが予測可能である方法
- ユーザーの行動を適切に理解できる方法
OMMは、オブザーバビリティを採用している組織全体で気づいた定性的な傾向と、ソフトウェアエンジニアリングの専門家を対象とした調査から得られた定量的な分析を組み合わせたものです。本章で示した結論は、2020年と2021年に実施された調査研究を反映しています。 成熟度モデル自体は、オブザーバビリティの採用が広がるにつれて進化していくでしょう。
同様に、オブザーバビリティの実践も進化し、成熟への道のりは組織ごとに独自のものになるでしょう。しかし、本章は、組織が独自の実用的なアプローチを作成するための基礎を提供しています。
私自身、SREとしてオブザーバビリティの導入に携わった経験から、著者の主張に強く共感しました。当初は、オブザーバビリティの成熟度を測定することは難しいと感じていました。しかし、OMMを使って自社の能力を評価し、優先順位を付けることで、オブザーバビリティ文化を組織全体に広めるためのロードマップを作成することができたのです。
特に、「予測可能なペースでリリースする」能力の向上は、私たちのチームにとって大きな転機となりました。従来は、新機能のリリースが遅れがちで、お客様からのフィードバックを得るのに時間がかかっていました。オブザーバビリティを活用することで、リリースプロセスを可視化し、ボトルネックを特定して改善することができるようになったのです。 その結果、リリースペースが安定し、お客様満足度も向上しました。
Chapter 22. Where to Go from Here
「Chapter 22. Where to Go from Here」は、本書のまとめと今後のオブザーバビリティの展望について述べた、非常に示唆に富んだ一章でした。著者らは、オブザーバビリティの概念と実践が過去数年でどのように進化してきたかを振り返り、これからの方向性を予測しています。
オブザーバビリティの定義の進化
本章の冒頭で、著者らは本書の執筆に3年以上を要した理由を説明しています。その主な理由は、オブザーバビリティの状態が絶えず変化してきたことにあります。当初は、オブザーバビリティという用語自体を定義する必要があり、データのカーディナリティや次元といった概念も十分に理解されていませんでした。 また、オブザーバビリティとモニタリングが同義語として使われることも多く、その違いを説明するのに苦労したそうです。
しかし、今では多くの人がオブザーバビリティの基本概念を理解し、モニタリングとの違いも認識されるようになってきました。人々が求めているのは、より洗練された分析と、オブザーバビリティの実践を成功させるための具体的なガイダンスなのです。
本書の構成の変遷
また、本書の構成も当初の予定から大きく変化したと著者らは述べています。最初は、より基本的な内容を扱う短い章立てでしたが、一般的な懸念事項や成功パターンが明らかになるにつれ、より深く詳細な内容を追加していったのです。 さらに、大規模なオブザーバビリティの実践から学んだ教訓も取り入れています。
加えて、本書は競合他社に勤める人を含む複数のレビュアーとの共同作業の成果でもあります。著者らは、オブザーバビリティの最新の状態を包括的に反映するために、執筆プロセス全体を通して自らの見解を改訂し、幅広い視点を取り入れ、概念を再検討してきたのです。
オブザーバビリティ採用の社会技術的課題
読者からのフィードバックに基づき、著者らはオブザーバビリティの採用における社会技術的な課題についても追加しました。オブザーバビリティは、ツールを購入するだけでは実現できません。 それは、ソフトウェアの動作を理解する方法を変え、顧客との関係を変革する実践なのです。
追加のリソース
本章では、本書で扱えなかった重要なトピックを補完するための追加のリソースも紹介されています。SRE本、SLOの実装、OpenTelemetryの詳細など、オブザーバビリティに関連する様々な話題をカバーする書籍やブログが推奨されていました。
オブザーバビリティの未来予測
最後に、本書は今後のオブザーバビリティの展開について予測を示しています。2022年の発売で2年経過しているが概ねあっている。
OpenTelemetryとオブザーバビリティの融合:OTelは、アプリケーションのインストルメンテーションのデファクトスタンダードになり、オブザーバビリティと不可分のものになるでしょう。
フロントエンドアプリケーションへのオブザーバビリティの浸透:RUMや合成モニタリングに代わり、オブザーバビリティがフロントエンドのパフォーマンス理解とデバッグに使われるようになります。
自動インストルメンテーションの進化:OTelの自動インストルメンテーションは、ベンダー固有のライブラリに匹敵するレベルに達し、カスタムインストルメンテーションと組み合わせて使われるでしょう。
開発ワークフローの変革:オブザーバビリティは、コード変更が本番環境でユーザーにどう影響するかを理解するための不可欠なツールになります。それにより、開発者は迅速なフィードバックを得て、より良いソフトウェアを作れるようになるのです。
オブザーバビリティ実践の継続的な進化
著者らは、本書の結論として、オブザーバビリティが絶え間ない実践の進化であることを強調しています。 高カーディナリティと高次元のテレメトリデータを自在に分析し、コア分析ループを使って問題の根本原因を迅速に特定できるようになることが、オブザーバビリティの本質なのです。
そして、オブザーバビリティの実践は、技術の進歩とともに進化し続けるでしょう。本書が提示したのは、その進化の道筋を示す一つの地図に過ぎません。 実際の道のりは、それぞれの組織に固有のものになるはずです。
私自身、SREとしてオブザーバビリティの導入に携わってきた経験から、著者らの主張に強く共感しました。オブザーバビリティは、単なるツールの導入ではなく、ソフトウェアの信頼性を追求する終わりなき旅なのだと実感しています。 本章で得た洞察を糧に、その旅を続けていきたいと思います。
さいごに
本書『Observability Engineering』は、現代のソフトウェアシステムが直面する複雑性という難題に対し、オブザーバビリティという解決策を提示してくれる、極めて示唆に富んだ一冊でした。
オブザーバビリティは、単なるツールや技術の問題ではありません。それは、システムと向き合い、その内部を深く理解するための思想であり、文化なのです。オブザーバビリティの実践は、エンジニアリングチームの働き方を変え、組織のあり方そのものを変革していく営みなのだと、今までの経験と本書を通じて強く実感させられました。
