最強なデータ分析基盤は何か⁉︎多種多様なデータ分析基盤が、制約のない環境で競合した時… ビジネス用途に限らず、あらゆるシナリオで使用可能な「データ分析」で比較した時、最強なデータ分析基盤は何か⁉︎ 今現在最強のデータ分析基盤は決まっていない
データ分析基盤まとめ(随時更新) などもあり大変参考にさせていただきました。ありがとうございます。
はじめに
データエンジニアリングは、データの収集、処理、保存、そして提供を行う技術やプロセスを扱う複雑な分野です。この分野の全容を系統的に把握することは決して容易なことではありません。このような状況の中で、『Fundamentals of Data Engineering』という書籍に出会いました。この本は、著者たちの豊富な実務経験に基づいて書かれており、データエンジニアリングの基本概念とそのライフサイクルに焦点を当てています。さらに、これらの概念を現実の問題解決に応用する方法についても詳しく説明しています。全624ページに及ぶこの書籍は、その分厚さが示す通り、読破するには相当な時間と努力が必要ですが、その価値は十分にあると確信しています。
本書の特徴は、特定のツールや技術ではなく、データエンジニアリングの根幹をなす原則に焦点を当てている点です。著者らは、データ生成、ストレージ、取り込み、変換、提供といったライフサイクルの各段階を丁寧に解説し、それらを支える重要な概念を、具体的な技術選択やアーキテクチャ設計と関連付けて説明しています。また、クラウド技術を効果的に組み合わせて、下流のデータ消費者のニーズに応えるための方法論も提示しています。
本書は、データエンジニアリングの理論と実践を見事に融合させ、この分野の要諦を掴むための羅針盤となります。著者らの豊富な知見と経験が随所に活かされ、ベストプラクティスのフレームワークを用いた問題の評価方法、市場の誇大広告を見抜く視点、堅牢なアーキテクチャの設計・構築手法などが解説されています。これらの知識は、データエンジニアリングの要諦を理解し、実践に活かすために不可欠な要素です。
また、本書は、データエンジニアリングを取り巻く環境の変化についても言及しています。特に、クラウドファーストのアプローチを取ることで、オンプレミスからクラウドへのシフトを見据えた議論を展開しています。加えて、セキュリティとプライバシーの重要性についても強調しており、データエンジニアリングの現在と未来を見据えた内容となっています。
本書を通じて、データエンジニアリングの全体像を俯瞰し、実践的な知識を得ることができました。データエンジニアリングの原則を自らの役割に取り入れ、クラウド技術を駆使して問題解決に取り組む方法を学べた点は、特に有益でした。本書は、データエンジニアリングの要諦を掴むための一助となる、貴重な一冊であると言えます。本稿はそんな書籍の読書感想文である。あくまで、私の感想なので指摘はそれぞれのSNSに書き散らしてください。
『Fundamentals of Data Engineering』の構成
本書は4つのパートで構成されています。
パートIでは、第1章でデータエンジニアリングを定義し、第2章でデータエンジニアリングのライフサイクルを示します。第3章ではよいアーキテクチャについて議論し、第4章では適切な技術を選択するためのフレームワークを紹介します。
パートIIは、第2章を基にデータエンジニアリングのライフサイクルを深く掘り下げています。データ生成、ストレージ、取り込み、変換、提供の各段階が独立した章で扱われます。パートIIは本書の中核をなす部分であり、他の章はここで扱われる核心的なアイデアをサポートするために存在しています。
パートIIIでは、追加のトピックスとして、第10章でセキュリティとプライバシーについて議論しています。これらは常にデータエンジニアリングにおいて重要な部分でしたが、営利目的のハッキングや国家支援のサイバー攻撃の増加に伴い、さらに重要性が増しています。また、GDPRやCCPAなどの規制の出現により、個人データの不注意な取り扱いは重大な法的影響を及ぼす可能性があります。
第11章では、データエンジニアリングの近未来について、著者らの大胆な予測を概説しています。
付録では、データエンジニアリングの日々の実践に非常に関連性が高いものの、本文の主要部分には収まらなかった技術的トピックスを取り上げています。具体的には、シリアル化と圧縮(付録A)、クラウドネットワーキング(付録B)です。
- はじめに
- Part I. Foundation and Building Blocks
