はじめに
前回の続きで第四部のV. Delivering Infrastructure (インフラストラクチャの提供)という部の読書感想文になります。
前回の記事
書籍のリンク
")
第五部 目次
V. Delivering Infrastructure (インフラストラクチャの提供)
18. Organizing Infrastructure Code (インフラストラクチャコードの整理)
- インフラストラクチャコードを整理し管理する方法について論じます。
19. Delivering Infrastructure Code (インフラストラクチャコードのデリバリー)
- インフラストラクチャコードを効果的に提供する戦略について解説します。
20. Team Workflows (チームワークフロー)
- チームがインフラストラクチャコードを管理し作業するためのワークフローについて紹介します。
21. Safely Changing Infrastructure (インフラストラクチャの安全な変更)
- インフラストラクチャを安全に変更するための実践的なアドバイスを提供します。
V. Delivering Infrastructure (インフラストラクチャの提供)
18. Organizing Infrastructure Code (インフラストラクチャコードの整理)
この章では、スタック定義、サーバー設定、モジュール、ライブラリ、テスト、設定、ユーティリティなど、さまざまな種類のコードが含まれる可能性があります。これらのコードをプロジェクト間およびリポジトリ内でどのように整理するか、またインフラストラクチャコードとアプリケーションコードを一緒に管理するべきか、分けるべきかという問題が提起されています。これには、複数部分からなるエステートのコードをどのように整理するかという課題も含まれます。
Organizing Projects and Repositories
このセクションでは、プロジェクトがシステムの個別のコンポーネントを構築するために使用されるコードの集まりであると説明されています。プロジェクトやそのコンポーネントがどれだけ含むべきかについての硬いルールはありません。プロジェクト間の依存関係と境界は、プロジェクトコードの整理方法に明確に反映されるべきです。コンウェイの法則によれば、組織の構造とそれが構築するシステムの間には直接的な関係があります。チーム構造とシステムの所有権、およびそれらのシステムを定義するコードの不整合は、摩擦と非効率を生み出します。
One Repository, or Many?
複数のプロジェクトを持つ場合、それらを単一のリポジトリに入れるべきか、複数のリポジトリに分散させるべきかという問題があります。コードを同じリポジトリに保持すると、バージョン管理やブランチ化が一緒に行えるため、いくつかのプロジェクト統合およびデリバリー戦略を簡素化します。
One Repository for Everything