著者らが繰り返し強調しているように、オブザーバビリティの旅に終わりはありません。技術は常に進化し、システムはますます複雑になっていきます。そうした中で、オブザーバビリティのベストプラクティスもまた、絶え間ない進化を求められるのです。
しかし、その本質は不変です。システムの真の姿を捉え、ユーザーに価値を届け続けること。それこそが、私たちソフトウェアエンジニアに課せられた使命なのだと、改めて思い知らされました。本書で得た学びを胸に、オブザーバビリティの実践を重ね、その輪を広げていくことが、私にできる重要な責務だと感じています。
最後に、本書の著者をはじめ、オブザーバビリティの発展に尽力されてきた方々に、心からの敬意と感謝を表します。皆さんの献身的な努力なくして、今日のオブザーバビリティの隆盛はありませんでした。皆さんが切り拓いてくださった道の上を、私もまた歩んでいくことを誓います。
そして、本ブログ読者の皆さまにも感謝を申し上げます。1つ1つの気づきや学びを積み重ねることが、私たち自身の成長につながるだけでなく、ひいては業界全体の発展にもつながるのだと信じています。引き続き、オブザーバビリティについて学び、実践し、議論を深めていければとおもいます。あと、この手のタイプの読書感想文は家でちまちま書くことでしか成立しないので生活が変わったらやめます。
みなさん、最後まで読んでくれて本当にありがとうございます。途中で挫折せずに付き合ってくれたことに感謝しています。
読者になってくれたら更に感謝です。Xまでフォロワーしてくれたら泣いているかもしれません。今週の金曜日が誕生日なので祝っていただけても嬉しいです。
参考資料
- Exponential Histogram?
- OpenTelemetryが気になってるけど実際に始めて「なるほどね」ってなるにはどうしたらいいかについて15分でまとめて喋ります
- OpenTelemetry を使ったトレースエグザンプラーの活用 / otel-trace-exemplar
- オブザーバビリティの Primary Signals
- On the general theory of control systems
- Why Intuitive Troubleshooting Has Stopped Working for You
- Control theory | wiki
- 制御理論 | wiki
- Scuba: Diving into Data at Facebook
- Choose Boring Technology
- Unicorn)
- State of DevOps 2019
- CNCF Cloud Native Definition v1.1
- Ep. #11, Chaos Engineering with Ana Medina of Gremlin
- Chaos Engineering Observability
- How Time Series Databases Work—and Where They Don't
- イベント(Event)の構造化データ
- Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
- Evolving Distributed Tracing at Uber Engineering
- Zipkin
- ServiceNow Cloud Observability
- Honeycomb
- AWS X-Ray and Step Functions
- OpenTelemetry | Documentation
- Waterfall chart
- 【OpenTelemetry】オブザーバビリティバックエンド8種食べ比べ
- tracingからAttributesを付与してmetricsを出力できるようにtracing-opentelemetryにPRを送った
- Accelerate
- The Staff Engineer's Path
- Test-driven development
- When Doing Wrong Feels So Right: Normalization of Deviance
- Tying These Principles Together
- Service Level Objectives
- Implementing Service Level Objectives
- Moving Past Shallow Incident Data
- Observability Maturity Community Research Findings Q1, 2020
- Observability Maturity Community Research Findings 2021
- Observability Survey 2023
- The State of Observability 2023
- OpenTelemetry (OTel) Is Key to Avoiding Vendor Lock-in
- ジョインしたチームのマイクロサービスたちを再計装した話 / Getting started tracing instrument micro service with OpenTelemetry
- OpenTelemetryのここ4年の流れ / OpenTelemetry in last 4+ years
- ペパボOpenTelemetry革命
- OpenTelemetry Collector 自身のモニタリング / Monitoring the OpenTelemetry Collector itself
- 5分でわかるGoの自動計装
- Building a ServiceMap with Service Graph Connector
- HoneycombとOpenTelemetryでオブザーバビリティに入門してみる
- 自家版semconvの夢
- サービスメッシュ環境における OpenTelemetry 活用 / OpenTelemetry in Service Mesh
- OpenTelemetry のサービスという概念について
- OpenTelemetry実践 はじめの一歩
- AWS Distro for OpenTelemetry (ADOT) の紹介
- 監視論Ⅳ ~監視からオブザーバビリティーへの招待~
- オブザーバビリティで理解するコンピュータサイエンス
- 監視論 ~SREと次世代MSP~