- Part II. The Data Engineering Lifecycle in Depth
- Part III. Security, Privacy, and the Future of Data Engineering
- さいごに
Part I. Foundation and Building Blocks
Chapter 1. Data Engineering Described
データエンジニアリングを「raw dataを取り込み、高品質で一貫性のある情報を生成するシステムとプロセスの開発、実装、維持」と定義しています。データエンジニアは、セキュリティ、データ管理、DataOps、データアーキテクチャ、オーケストレーション、ソフトウェアエンジニアリングの交差点に位置し、データのソースシステムから始まり、分析や機械学習などのユースケースにデータを提供するまでのライフサイクル全体を管理します。
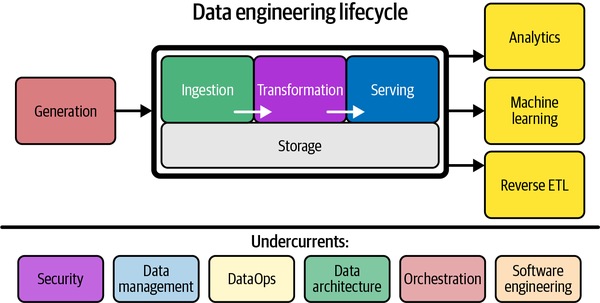
また、データエンジニアリングの歴史的な発展についても触れられており、データウェアハウジングから始まり、ビッグデータ時代を経て、現在はデータのライフサイクル全体を管理するフェーズに入っていることが分かります。データエンジニアは、データサイエンティストの上流に位置し、分析やモデリングに必要な基盤を提供する重要な役割を担っています。
さらに、本章では、企業のデータ成熟度に応じたデータエンジニアの役割の変化や、他の技術的役割(ソフトウェアエンジニア、データアーキテクト、DevOpsエンジニアなど)およびビジネスリーダーとの関わりについても説明されています。データエンジニアは、技術的スキルだけでなく、コミュニケーション能力やビジネス理解も求められる、組織内の重要な接点となる存在であることが強調されています。
本章を通じて、データエンジニアリングが急速に発展し、組織内で不可欠な役割を担うようになってきたことを実感しました。データドリブンな意思決定が求められる現代において、データエンジニアは、データの価値を最大限に引き出すための鍵を握っています。今後もデータエンジニアリングの動向に注目し、自身のスキルを磨いていく大切さを学びました。
Chapter 2. The Data Engineering Lifecycle
データエンジニアリングのライフサイクルについて詳細に解説されています。データエンジニアリングのライフサイクルとは、raw dataを有用な最終製品に変換するための一連のプロセスを指します。
本章では、データエンジニアリングのライフサイクルを5つのステージ(生成、ストレージ、取り込み、変換、提供)に分類し、各ステージの役割と考慮事項を丁寧に説明しています。また、ライフサイクル全体を支える重要な要素として、セキュリティ、データ管理、DataOps、データアーキテクチャ、オーケストレーション、ソフトウェアエンジニアリングの6つの「潮流」を紹介しています。
特に印象的だったのは、データ管理の重要性についての議論です。著者らは、データガバナンス、データモデリング、データの系統、データ統合、ライフサイクル管理など、企業のデータ管理における様々なベストプラクティスを紹介し、これらがデータエンジニアリングにどのように関連するかを明確に示しています。データエンジニアは、単なる技術者ではなく、組織全体のデータ活用を戦略的に促進する役割を担っているのだと実感しました。
また、DataOpsの概念も興味深かったです。DataOpsは、アジャイル開発、DevOps、統計的プロセス管理の手法をデータに適用したものであり、自動化、モニタリング、インシデント対応の3つの要素から成ります。データエンジニアリングにおいてDataOpsを実践することで、データ製品の迅速な開発と高品質な運用が可能になるとのことです。
本章を通じて、データエンジニアリングが、単なるデータ処理の技術にとどまらず、組織のデータ活用を支える総合的な取り組みであることを学びました。データエンジニアは、ライフサイクルの各ステージにおける技術的な選択と、セキュリティ、データ管理、アーキテクチャなどの戦略的な考慮事項のバランスを取ることが求められます。本書で提示されたデータエンジニアリングのライフサイクルのフレームワークは、この複雑な領域を体系的に理解するための強力なツールになると感じました。
Chapter 3. Designing Good Data Architecture
データエンジニアリングにおける良いアーキテクチャ設計について詳細に解説されています。