すべてのコードを単一のリポジトリで管理する戦略は、ビルド時のプロジェクト統合パターンでうまく機能します。この戦略では、リポジトリ内のすべてのプロジェクトを一緒にビルドしますが、アプリケーションパッケージ、インフラストラクチャスタック、サーバーイメージなど、複数の成果物を生み出すことがあります。
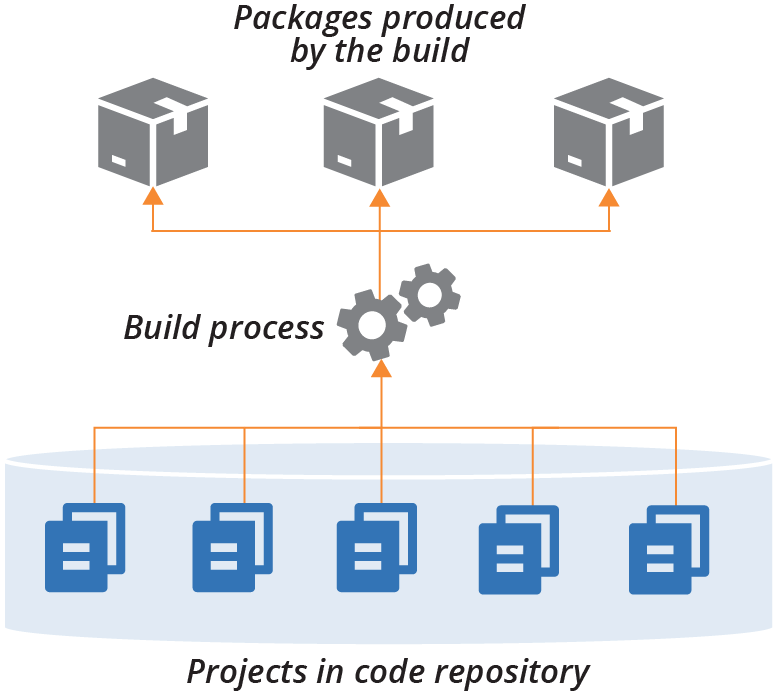 Figure 18-1. Building all projects in a repository together
Figure 18-1. Building all projects in a repository together
A Separate Repository for Each Project (Microrepo)
各プロジェクトごとに別のリポジトリを持つ戦略は、プロジェクト間のクリーンな分離を保証します。特に、各プロジェクトを別々にビルドしてテストするパイプラインを持つ場合に効果的です。
Multiple Repositories with Multiple Projects
一つのリポジトリですべてを管理する極端な戦略と、各プロジェクトごとに別のリポジトリを持つ極端な戦略の間で、多くの組織は複数のリポジトリを持ち、複数のプロジェクトを含む方法を採用しています。
Organizing Different Types of Code
異なるタイプのコードを整理する戦略を持つことは、コードベースを維持可能にするのに役立ちます。例えば、スタックのプロジェクトレイアウトは、インフラストラクチャスタックコード、テストコード、設定ファイル、デリバリー設定などを含む可能性があります。
Delivering Infrastructure and Applications
アプリケーションとインフラストラクチャのコードを一緒に管理するか、別々にするかという選択は、組織の構造と所有権の分割に依存します。アプリケーションチームがインフラストラクチャに関する責任を持つ場合、コードを分けることは認知的な障壁を生み出す可能性があります。
システムのインフラストラクチャのアーキテクチャ、品質、および管理をコードベースから導くという概念を持っています。したがって、コードベースはビジネス要件とシステムアーキテクチャに応じて構築され、管理される必要があります。それはまた、チームが効果的であるためのエンジニアリング原則と実践をサポートする必要があります。
19. Delivering Infrastructure Code (インフラストラクチャコードのデリバリー)
インフラストラクチャコードのデリバリーについての章では、ソフトウェアのデリバリーライフサイクルが重要なコンセプトとして強調されています。しかし、インフラストラクチャのデリバリーは、しばしば異なるタイプのプロセスに従います。例えば、本番環境でテストされないハードウェアの変更が一般的です。