本章では、まず、データアーキテクチャを「企業のデータニーズの進化を支えるシステムの設計であり、柔軟で可逆的な意思決定により、トレードオフを慎重に評価して達成されるもの」と定義しています。そして、良いデータアーキテクチャの原則として、共通コンポーネントの賢明な選択、障害への対策、スケーラビリティの確保、リーダーシップ、継続的なアーキテクト活動、疎結合システムの構築、可逆的な意思決定、セキュリティの優先、FinOpsの採用の9つを挙げています。
また、本章では、分散システム、スケーラビリティ、障害対策、密結合と疎結合、シングルテナントとマルチテナント、イベント駆動アーキテクチャ、ブラウンフィールドとグリーンフィールドプロジェクトなど、データアーキテクチャ設計に関連する主要な概念について説明しています。
さらに、データウェアハウス、データレイク、モダンデータスタック、ラムダアーキテクチャ、カッパアーキテクチャ、IoTアーキテクチャ、データメッシュなど、具体的なデータアーキテクチャの例や種類についても紹介されています。これらの例を通じて、データエンジニアがビジネスの要件に合わせて適切なアーキテクチャを選択し、設計するための知見が提供されています。
本章を読んで、データアーキテクチャ設計の重要性と複雑さを改めて認識しました。データエンジニアは、技術的な知識だけでなく、ビジネスの文脈を理解し、ステークホルダーとのコミュニケーションを通じて要件を把握する必要があります。そして、セキュリティ、データ管理、アーキテクチャなどの戦略的な考慮事項とのバランスを取りながら、柔軟で進化可能なアーキテクチャを設計していかなければなりません。この辺はソフトウェアアーキテクチャの基礎を思い出した。

本書で提示された良いデータアーキテクチャの原則や、様々なアーキテクチャパターンの知識は、この難しい課題に取り組むための強力な助けになると感じました。データエンジニアとして、これらの知見を活かし、組織のデータニーズに合ったアーキテクチャを設計していきたいと思います。詳細に知りたい場合には『データ指向アプリケーションデザイン』あたりを読むと良さそう

Chapter 4. Choosing Technologies Across the Data Engineering Lifecycle
データエンジニアリングのライフサイクル全体にわたる適切な技術選択のための考え方と基準について詳細に説明されています。
この章では、アーキテクチャが戦略的な設計であることに対し、ツールはその実現を目指す戦術的な選択肢であるという点が強調されています。 技術選択時に考慮すべき要素として、チームの規模と能力、市場投入までのスピード、相互運用性、コスト最適化とビジネス価値、技術トレンドの変化、デプロイ環境、ビルドかバイの選択、モノリシックかモジュール化か、サーバーレスかサーバーか、性能最適化などが挙げられています。あまりにも「ソフトウェアアーキテクチャの基礎」すぎてデータ基盤もソフトウェアアーキテクチャなのだと分からせをくらいました。
加えて、クラウドのコスト効率とクラウドネイティブアーキテクチャのコスト最適化の重要性が説明されており、オンプレミス、クラウド、ハイブリッドクラウド、マルチクラウドなどの配置オプションとその特性についても詳述されています。
オープンソースソフトウェア(コミュニティ型と商用型)とプロプライエタリーソフトウェアの選択、モノリシックとマイクロサービスアーキテクチャの比較、サーバーレスと従来型サーバーの検討など、具体的な技術選択のシナリオにおける検討が提示されています。
技術選択の複雑さとその重要性を理解する上で、この章は大いに役立ちます。データの世界は常に進化しているため、最適な選択肢は状況に応じて変わります。適切なトレードオフを評価し、柔軟かつ可逆的な意思決定を行うことが重要です。この辺はソフトウェアアーキテクチャメトリクスみがあって良かった。

セキュリティ、データ管理、DataOps、オーケストレーションなどの現代のトレンドが技術選択に与える影響も大きいことが認識されています。これらを総合的に考慮し、ビジネス価値を最大化する技術スタックを構築することが、SREとしての責任であると捉えられます。
本章で提供される原則とガイドラインは、DXの推進と共に増大する複雑な意思決定の指針となります。組織のニーズに沿いながら、これらの洞察を活用していくことが推奨されています。
Part II. The Data Engineering Lifecycle in Depth
Chapter 5. Data Generation in Source Systems