しかし、コードを使ってインフラストラクチャを定義することで、より包括的なプロセスで変更を管理する機会が生まれます。例えば、サーバーのRAMを変更するような手動で構築されたシステムへの変更を開発環境で複製することは、ばかげているように思えるかもしれません。しかし、コードで実装された変更は、パイプラインを通じて本番環境へ簡単に展開することができます。
Delivering Infrastructure Code
パイプラインのメタファーは、インフラストラクチャコードの変更が開発者から本番インスタンスへ進む方法を説明しています。このデリバリープロセスに必要なアクティビティは、コードベースの整理方法に影響を与えます。
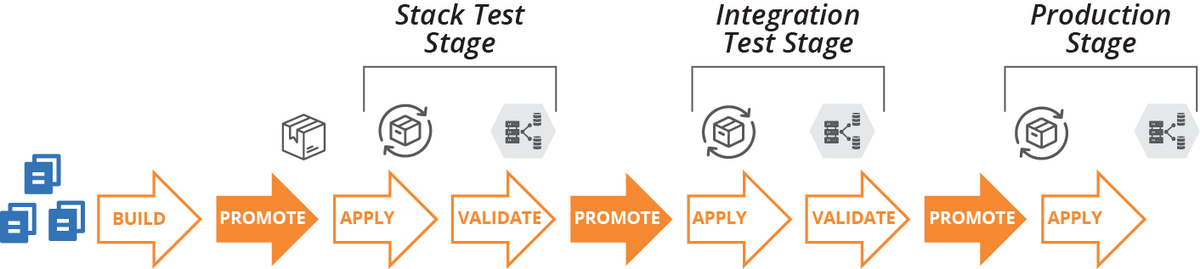 Figure 19-1. Infrastructure code project delivery phases
Figure 19-1. Infrastructure code project delivery phases
Building an Infrastructure Project
インフラストラクチャプロジェクトのビルドは、コードを使用するための準備を行います。これには、ライブラリの取得、ビルド時の設定の解決、コードのコンパイルまたは変換、テストの実行、ツールが適用するためのフォーマットでコードを準備することなどが含まれます。
Packaging Infrastructure Code as an Artifact
一部のツールでは、「コードの使用準備」は特定のフォーマットのパッケージファイルにファイルを組み立てることを意味します。これは、Ruby(gems)、JavaScript(NPM)、Python(pipインストーラーを使用するPythonパッケージ)などの一般的なプログラミング言語で一般的なプロセスです。
Using a Repository to Deliver Infrastructure Code
チームはソースコードリポジトリを使用して、インフラストラクチャソースコードの変更を保存し、管理します。多くのチームは、環境やインスタンスにデリバリーする準備ができたコードを保存するために、別のリポジトリを使用します。
 Figure 19-2. Build stage publishes code to the delivery repository
Figure 19-2. Build stage publishes code to the delivery repository
Integrating Projects
「Organizing Projects and Repositories」で述べたように、コードベース内のプロジェクト間には通常、依存関係があります。次に、互いに依存するプロジェクトの異なるバージョンをいつ、どのように組み合わせるかという問題があります。
Pattern: Build-Time Project Integration
ビルド時のプロジェクト統合パターンは、複数のプロジェクトをまたいでビルドアクティビティを実行します。これには、それらの依存関係を統合し、プロジェクト間のコードバージョンを設定することが含まれます。