本章では、データエンジニアリングのライフサイクルの初期段階であるソースシステムにおけるデータの生成プロセスについての詳細な解説が展開されています。 ここで、データエンジニアがソースシステムからのデータの特性と生成プロセスを理解することの重要性が強調されており、これは非常に重要な点です。
特に印象深かったのは、ソースシステムのオーナーやステークホルダーとの関係構築の必要性です。データエンジニアリングはチーム単独ではなく、関係者全員の協力が必須であり、上流システムで問題が生じた際に迅速な対応が可能な信頼関係の構築が不可欠です。
データ品質の維持に関する言及もあり、これは特に重要です。ソースシステムの設計や運用に直接影響を与えることは困難かもしれませんが、期待されるデータ品質について上流チームと合意を形成し、定期的な品質チェックを行うことが必要です。これは、SREとしての役割とも重なる側面があります。
セキュリティ、可用性、信頼性を考慮したソースシステムのアーキテクチャへの理解も、障害発生時に影響を最小限に抑え、迅速に復旧する設計を実現する上で重要です。
さらに、データ管理、DataOps、オーケストレーションといったデータエンジニアリングの新しい動向とソースシステムとの関連性についても触れられており、これらの原則を上流工程に適用し、エンド・ツー・エンドでの高品質なデータパイプライン構築が目標です。
リバースETLやイベントストリーミングプラットフォームの活用による、データエンジニアとソースシステムとの連携強化の可能性についての言及もあり、これはアプリケーション開発チームとのWin-Winの関係構築、及びユーザー向けデータ製品の共創へと繋がるでしょう。
本章を通じて、SREとデータエンジニアの役割が密接に関連しており、両者の協力が不可欠であることが明確になりました。 上流から下流への一貫した高品質なデータフローを実現するためには、両分野の専門知識を統合し、継続的な改善を図る必要があります。得られた知見を活用し、開発チームと協力しながら、より堅牢なデータインフラを構築していくことが目指されています。
Chapter 6. Storage
データエンジニアリングのライフサイクルにおけるストレージの重要性と、その設計・運用に関する考慮事項について詳しく解説されています。
本章では、まず、ハードディスク、SSD、システムメモリなど、ストレージシステムを構成する基本的な要素について説明しています。データエンジニアは、これらの物理的ストレージコンポーネントの特性を理解することで、パフォーマンス、耐久性、コストのトレードオフを適切に評価できるようになります。
次に、ファイルストレージ、ブロックストレージ、オブジェクトストレージ、ストリーミングストレージなど、主要なストレージシステムの種類と特徴を紹介しています。特に、クラウドにおけるオブジェクトストレージの重要性が強調されており、その柔軟性とスケーラビリティが、データレイクやクラウドデータウェアハウスの基盤となっていることが分かります。
さらに、データウェアハウス、データレイク、データレイクハウス、データプラットフォームなど、データエンジニアリングで用いられる主要なストレージの抽象化についても言及されています。これらの抽象化は、ストレージシステムの上に構築され、データの取り込み、変換、提供といったライフサイクルの各段階をサポートします。
本章では、ストレージに関する重要なトレンドや考え方についても触れられています。例えば、コンピュートとストレージの分離、ゼロコピークローニング、データカタログ、データ共有などは、現代のデータアーキテクチャにおいて欠かせない要素だと指摘されています。
また、データのライフサイクルと保持期間の管理、シングルテナントとマルチテナントのストレージ設計の違いなど、運用面での考慮事項についても説明されています。データエンジニアは、これらの要素を総合的に判断し、組織のニーズに合ったストレージ戦略を立てる必要があります。
本章を通じて、ストレージがデータエンジニアリングのあらゆる段階で重要な役割を果たしていることを再認識しました。生のデータを価値あるインサイトに変えるためには、適切なストレージの選択と設計が不可欠です。また、セキュリティ、データ管理、DataOps、オーケストレーションなどの「潮流」を常に意識しながら、ストレージシステムを進化させていく必要があります。
本書で得られた知見を活かし、自社のデータアーキテクチャにおけるストレージの最適化に取り組んでいきたいと思います。特に、コストとパフォーマンスのバランスを取りつつ、将来の拡張性も考慮した設計を心がけたいと考えています。ストレージの話は『パタ&へネ』などを読むとしっかりと分かるので読み直す機会があれば読み返したい。しかし、人生の時間は有限なので悲しい。


Chapter 7. Ingestion
データエンジニアリングにおけるデータ取り込みの重要性と複雑さを再認識しました。
本章では、データ取り込みを「データを一つの場所から別の場所へ移動するプロセス」と定義しています。その主要な考慮事項として、ユースケース、再利用性、データ量、データフォーマット、データ品質などが挙げられています。さらに、バッチ処理とストリーミング処理の違い、同期型と非同期型のデータ取り込み、シリアル化とデシリアル化、スループットとスケーラビリティといった、設計上の重要な概念について詳しく説明されています。また、Otelなどのオブザーバビリティ情報の取得については言及されていないのですが、この章を通じて現代の監視基盤が実際にはデータエンジニアリングに大きく依存してるものなのだと思いはじめました。
特に印象的だったのは、データ取り込みの方法の多様性です。データベースへの直接接続、CDC、API、メッセージキュー、ファイルエクスポートなど、様々な手段があり、それぞれにメリットとデメリットがあります。状況に応じて適切な方法を選択し、組み合わせることが求められます。
また、データ取り込みにおけるデータ品質の確保の重要性も強調されていました。スキーマの変更や遅延データへの対応、エラーハンドリングなど、様々な課題に直面します。上流のシステムとの緊密なコミュニケーションと、ロバストなモニタリングの仕組みが不可欠だと感じました。
本章では、データ取り込みに関わる様々なステークホルダーとの協力についても言及されています。特にソフトウェアエンジニアとのコラボレーションは、データ品質の向上と、よりリアルタイムなデータ活用につながる可能性があります。組織のサイロを超えて、Win-Winの関係を築いていくことが重要だと分かりました。
さらに、セキュリティ、データ管理、DataOps、オーケストレーション、ソフトウェアエンジニアリングといった「潮流」が、データ取り込みにどのように影響するかについても議論されていました。これらの原則を常に意識しながら、エンドツーエンドのデータパイプラインを設計していく必要があります。
データ取り込みは、地味な作業に見えるかもしれません。しかし、それは分析やMLなどのエキサイティングなアプリケーションを支える重要な基盤です。本章で得られた知見を活かし、より信頼性が高く、価値あるデータを提供できるよう、日々精進していきたいと思います。
Chapter 8. Queries, Modeling, and Transformation
データエンジニアリングにおけるクエリ、モデリング、変換の重要性と技術的な考慮事項について理解を深めることができました。
本章では、まず、クエリの仕組みと最適化の手法について解説されています。クエリオプティマイザの役割や、結合戦略の最適化、説明プランの活用など、パフォーマンス向上のための具体的なアドバイスが提示されており、大変参考になりました。また、ストリーミングデータに対するクエリの特殊性についても言及されていました。
次に、データモデリングの重要性と主要な手法が紹介されています。概念モデル、論理モデル、物理モデルの違いや、正規化、スター・スキーマ、Data Vaultなどのバッチデータのモデリング手法、ストリーミングデータのモデリングの考え方など、幅広いトピックがカバーされています。ビジネスロジックをデータモデルに反映させることの重要性が強調されていました。
そして、変換の役割と主要なパターンについて解説されています。単純なクエリとは異なり、変換では結果を永続化し、ダウンストリームで利用できるようにすることが目的だと説明されています。バッチ処理とストリーミング処理それぞれの変換パターンや、更新パターン、データラングリングなどの具体的な手法が紹介されていました。
また、マテリアライズドビュー、フェデレーションクエリ、データ仮想化など、クエリ結果を仮想的なテーブルとして提示する手法についても言及されていました。これらの手法は、複雑なデータパイプラインの一部として活用できる可能性があります。
本章では、クエリ、モデリング、変換に関わる様々なステークホルダーとの協力についても議論されています。ビジネスロジックを理解し、上流のシステムへの影響を最小限に抑えつつ、下流のユーザーにとって価値のあるデータを提供することが求められます。また、セキュリティ、データ管理、DataOps、オーケストレーション、ソフトウェアエンジニアリングといった「潮流」が、この段階でも重要な役割を果たすことが指摘されていました。