Pattern: Delivery-Time Project Integration
デリバリー時のプロジェクト統合パターンは、それぞれのプロジェクトを個別にビルドおよびテストした後で組み合わせます。このアプローチでは、ビルド時の統合よりも後の段階でコードのバージョンを統合します。
Pattern: Apply-Time Project Integration
適用時のプロジェクト統合は、複数のプロジェクトを別々にデリバリーステージを進めることを含みます。プロジェクトのコードに変更が加えられたとき、パイプラインはそのプロジェクトの更新されたコードをそのプロジェクトのデリバリーパスの各環境に適用します。
Using Scripts to Wrap Infrastructure Tools
多くのチームは、インフラストラクチャツールをオーケストレーションし、実行するためにカスタムスクリプトを作成します。これには、Make、Rake、Gradleなどのソフトウェアビルドツールを使用する場合や、Bash、Python、PowerShellでスクリプトを書く場合があります。多くの場合、このサポートコードはインフラストラクチャを定義するコードと同じくらい、またはそれ以上に複雑になり、チームはそのデバッグと維持に多くの時間を費やすことになります。
確実で信頼性の高いインフラストラクチャコードのデリバリープロセスを作成することは、4つの主要なメトリクスに対して良好なパフォーマンスを達成するための鍵です。あなたのデリバリーシステムは、システムへの変更を迅速かつ信頼性高くデリバリーすることの実際の実装です。Only build packages once. を参考にしてください。
20. Team Workflows (チームワークフロー)
IaCを利用することによる作業方法の根本的な変化に焦点を当てています。従来のアプローチとは異なり、仮想サーバーやネットワーク構成の変更をコマンド入力やライブ設定の直接編集ではなく、コードの記述と自動化システムによる適用を通じて行います。これは新しいツールやスキルの習得を超えた変化であり、インフラストラクチャを設計、構築、管理する全ての人々の働き方に影響を与えます。
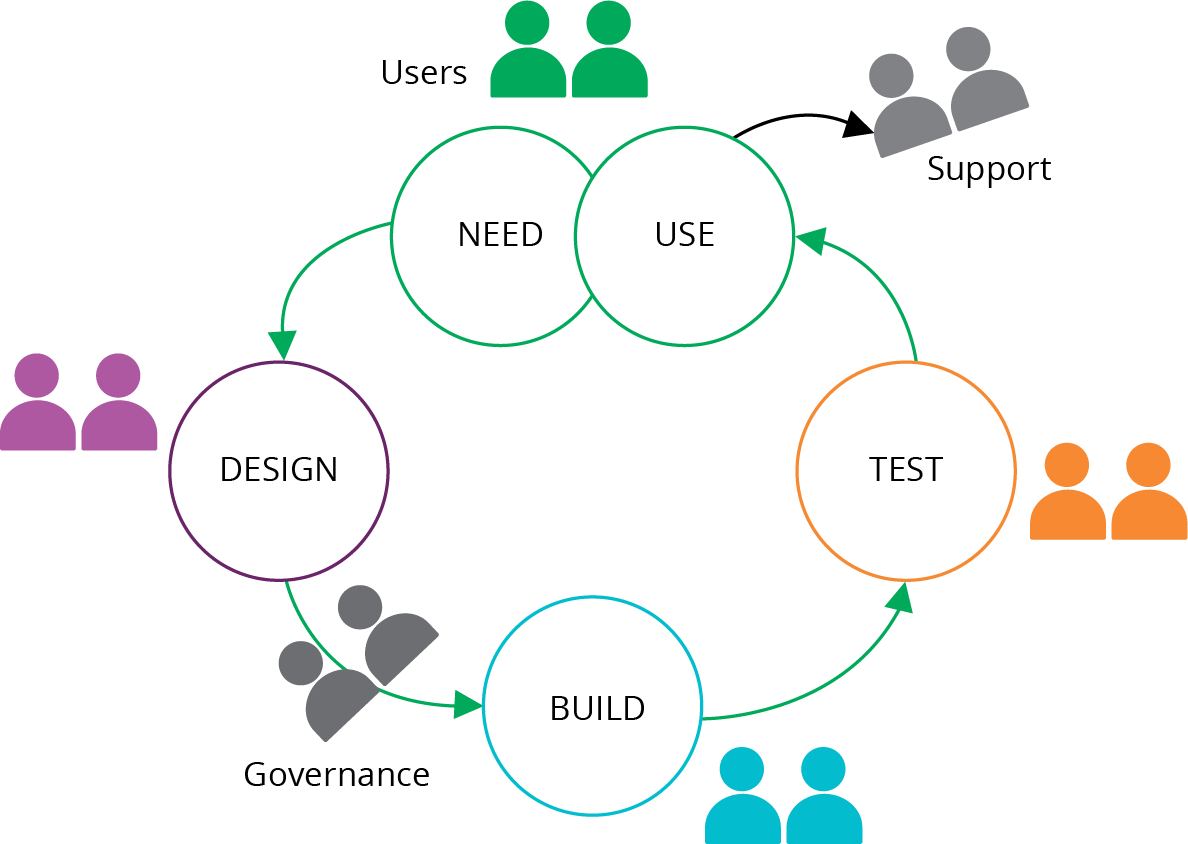 Figure 20-1. A classic mapping of a dedicated team to each part of a workflow
Figure 20-1. A classic mapping of a dedicated team to each part of a workflow
The People
信頼できる自動化ITシステムでは、人々が重要な役割を果たします。コード変更を本番システムに反映させるためには、テスト結果のレビューやボタンの操作以外に、人の手は必要ありませんが、システムの継続的な構築、修正、適応、改善には人間が不可欠です。
Who Writes Infrastructure Code?
組織によってインフラストラクチャコードを誰が書くかという問いに対する答えは異なります。伝統的なプロセスとチーム構造を維持しようとする組織では、インフラストラクチャを構築(およびサポート)するチームがインフラストラクチャ・アズ・コードのツールを使用して作業を最適化します。また、多くの組織ではアプリケーションチームが自分たちのアプリケーションに必要なインフラストラクチャを定義しています。
Applying Code to Infrastructure
インフラストラクチャへのコード適用に関する一般的なワークフローは、共有ソースリポジトリ内のコードから始まります。チームメンバーは最新バージョンのコードを自分の作業環境にプルし、編集した後、ソースリポジトリにプッシュして新しいバージョンのコードを様々な環境に適用します。
Applying Code from Your Local Workstation
ローカルワークステーションからインフラストラクチャコードを適用することは、他の誰も使用していないインフラストラクチャのテストインスタンスに対しては有用です。しかし、ローカル作業環境からツールを実行すると、共有インフラストラクチャインスタンスに問題を引き起こす可能性があります。
Applying Code from a Centralized Service
インフラストラクチャコードをインスタンスに適用するために、中央集権的なサービスを使用できます。このサービスはソースコードリポジトリまたはアーティファクトリポジトリからコードをプルし、インフラストラクチャに適用します。
Personal Infrastructure Instances
理想的には、共有リポジトリにプッシュする前にコード変更をテストできる方法があります。これにより、変更が期待通りの動作をするかどうかを確認でき、パイプラインがオンラインテストステージまでコードを実行するのを待つよりも高速です。
Source Code Branches in Workflows
ソースリポジトリのブランチは、コードベースの異なるコピー(ブランチ)で作業を行い、準備ができたら統合する際に役立ちます。Martin Fowlerの記事「Patterns for Managing Source Code Branches」には、チームのワークフローの一部としてブランチを使用する様々な戦略やパターンが説明されています。
Preventing Configuration Drift
設定のドリフトを防ぐために、ワークフローにおいていくつかの対策を講じることができます。これには、自動化の遅れを最小限に抑える、アドホックな適用を避ける、コードを継続的に適用する、不変のインフラストラクチャを使用するなどが含まれます。
Governance in a Pipeline-based Workflow
パイプラインベースのワークフローにおけるガバナンスでは、責任の再配置、左へのシフト、インフラストラクチャ・アズ・コードのガバナンスを持つ例示プロセスなどが議論されます。
インフラストラクチャをコードとして定義する組織では、人々は日々のルーチン活動やゲートキーパーとしての作業に費やす時間が減り、システム自体の改善能力を向上させるためにより多くの時間を費やすことになるはずです。彼らの努力は、ソフトウェアのデプロイおよび運用パフォーマンスの4つの指標に反映されます。
21. Safely Changing Infrastructure (インフラストラクチャの安全な変更)
Chapter 21: Safely Changing Infrastructure
21. Safely Changing Infrastructure
本章では、インフラの迅速かつ頻繁な変更の重要性に焦点を当てています。私のSREとしての経験では、速さと安定性は相補的な要素であることが多くのプロジェクトで証明されています。特に、インフラストラクチャー・アズ・コード(IaC)の実践において、このアプローチは効率と品質を大幅に向上させることができます。変更の頻度を上げることで、小さな問題を迅速に検出し、修正することが可能になります。
Reduce the Scope of Change
小さな変更の範囲を制限することは、リスクの軽減に寄与します。私の経験からも、小さな変更ほど管理が容易であり、予期せぬ問題への対応も迅速になるということが証明されています。このアプローチは、大規模な変更を小分けにして取り組むことで、変更の複雑性とリスクを管理するのに有効です。