データ変換は、データパイプラインの中核をなす工程です。単に最新の技術を追求するのではなく、ステークホルダーにとっての価値を常に意識することが重要だと感じました。本章で得られた知見を活かし、ビジネスの目標達成に貢献できるデータ変換プロセスを設計していきたいと思います。
Chapter 9. Serving Data for Analytics, Machine Learning, and Reverse ETL
本章では、データエンジニアリングのライフサイクルの最終段階である、データの提供について解説されていた。データエンジニアが直面する主要な3つのユースケース - 分析、機械学習、リバースETLについて、どのようにデータを提供するかが述べられていた。
データを提供する際の重要な考慮点として、エンドユーザーがデータを信頼できるようにすることが何より大切だと強調されていた。データへの信頼がないと、いくら高度なアーキテクチャやシステムを構築しても意味がない。信頼を得るためには、データの検証とオブザーバビリティのプロセスを活用し、ステークホルダーと協力してデータの有効性を確認する必要がある。
また、ユースケースとユーザーを理解し、提供するデータプロダクトを明確にし、セルフサービスかどうかを検討し、データの定義やロジックを確立することが重要だと述べられている。データメッシュのコンセプトにも触れられ、データ提供の方法が大きく変化しつつあることがわかった。
分析や機械学習のためのデータ提供方法としては、ファイル、データベース、クエリエンジン、データ共有などがあげられていた。セマンティック層やメトリクス層の活用も有効とのことだった。また、ノートブックを使ったデータサイエンスのワークフローについても解説があり参考になった。
リバースETLは、処理されたデータをOLAPシステムからソースシステムにロードすることだが、フィードバックループを作り出すリスクがあるので注意が必要だと指摘されていた。
本章を読んで、データ提供において信頼性とセキュリティが非常に重要であり、様々な方法や最新のトレンドを理解しておく必要性を感じた。生のデータを渡すのではなく、匿名化などの工夫も必要だ。データプロダクトを通じてビジネスに貢献するという視点を常に持ちながら、品質の高いデータを提供できるよう、日々研鑽していきたい。
Part III. Security, Privacy, and the Future of Data Engineering
Chapter 10. Security and Privacy
セキュリティとプライバシーは、データエンジニアリングにおいて非常に重要な側面であり、後回しにしてはならないということが本章で強調されていました。データ漏洩や流出は、企業に壊滅的な結果をもたらす可能性があります。
GDPR、FERPA、HIPAAなど、データプライバシーに関する法的要件が増えており、違反すると多額の罰金が科せられる可能性があります。データエンジニアは、このような法規制を理解し、遵守する必要があります。
セキュリティの最大の弱点は人間であるため、データエンジニアは常に防御的な姿勢で行動し、認証情報の扱いには細心の注意を払い、倫理的な懸念があれば提起しなければなりません。セキュリティプロセスはシンプルで習慣的なものでなければならず、単なるコンプライアンスのためのセキュリティ・シアターであってはいけません。
最小権限の原則を適用し、必要最小限のアクセス権のみを付与すべきです。きめ細かいアクセス制御を実装することが重要です。クラウドにおけるセキュリティは、プロバイダーとユーザーの共同責任であり、ユーザー側の設定ミスが原因で流出が起こることが多いのです。
定期的なデータバックアップは、災害復旧やランサムウェア対策に欠かせません。リストアのテストも定期的に行うべきでしょう。技術面では、脆弱性を修正するためのシステムのパッチ適用と更新、保存中と通信中の両方でのデータの暗号化、アクセス・リソース・コストのログ記録・監視・アラート、ネットワークアクセスの厳重な制御、CPUなどの低レベルでのセキュリティ考慮などが重要な実践項目として挙げられていました。
すべてのエンジニアが自分の領域で潜在的なセキュリティ問題を探し出すという能動的な姿勢が重要であり、軽減策を積極的に展開すべきだと述べられています。