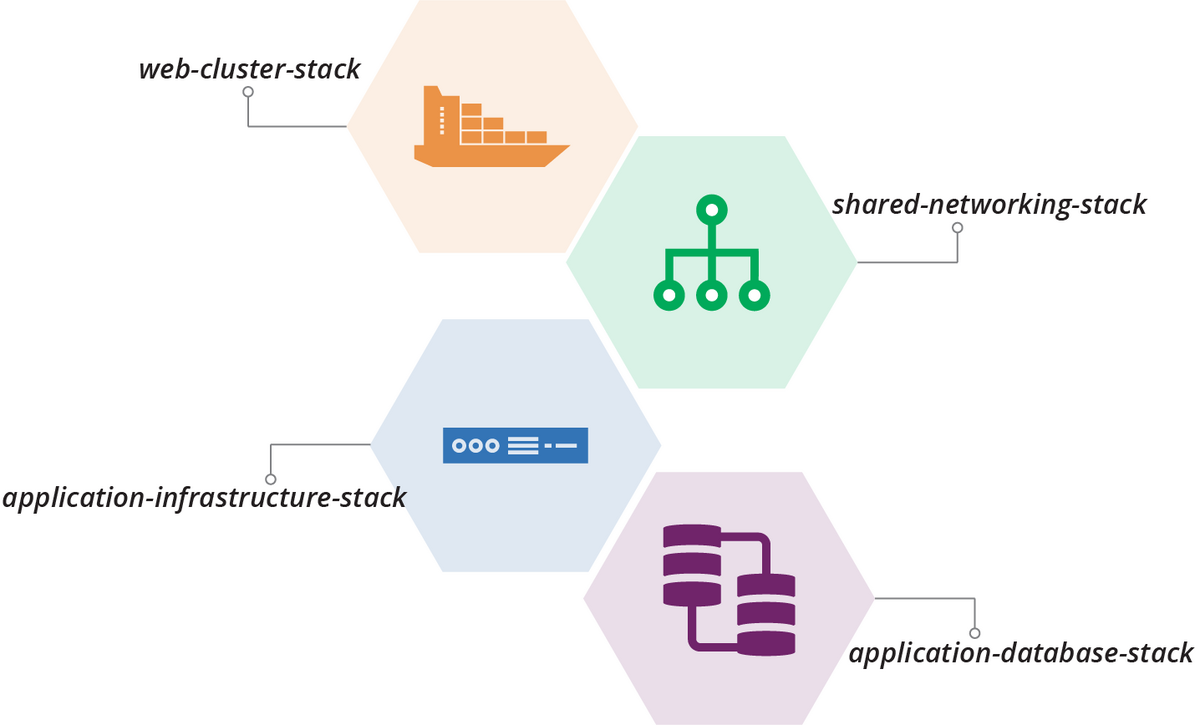 Figure 21-2. Plan to split out multiple stacks
Figure 21-2. Plan to split out multiple stacks
Small Changes
小さな変更を積極的に行うことの利点は、私のプロジェクト経験で明らかです。バッチサイズを小さくすることで、リスクを最小限に抑え、より迅速なフィードバックを得ることが可能になります。これは特に複雑なシステムにおいて、問題の特定と修正を容易にします。小さな変更は、大きなリリースの複雑さを減らし、より継続的なデリバリーを可能にします。
Example of Refactoring
リファクタリングの例は、コードベースを改善し、将来の変更を容易にするための重要な手段です。実際、私の経験では、リファクタリングはしばしば次のステップへの道を開くための重要なプロセスであり、これによりコードの保守性と拡張性が向上します。リファクタリングは、既存の機能を維持しつつ、コードの構造を改善することで、新しい機能の追加や将来的な変更を容易にします。
Pushing Incomplete Changes to Production
不完全な変更を本番環境に押し出すことは、段階的なデプロイメントの一環として重要です。この戦略は、変更の影響を小さく保ちながらも、継続的な進化を促進します。特に、リリース前のテスト段階でのフィードバックを得るために役立ちます。
Parallel Instances
並行インスタンスの概念は、本番環境でのリスクを軽減する上で非常に効果的です。これにより、新しい変更を既存のシステムと並行してテストし、徐々に本番環境に移行することが可能になります。これは、特に大規模なシステムや重要な機能の更新において、ダウンタイムを避けるための重要な戦略です。
Backward Compatible Transformations
後方互換性を持つ変更は、サービスの中断を防ぎつつ進化を遂げるための鍵です。このアプローチにより、既存の機能を維持しつつ、新しい機能や改善を段階的に導入することができます。これは、システムの安定性を保ちながらも、進歩と成長を促すために非常に効果的です。
Feature Toggles
機能トグルは、新旧の機能を柔軟に管理できる強力なツールです。これにより、新しい機能を段階的に導入し、必要に応じて迅速に変更を反映することができます。段階的なデプロイメントやA/Bテストにおいてこの技術は特に有効で、リスクを最小限に抑えつつ、ユーザーの反応を評価することができます。
Changing Live Infrastructure
ライブインフラの変更は、サービスの中断を最小限に抑えながらインフラを最新の状態に保つために不可欠です。このセクションでは、インフラストラクチャーの更新がサービスの連続性に与える影響を最小限に抑えるための技術と戦略が紹介されています。
Infrastructure Surgery
インフラの手術は、既存のインフラを修正しつつサービスを維持するための洗練された方法です。これにより、サービスの中断を最小限に抑えながら、重要なインフラの変更や改善を行うことができます。このアプローチは、特にデータ損失のリスクを最小限に抑えたい場合や、既存のシステムを段階的に改善したい場合に有効です。
Expand and Contract
拡張と収縮のパターンは、インフラの柔軟性を最大限に活用する素晴らしい方法です。このアプローチは、リソースの効率的な利用とスケーラビリティの向上に寄与します。特にクラウド環境において、この手法を利用することで、リソースの迅速な拡張と収縮が可能になり、需要の変動に応じたスケーリングが実現できます。
Zero Downtime Changes
ダウンタイムのない変更は、ユーザーエクスペリエンスを維持しつつ、システムのアップデートを行う上で非常に重要です。これにより、サービスの中断を防ぎつつ、新しい機能や修正を順次適用することができます。この手法は、特にユーザーへの影響を最小限に抑えたい場合に有効です。
Continuity