本章を通して、セキュリティとプライバシーは企業文化・プロセス・技術のすみずみまで浸透させる必要があり、関係者全員が常に警戒心を持ち、積極的な対策を講じることが機密データ資産を守るために不可欠だということを実感しました。法的にも評判的にも、その重要性は非常に高いのです。データエンジニアとして、**セキュリティとプライバシーを常に最優先事項と位置づけ、ベストプラクティスを実践していきます。
Chapter 11. The Future of Data Engineering
本章では、データエンジニアリングの将来について著者の考察が述べられていました。データエンジニアリングの分野は急速に変化しているため、本書の執筆は挑戦的な作業だったと思います。しかし、変化の中にも不変の本質を見出し、ライフサイクルという形で体系化したことは意義深いと感じました。
著者は、データエンジニアリングのライフサイクルは今後も変わらず重要であり続けると予測しています。一方で、ツールの簡素化が進み、より高度な作業にフォーカスできるようになるでしょう。クラウドスケールの「データOS」の出現によって、相互運用性が向上することも期待されます。
また、従来の「モダンデータスタック」を超えて、リアルタイムのデータ処理と機械学習を融合させた「ライブデータスタック」へと進化するとの展望も示されていました。ストリーミングパイプラインとリアルタイム分析データベースの発展によって、アプリケーションとデータ、機械学習の間のフィードバックループが短くなり、より洗練されたユーザー体験が実現するというビジョンは興味深いです。
一方で意外だったのは、スプレッドシートの重要性への言及でした。確かに、現場ではExcelが分析ツールとして依然大きな役割を果たしています。クラウドのOLAPシステムとスプレッドシートの使い勝手を兼ね備えた新しいツールの登場にも注目したいと思います。
全体を通して、技術トレンドは複雑な技術と文化の相互作用の中で生まれるものであり、予測は難しいというのが著者の率直な見解だと感じました。私たち一人一人がデータエンジニアリングの発展に関わっていく中で、ツールの採用と活用を通じて、ビジネス価値の創出という大きな目標を見失わないようにしたいと思います。
本書で得た知見をもとに、コミュニティに参加し、専門家と対話しながら、自分なりの探求を続けていきたいと思います。データエンジニアリングは奥深く、やりがいのある分野だと改めて感じました。
さいごに
この本を通じて、私はデータエンジニアリングの幅広さと深さを理解する機会を得ました。『Fundamentals of Data Engineering』は、データエンジニアリングの基礎から応用に至るまで、その様々な側面を包括的に解説しており、データエンジニアとしての技術や知識の向上に寄与する貴重なリソースです。データライフサイクルの各段階に対する詳細な説明は、実務で直面するさまざまな問題への理解を深めるのに非常に有用です。
また、セキュリティとプライバシーの章では、技術の理解だけでなく、倫理的な視点から物事を考えることの重要性が強調されていることが特に印象的でした。データエンジニアは技術者であると同時に、データを取り扱う上での社会的責任を有する存在であり、この点を再確認させられます。
データエンジニアリングの将来に関する展望を含めて、この書籍は、データエンジニアリングの現状理解と将来に向けた方向性を示す貴重な指南書です。技術の進歩は早く、今日学んだことが明日には旧式になる可能性がありますが、本書で得られる原則や考え方は、変わることのない有用な知識。データエンジニアリングの基盤となります。
最後に、この本を読むことで得られる最大の利点は、データエンジニアリングに対する深い理解と共に、学び続け、成長し続けることの重要性を再認識できることです。技術変遷に適応しつつ、データエンジニアリングの核心を見失わないよう努めることが、私たちには求められています。この旅は続きますが、『Fundamentals of Data Engineering』は、その道中で頼りになる羅針盤となるでしょう。
日本語訳の出版が待ち遠しいですね。そして、付録「A. Serialization And Compression Technical Details」と「B. Cloud Networking」に関しては、ぜひ自身で読んでみていただきたいです。これらのセクションは、データエンジニアリングの深い理解に不可欠なテクニカルな洞察を提供しており、実務での適用に役立つ知見が満載です。
")
(追記)
翻訳版のリリースが出ました。翻訳作業お疲れ様でした。