継続性は、変更管理における中心的な考え方です。エラーを防ぐことによる継続性、速やかな回復による継続性、継続的な災害復旧、カオスエンジニアリング、そして失敗計画は、システムの安定性と耐久性を確保するために重要な要素です。これらのアプローチは、リスクを軽減し、システムの回復力を高めるのに役立ちます。
Continuity by Preventing Errors
エラーを予防することによる継続性は、事前の計画と迅速な回復のバランスを取ることが重要です。このアプローチにより、システムの安定性を維持しながら、予期せぬ問題に迅速に対応することが可能になります。エラーの予防と迅速な修正は、特に大規模なシステムにおいて、サービスの連続性と信頼性を確保するために不可欠です。
Continuity by Fast Recovery
速やかな回復による継続性は、現代のインフラにおいて不可欠な要素です。システムの迅速な回復は、特に予期せぬ障害やエラーが発生した場合に、サービスの中断を最小限に抑えるために重要です。これは、特にビジネスクリティカルなアプリケーションやサービスにおいて、信頼性と利用可能性を確保するための鍵となります。
Continuous Disaster Recovery
継続的な災害復旧は、システムの耐障害性を高め、ビジネスの継続性を保証するために不可欠です。このアプローチは、システムの変更に関連するリスクを管理し、不測の事態が発生した場合に迅速に対応できるようにすることが重要です。私の経験では、継続的な災害復旧の計画と実施は、組織の全体的なリスク管理戦略の核心部分を形成します。これにより、システムが予期せぬ障害にも迅速に対応し、サービスの継続性を維持できるようになります。システムのバックアップと復旧プロセスを定期的にテストし、改善することで、災害発生時のリカバリー時間を短縮し、ビジネスへの影響を最小限に抑えることが可能です。
Chaos Engineering
カオスエンジニアリングは、システムの弱点を明らかにし、それらを改善するための実践的なアプローチです。この手法は、システムの耐障害性を試験し、実際の環境での挙動を理解するのに非常に有効です。私のキャリアの中で、カオスエンジニアリングはシステムの弱点を早期に特定し、それに対処する機会を提供する重要なツールとなっています。意図的に障害を引き起こすことで、システムの回復力をテストし、実際の災害時に備えることができます。このようなプラクティスにより、システムの安定性と信頼性が向上し、ユーザー体験の質が保たれます。
Planning for Failure
失敗計画は、システムの回復力を高めるために重要です。失敗を計画することは、システムの弱点を特定し、それらに対応するための戦略を立てることを意味します。私が経験したプロジェクトでは、様々な失敗シナリオを想定し、それぞれに対する回復計画を策定することが、システムの全体的な堅牢性を高める上で非常に重要でした。失敗計画は、リスクの評価と緩和策の策定を通じて、システムの安全性と効率性を保証します。また、失敗に迅速かつ効果的に対応するための準備とプロセスを確立することで、ビジネスの中断を最小限に抑えることができます。
Data Continuity in a Changing System
データの連続性は、変更のあるシステムにおいて最も重要な側面の一つです。私の経験では、データの安全性と一貫性を維持することは、サービスの品質と顧客信頼の基盤となります。
Lock
ロック機能は、特定のリソースを変更から保護する効果的な方法です。しかし、自動化と手動の介入のバランスを見極めることが重要です。過度に手動の介入に依存することはリスクを高める可能性があります。
Segregate
データを他のシステムコンポーネントから分離することにより、より柔軟かつ安全に変更を行うことが可能になります。このアプローチは、データを中心としたアーキテクチャ設計において特に有効です。
Replicate
データの複製は、可用性と耐障害性の向上に寄与します。分散型データベースのようなシステムでは、データの複製が自動化されることが多く、このプロセスはデータの保護に不可欠です。
Reload
データの再ロードやバックアップは、データ損失を防ぐ上で基本的です。バックアップと復元のプロセスを自動化することで、データの信頼性とアクセス性が大幅に向上します。
Mixing Data Continuity Approaches
データの継続性を確保する最善の方法は、分離、複製、再ロードの組み合わせです。この複合的なアプローチにより、データの安全性とアクセス性の両方を最大化できます。データの継続性は、単一の手法に依存するのではなく、複数の手法をバランスよく組み合わせることで、最も効果的に実現されます。
この章の締めくくりでは、インフラ変更におけるデータの継続性の重要性が強調されています。クラウド時代におけるインフラ管理の進化に伴い、速度と品質のバランスを取りながらも、データの安全性を維持することの重要性が明確にされています。データはビジネスの中心にあり、その連続性と安全性を確保することが、サービスの品質と顧客信頼を維持するための鍵であることが再確認されます。
総括 Infrastructure as Code, 2nd Edition の読書感想文
『Infrastructure as Code, 2nd Edition』は、現代のITインフラストラクチャ管理の進化に対応するための重要なガイドです。この書籍は、インフラストラクチャをコードとして扱うことの重要性と、それを実現するための具体的な方法を体系的に説明しています。
第一部では、インフラストラクチャをコードとして管理する基本原則に焦点を当て、クラウド時代のダイナミクスを解説しています。特に、変更の速度を利用してリスクを減らし、品質を向上させる新しいマインドセットの必要性が強調されています。
第二部では、インフラストラクチャスタックの構築と管理に関して詳述し、スタックの構築、環境の設定、および継続的なテストと提供の重要性について論じています。ここでは、インフラストラクチャの自動化におけるスタックの重要性を明確にし、技術的な洞察と実践的な指針を提供します。
第三部は、サーバーと他のアプリケーションランタイムプラットフォームとの作業に注目し、アプリケーションランタイム、サーバーのコード化、サーバーへの変更管理などを取り上げています。この部分は、アプリケーション主導のインフラストラクチャ戦略を通じて、現代の動的インフラを使用してアプリケーションランタイム環境を構築する方法に重点を置いています。
第四部では、インフラストラクチャの設計に関して、小さく単純な部品の使用、モジュラリティ、コンポーネント設計のルール、モジュール化、およびスタックコンポーネントの設計パターンとアンチパターンについて論じています。このセクションは、効率的で持続可能なインフラストラクチャを設計するための具体的な方法とベストプラクティスを提供します。
第五部では、インフラストラクチャコードの整理、提供、チームワークフロー、およびインフラストラクチャの安全な変更に焦点を当てています。インフラストラクチャコードの整理と管理、デリバリープロセス、プロジェクトの統合、および安全な変更の方法に関する洞察が提供されています。
全体として、この書籍は、インフラストラクチャとしてのコードの採用と適用において、技術者や専門家に重要な洞察と価値ある情報を提供し、インフラストラクチャ管理の現代的なアプローチを実現するための実践的なガイドとなっています。その詳細な解説と実用的なアドバイスは、この分野で働く専門家にとって非常に役立つものです。
Infrastructure as Code, 2nd Editionの読書感想文
- Infrastructure as Code, 2nd Edition の I. Foundations 読書感想文 - じゃあ、おうちで学べる
- Infrastructure as Code, 2nd Edition のII. Working With Infrastructure Stacks 読書感想文 - じゃあ、おうちで学べる
- Infrastructure as Code, 2nd Edition の III. Working With Servers And Other Application Runtime Platforms 読書感想文 - じゃあ、おうちで学べる
- Infrastructure as Code, 2nd Edition のIV. Designing Infrastructure 読書感想文 - じゃあ、おうちで学べる
- Infrastructure as Code, 2nd Edition のV. Delivering Infrastructure 読書感想文 - じゃあ、おうちで学べる